做营销网站设计目前搜索引擎排名

“流线”与“功能”
以“外文词典”程序设计为例
一、题目及引入
[制作外文字典]
(第十周实验)词典有3个基本功能:添加,查询和退出。程序读取源文件路径下的“我的词典.txt”文件,若没有就创建一个。程序根据用户的选择进入相应的模块,并显示相应的操作提示。当添加的单词已经存在时,把新输入的中文作为新的释义(即允许多重释义)。当查询的单词不存在时,要提示“词典库没有该单词”。用户输入其它选项,提示“输入错误”

编写时需注意的四个小问题:
①每个功能写一个函数(显示操作菜单,增加单词,查询单词,保存词典,读入词典)
②增加单词和查询单词,不能读写文件
③只允许在函数内打开关闭文件
④再次运行要把上次保存的内容读入
看来提示①给大问题的第一次分解指明了光明道路。不妨就按照之前的建议去做,依次解决五个小问题并进行调试工作。一路做下来,每一步都是脚踏实地的快乐,每次调试都有满满的成就感。好的,我们把它们组合在一起……

嗯,还需要做一点点小改动。接着就是牵一发而动全身的重开……

每一个函数的功能都考虑清楚了,但是各个功能区之间的关系还需要进一步明确,这里需要一条清晰的“流线”,即数据“储存”与“运输”的路径
不妨从用户的角度考虑,梳理这几个功能的关系。需要明确的是,这里有一个循环,只有用户输入“3”的时候才能跳出循环
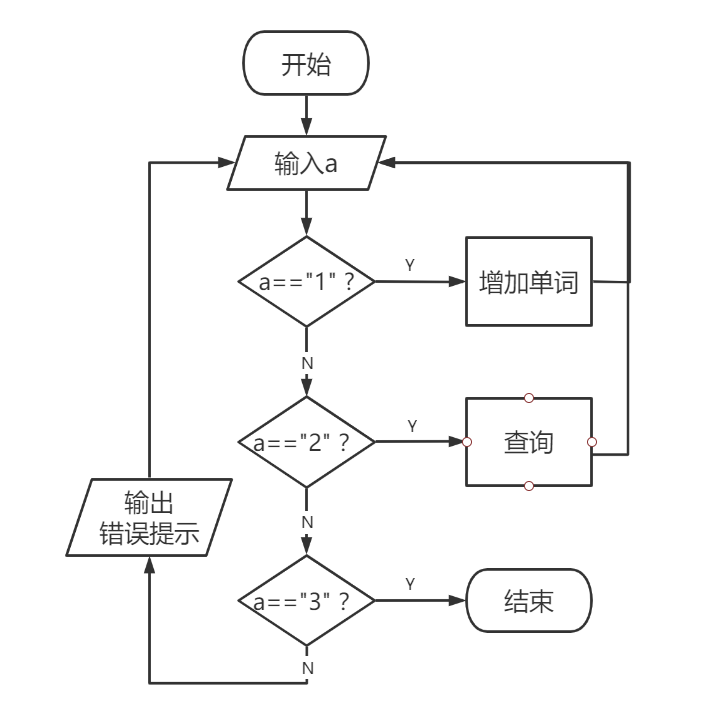
二、数据的流转与存储
数据在文本文件和python之间流转与储存,会涉及到数据储存样式、安排数据流转时间点等问题。
Ⅰ
在文本文件里面各种数据要用什么样式储存?
在python中,数据能以字符串、数字、列表、字典、元组、集合等形式储存
但在文本文件中,数据只能以文本形式储存
文本文件数据与python如何轻松对接?不妨考虑以下问题:
1
为了减少麻烦,我们可以将储存的外文统一转换成小写模式
2
如果直接将python中的字典数据
dic={“Roystonea regia”:[“大王椰子”,”王棕”] }
直接存入文本文件,那么大量特殊符号将以文本类型储存在文本文件中
3
如果直接采取这种储存样式,下一次用python读取文本文件数据时,如果不使用json库,特殊符号会以字符串形式读入python,将大量字符串重新处理成字典会比较麻烦
所以在文本文件里面的数据需要有统一的符号和简单的样式。比如:
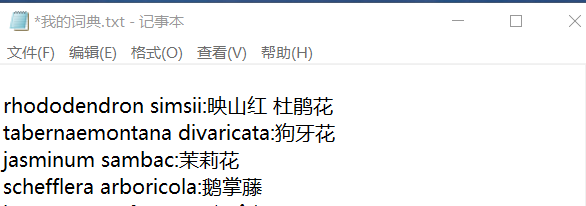
如果觉得既要处理空格又要处理冒号比较麻烦,我们还可以采取以下样式
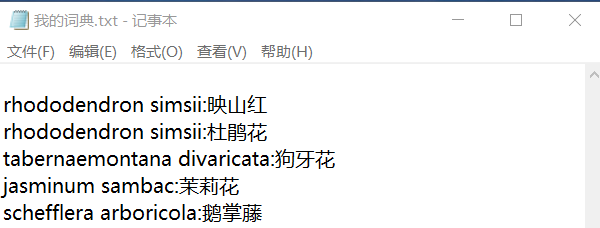
读入python时只需要对冒号切割处理,即可生成列表。

