做水果的网站有哪些个人可以注册企业邮箱吗
又是一年高考时,祝各位学子金榜题名,天遂人愿!
在您阅读以下内容时,请注意:各省查分API接口可能不相同,本人仅就技术层面谈谈, 纯属无聊,因为实用意义不大,毕竟一年一次,查询接口可能每年都变!!!
在每年高考成绩公布前夜,人们通常会守候在电脑前查询成绩。但实际上,若了解了查询接口,就能利用爬虫自动获取成绩,并通过微信推送接口(Server酱),将信息直接发送至微信。
要定时查询一个学生的高考分数并将结果推送到微信上,可以按照以下步骤进行:
步骤一:导入所需的库
首先,我们导入需要使用的 Python 库,包括 requests、schedule 和 time。
import requestsimport scheduleimport time步骤二:定义 ping_website 函数
编写一个函数 ping_website(url) 来检查网站状态码是否为 200。如果状态码不是 200,则等待10秒后重新尝试。
def ping_website(url):response = requests.head(url)return response.status_code步骤三:定义 crawl_data_and_send_to_wechat 函数
创建一个函数 crawl_data_and_send_to_wechat(),在其中执行数据爬取并调用 Server酱接口将数据推送到微信。
def crawl_data_and_send_to_wechat():website_url = "查询分数的API接口"while ping_website(website_url) != 200:print("查询接口还没有开放. 等待10秒钟后再试...")time.sleep(10)# 数据爬取逻辑print("爬取分数...")# 模拟爬取的数据crawled_data = "结果示例"# 使用Server酱推送消息至微信server_chan_url = "https://sc.ftqq.com/YOUR_SERVER_CHAN_KEY.send"requests.get(server_chan_url, params={"text": "Crawled Data", "desp": crawled_data})print("数据已通过Server酱发送到微信上!!!")步骤四:定义 job 函数
创建一个 job() 函数,在其中调用 crawl_data_and_send_to_wechat() 函数。
def job():crawl_data_and_send_to_wechat()步骤五:设置定时任务
使用 schedule 库来设置每分钟执行一次的任务,并在主循环中运行定时任务。
# 设置每分钟执行一次任务schedule.every().minute.do(job)while True:schedule.run_pending()time.sleep(1)以下是某省2023年高考成绩查询的接口演示
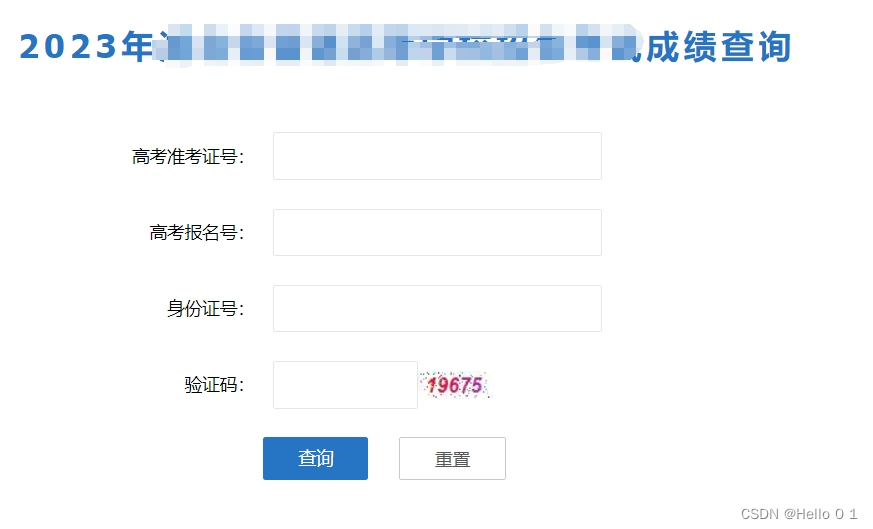
某省2023年高考查分界面
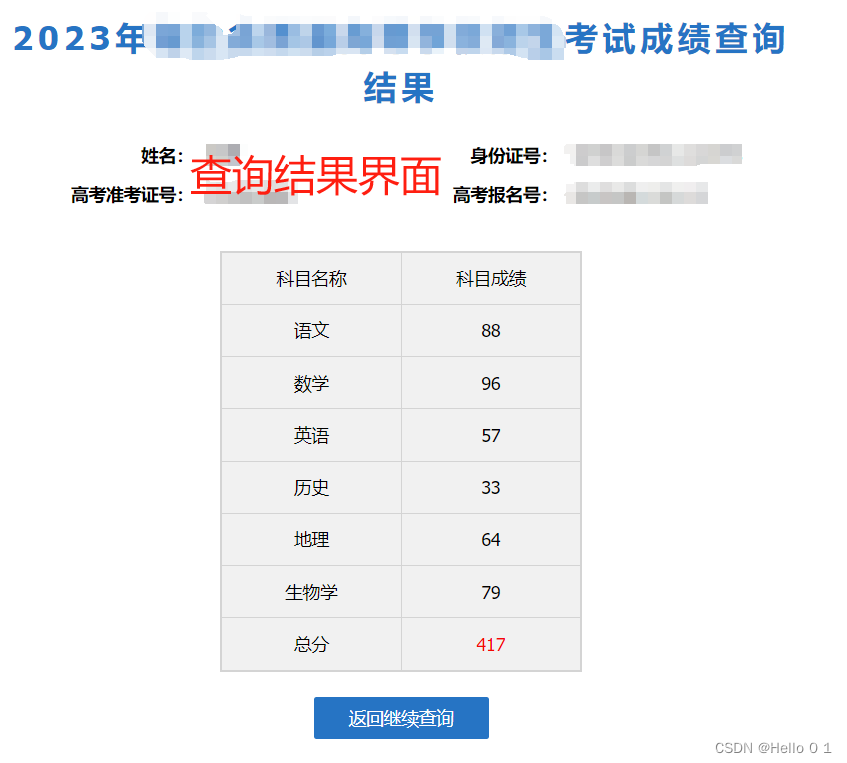 最后结果界面
最后结果界面
查询响应是一个table, 以下敏感信息已用x替代。
<div class="gkcj-tit">2023年xxxxx省普通高等学校招生考试成绩查询结果</div>
<div class="base-info b1"><table class="base-t"><tr><td class="base-td">姓名:</td><td style="width: 168px;">xxxxxx</td><td class="base-td">身份证号:</td><td>xxxxxxxxxxxxxxxxxxxxxxxx</td></tr><tr><td class="base-td">高考准考证号:</td><td>xxxxxxxxxx</td><td class="base-td">高考报名号:</td><td>xxxxxxxxxx</td></tr></table>
