网站图片链接是怎么做的广州网络营销运营
原项目链接
Java爬虫抓取豆瓣图书信息
本地运行
运行过程
另建项目,把四个源代码文件拷贝到自己的包下面

在代码爆红处按ALT+ENTER自动导入maven依赖

直接运行Main.main方法,启动项目

运行结果
在本地磁盘上生成三个xml文件

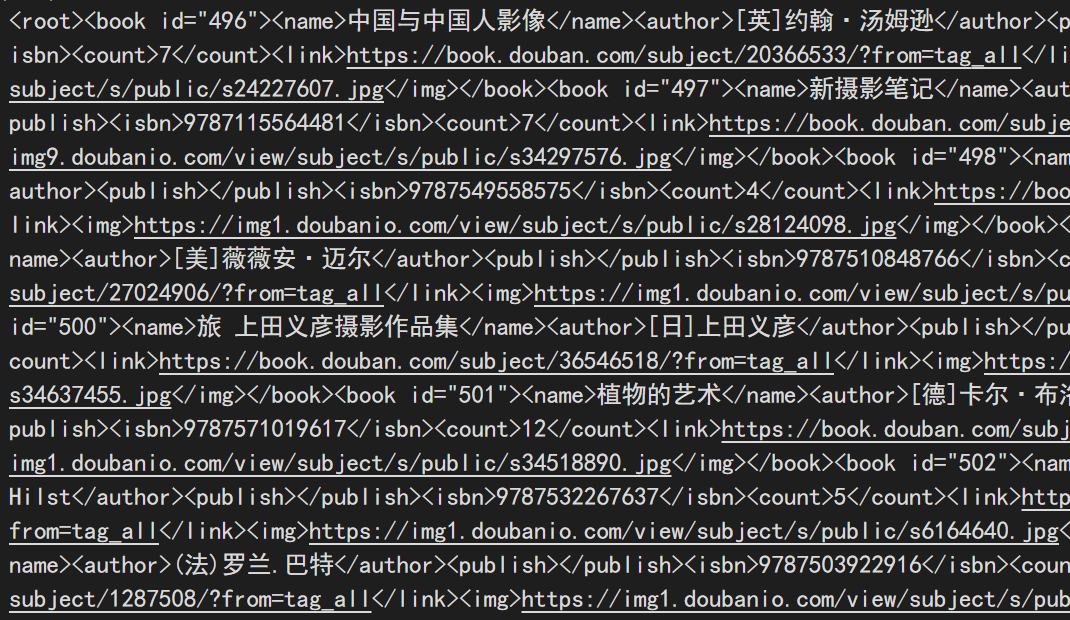
其中的内容即位爬取后到的图书信息,包括:
- 书名
- 作者名
- 出版社名
- isbn号
- 图书对应的豆瓣链接
- 图书封面图片地址
可惜并没有直接爬取到图书的内容,不过可以凭借爬取得到的图书元数据去其他网站获取电子版pdf
项目运行逻辑
- 使用apache提供的httpclient工具包,手动创建一个http客户端
- 使用该http客户端向豆瓣官网发送GET请求
- 获取response相应数据,类型为html页面
- 使用正则表达式工具匹配得到的html页面中有关图书信息的项
- 利用dom4j库将这些图书信息项转换成xml元素并存储到本地
收获
CloseableHttpClient接口
该接口代表一个http客户端,实现类可以是InternalHttpClient
创建一个默认http客户端
创建一个不使用代理的默认客户端,使用如下代码
CloseableHttpClient httpClient = HttpClients.createDefault();
创建一个使用代理的http客户端
CloseableHttpClient httpClient = HttpClients.custom().setProxy(new HttpHost(ip,port)).build();
上述代码可以拆解为
//新建一个完全默认的HttpClientBuilder
HttpClientBuilder hb = HttpClients.custom();
//为该HttpClientBuilder设置代理,setProxy方法修改当前hb的代理属性后,返回this自身
hb = hb.setProxy(new HttpHost(ip,port));
//调用build方法完成http客户端的构造
CloseableHttpClient httpClient = hb.build();
关于Java程序内设置的代理与操作系统设置的全局代理的关系,在这篇文章中有更详细的说明【Java程序代理与系统代理关系】
多个重复任务使用多线程解决
List<Thread> threadList = new LinkedList<Thread>();
while (...) {threadList.add(new AClassExtendsThread(...));
}
for (Thread thread:threadList) {thread.start();
}
for (Thread thread:threadList) {try {thread.join();} catch (InterruptedException e) {e.printStackTrace();}
}
使用dom4j写入xml文件
Writer fileWriter;
Element root;//xml根标签,内含要写入的所有信息,这些信息通过其他代码已经存入root中
String fileAddress;
try {fileWriter = new FileWriter(fileAddress);XMLWriter xmlWriter = new XMLWriter(fileWriter);xmlWriter.write(root);xmlWriter.close();System.out.println("[" + fileAddress + "]写入成功");
} catch (IOException e) {e.printStackTrace();
}
正则表达式匹配
String regex;//正则表达式
Pattern xxxRegex = Pattern.compile(regex);
m = xxxRegex.matcher(entityString);
while (m.find()) {//执行对应操作
}
dom4j标签操作
Element为元素类,或标签类
Document newDocument = DocumentHelper.createDocument();
Element rootElement = newDocument.addElement("root");
添加属性代码
bookElement.addAttribute("id","attribute");
添加子标签代码
bookElement.addElement("name").setText(bookName);