Ⅱ
文本文件的读取和写入应该安排在什么时候?
如何将大象放进冰箱里面?首先打开冰箱,然后把大象放进冰箱里面,接着关闭箱门
文本文件的处理也比较类似,就是打开—处理—关闭
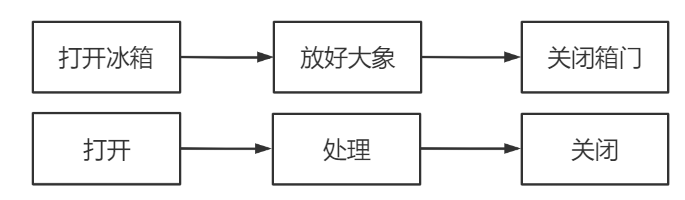
注意这里的“处理”包括很多方面的内容,比如读取和写入等等。为了讲清楚这个问题,我们不妨做一个类比
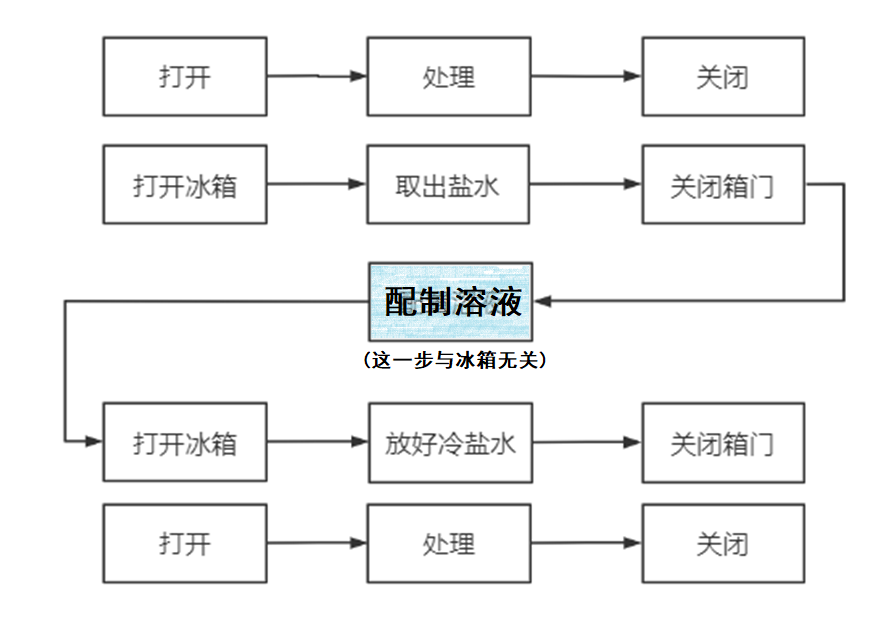
假设张三需要利用冰箱现有的冷水配置冷的盐水,他大致会经过这几个步骤:
①打开冰箱门②取出冷水③关闭冰箱门
④按照配置操作规范弄好冷盐水⑤打开冰箱门
⑥将冷盐水放进冰箱⑦关闭冰箱门
由此可以看到,这整个过程张三开了两次冰箱门,关了两次冰箱门