</div>
<div class="score-info"><table class="score-t"><tr><td>科目名称</td><td>科目成绩</td></tr><tr><td>语文</td><td>xxx</td></tr><tr><td>数学</td><td>xxx</td></tr><tr><td>英语</td><td>xxx</td></tr><tr><td>历史</td><td>xxx</td></tr><tr><td>地理</td><td>xxx</td></tr><tr><td>生物学</td><td>xxx</td></tr><tr><td>总分</td><td class="score-tcolor">xxx</td></tr></table>
</div>
<div class="fh"><a onclick="back();" href="javascript:void(0);" class="gkcj-btn">返回继续查询</a>
</div>
以下程序仅给出了数据查询的程序,读者可以根据前面的步骤,将数据查询作为一个job, 将能查询到的结果推送到微信上。
在以下程序中主要注意以下几个问题:
1、创建同一个会话
2、验证码识别
这里对于验证码识别没有做异常处理,有时验证码识别可能错误,需重新访问网页获取。
import ddddocr
import requests
from bs4 import BeautifulSoup# 创建一个会话对象
# 要在一个会话中获取网页的源码提取__RequestVerificationToken的值,
# 同时通过接口http://查询成绩服务器IP/Validate/GetValidateCode?获取验证码session = requests.Session()# 请求网页获取源码
url = "http://查询成绩服务器IP/gk/gkcj2023?token=98c1234e8d5678bb"
response = session.get(url)
html_content = response.text# 使用BeautifulSoup解析网页源代码
soup = BeautifulSoup(html_content, 'html.parser')
# 从网页源代码中提取到__RequestVerificationToken的值
input_tag = soup.find('input', {'name': '__RequestVerificationToken'})
verification_token = input_tag['value']
print(verification_token)# 从网页源代码中提取验证码图片URL
validate_code_url = "http://查询成绩服务器IP/Validate/GetValidateCode?"for img in soup.find_all('img'):if "ValidateCode" in img['src']:validate_code_url += img['src']break# 获取验证码图片
response = session.get(validate_code_url, stream=True)
if response.status_code == 200:with open('captcha_image.png', 'wb') as out_file:for chunk in response.iter_content(chunk_size=128):out_file.write(chunk)# 打印验证码图片保存成功消息
print("验证码图片已保存为 captcha_image.png 文件")# 识别验证码