这里的步骤①⑤相当于“打开”,③⑦相当于“关闭”,②⑤相当于“处理”。④实际上与冰箱没有关系,因为在配置冷盐水的过程中没有任何必要对冰箱进行操作
在程序设计的时候,我们也要避免反复开关冰箱门
参考“张三七步配置冷盐水法”,
可以规划一条初步的数据传输流线:
①打开文本文件
②将文本文件的内容读入python的列表lis
③关闭文本文件
④用户各种操作,不论是增加外文单词还是查询,都只对lis进行处理,与文本文件无关
⑤打开文本文件
⑥将新的lis写入文本文件
⑦关闭文本文件
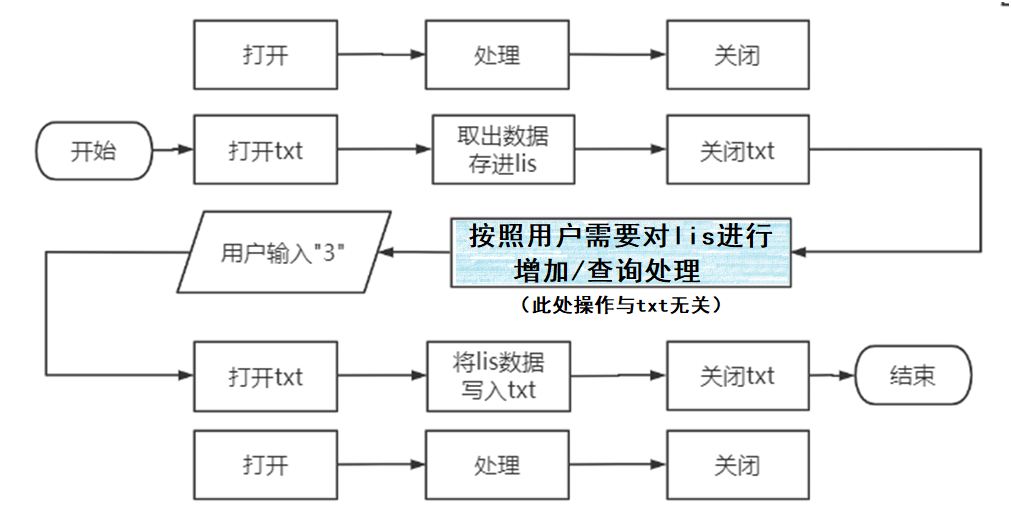
基本的框架已经出现了,我们需要进一步细化蓝色的部分。细化的依据大致就是从用户的角度出发置入增加和查询的流线
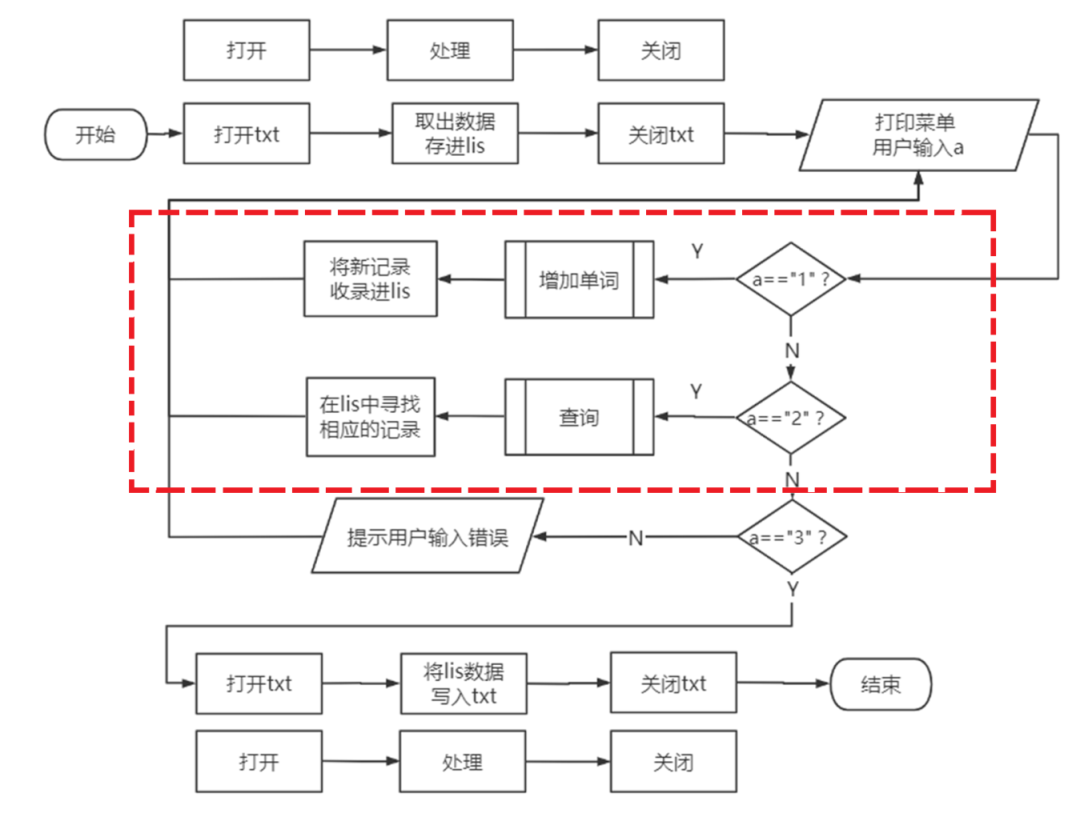
上面这个流线图里面隐隐约约出现了五个功能函数的位置(到现在我们一行代码也没有)
不好意思放错图了
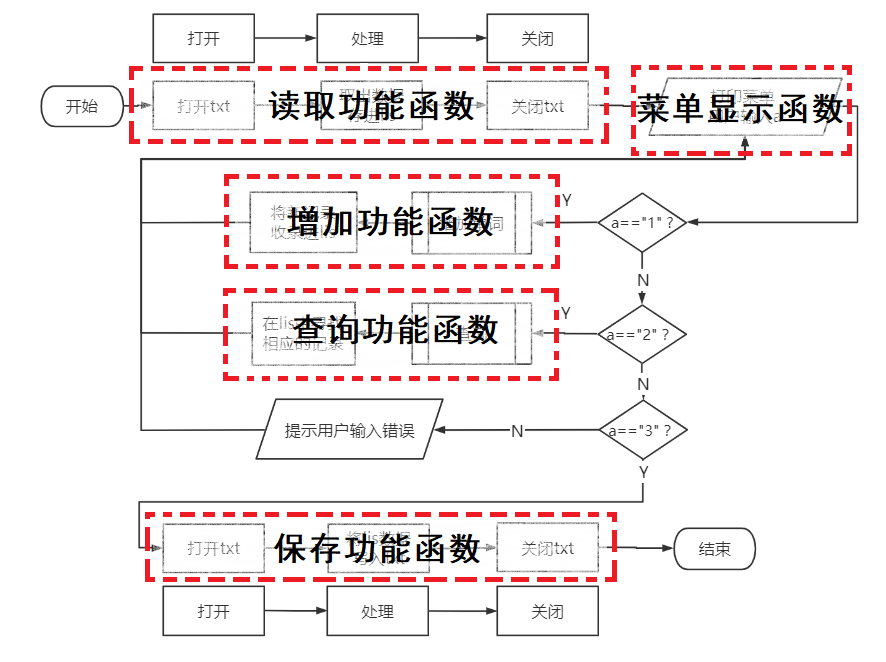
有功能布局与交通流线分析图的味道了
Ⅲ
如何利用好函数的变量和返回值?
例如,对于增加功能函数zengjia(),我们需要考虑这个函数在执行的时候会涉及哪些变量,比如列表lis,需要增加的外文单词jiaE,对应的解释jiaC。所以这个函数最好写成zengjia(jiaE,jiaC,lis)
至于返回值,如果增加的外文单词与对应的解释在原列表已经有记录,就需要告诉用户“已有记录”,如果添加成功,就需要告诉用户“添加成功”,所以可以让函数的返回值是一个字符串类型的变量ans,即
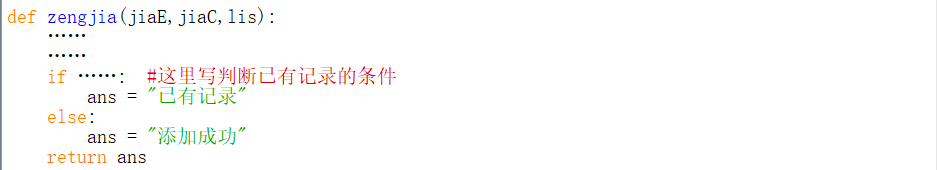
在主程序就可以这样调用:

同时,如果没有充足的把握,建议减少全局变量的使用
依据前面的讨论,
我们将函数的具体内容明确一下:
①读取函数duqu(),打开冰箱,提取txt中信
息并存入列表lis,关闭冰箱,最后返回lis
②显示操作菜单的函数caozuo(),仅用于打印
菜单文字
③用户输入“1”的时候调用
增加词条函数zengjia(jiaE,jiaC,lis),
将外文jiaE及其释义jiaC保存到列表lis里面,
返回提示字符串ans
④用户输入“2”的时候调用
查询函数cha(xun,lis),
用户输入外文xun,
在lis里面寻找对应的释义,
返回释义ans(也可能没有释义)
⑤用户输入“3”的时候调用
保存函数baocun(lis),
打开冰箱,放进列表,关闭冰箱,
跳出循环,结束运行
这个时候就可以开始给逐个功能敲代码了,首先搭建主体框架
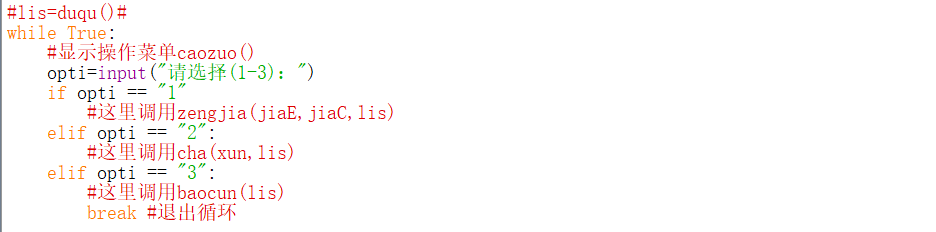
接着就是补充各个函数的功能,注意目前的主体框架中,
所有函数名都在注释内部,都不会执行,完成一个函数的代码之后再去掉该函数的注释符号,这样方便逐个调试
三、内部程序代码编写
接下来是字典程序的具体编写内容
Ⅰ
读取函数duqu()
文本文件中的数据保存样式如下:
那么读到python中,我们可以采取
列表套列表的方式作为数据保存样式:
lis=[[“Roystonea regia”,“大王椰子”],
[“Tabernaemontan adivaricata”,“狗牙花”],
[“Roystonea regia”,“王棕”]]
函数内部代码如下。
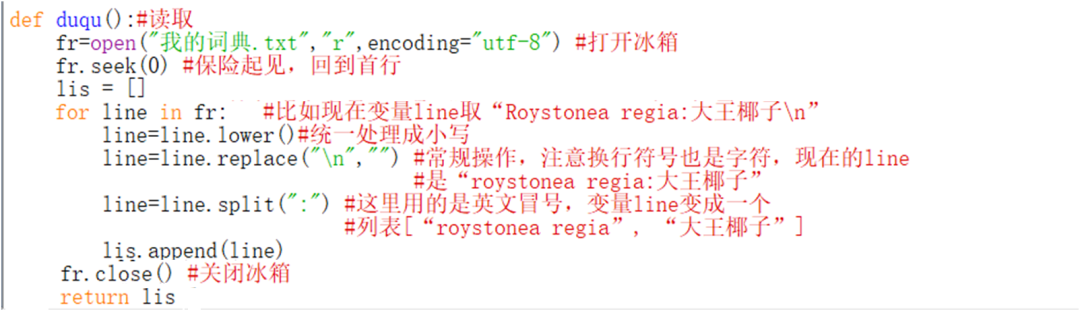
调试方法就是预先在文本文件按照样式写出部分数据,然后解除主程序lis=duqu()的注释符号,并在下一行添加print(lis),检查lis的结果
Ⅱ
显示操作菜单caozuo()
这个比较简单,不过还是调试一下