def imgRecognition(img):try:ocr = ddddocr.DdddOcr()with open(img, 'rb') as f:img_bytes = f.read()res = ocr.classification(img_bytes)return resexcept:return NonerandCode = imgRecognition('captcha_image.png')headers = {"Accept": "image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8","Accept-Language": "zh-CN,zh;q=0.9","Cache-Control": "no-cache","Content-Type": "application/x-www-form-urlencoded; charset=UTF-8","DNT": "1","Origin": "http://查询成绩服务器IP","Pragma": "no-cache","Proxy-Connection": "keep-alive","Referer": "http://查询成绩服务器IP/gk/gkcj2023?token=98c1234e8d5678bb","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36","X-Requested-With": "XMLHttpRequest"
}
cookies = {"__RequestVerificationToken_Lw__": "lcVcsxDb0RiSVf1wSZeQxzeD9WZ7+y4lBW7+5DkJmLDpT5hiTaxPXlpokbYfDTcEL3ujpDdB9qEezLBdnNZy/C8dYe9o9pJLTUqWeOnAmVWio0bRwhEkNK/jKbQLSE3T2t4rfg==","ValidateCode": randCode
}
url = "http://查询成绩服务器IP/gk/gkcj2023" # 成绩查询接口
data = {"zkzh": "xxxxxxxxx", # 准考证号"ksbh": "", # 报名号"zjhm": "xxxxxxxxx", # 身份证"yzm": randCode, # 验证码"__RequestVerificationToken": verification_token # 从网页中获取的值
}
response = session.post(url, headers=headers, cookies=cookies, data=data, verify=False)# 使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')# 提取表格数据
table_data = []
for table in soup.find_all('table'):for row in table.find_all('tr'):cols = row.find_all(['td'])cols = [ele.text.strip() for ele in cols]table_data.append(cols)# 保存提取的表格数据到.txt文件
with open("高考成绩.txt", "w") as file:for row in table_data:file.write('\t'.join(row) + '\n')print("表格数据已保存为 高考成绩.txt 文件")
最后查询结果:
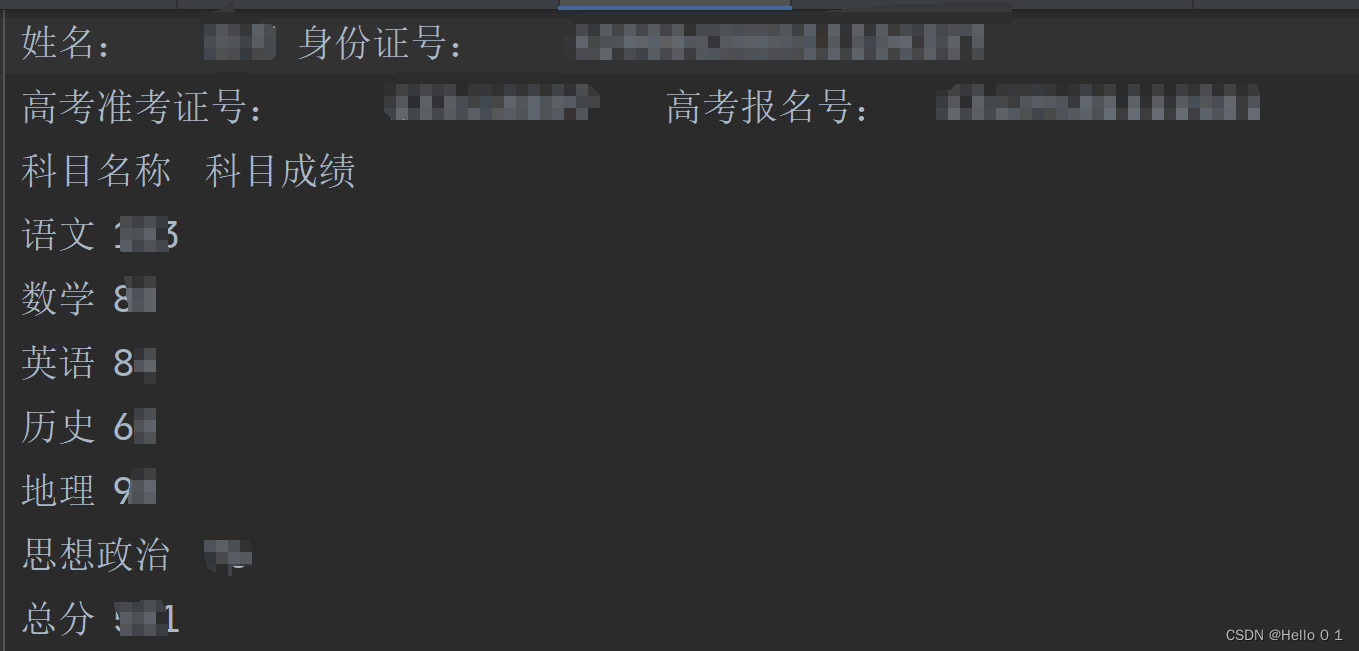 各高考查分接口,为保障查询速度,一般仅采取了简单的反爬措施,所以获取结果不是很困难!
各高考查分接口,为保障查询速度,一般仅采取了简单的反爬措施,所以获取结果不是很困难!