调试的时候,如果输入“1”或“2”之后再次出现操作菜单,输入其他字符显示“输入错误”和操作菜单,且输入“3”的时候可以退出,即调试完成
Ⅲ
增加词条函数zengjia(jiaE,jiaC,lis)
这里需要判断原来的列表lis内部有没有完全一样的记录,如果有,就无需添加,如果没有,就按照样式添加
具体方法就是先让变量you取0,将列表的每一个元素拿出来与新增词条对比,一旦发现相同记录,就让you变成1
接着就通过变量you的数值来决定是否添加词条,注意这里的词条是添加到列表lis里面的,并不是添加到文本文件里面
另外还需要注意一个问题,如果jiaE和jiaC本身带有英文冒号,储存到文本文件之后同一行可能会出现多个冒号,那么下一次再读取时,执行duqu()的line=line.split(":")会有麻烦,为了避免切割出两个以上的字符串,不妨将英文冒号替换成中文冒号

这个时候注意在主程序也要进行补充

同样地,这里可以通过添加print(lis)进行调试,确保新的词条已经存入列表lis里面
Ⅳ
查询函数cha(xun,lis)
这里还需要处理的问题就是如果列表lis没有记录,要告诉用户没有记录。不妨设默认回答ans是"词典里没有{}单词!".format(xun),如果在词典里面每发现一条记录(可能有多条记录),就更改ans的值

同样地,主程序也相应进行补充

这里的调试内容比较多,最好词典没有记录的外文、词典有一条记录的外文、词典有多条记录的外文都试一试
Ⅴ
保存函数baocun(lis)

主程序也进行更改,并跳出循环

这里主要检查一下新的记录有没有写进文本文件里面。现在五个功能都完成了,最后来一次调试吧!

之前明明都调试好的内容,最后关头来个报错还行……
看见红色字也不要害怕,可以看看其中的错误提示,想一下优化的办法
这里的意思是文本文件并不存在,所以无法读取。那我们就需要修改一下duqu(),将打开文件放在try的过程里,如果无法打开冰箱则在except内创建冰箱

再试一试,这里注意将创建的词典删除,重点排查能否自动创建词典,以及能否将原有内容读入lis

成功啦!

四、要点回顾
1
打开—处理—关闭
2
张三七步配置冷盐水法
3
数据存在文本文件中需要统一的符号和简单的样式
4
理清“数据流线”,排布“函数功能”
五、代码全文


END
-
文章 / 郭文轩
排版 / 马祎林 郭文轩
初审 / 林师伊
终审 / 申宏宇
-
