网站动画用什么程序做百度托管运营哪家好
1.xml
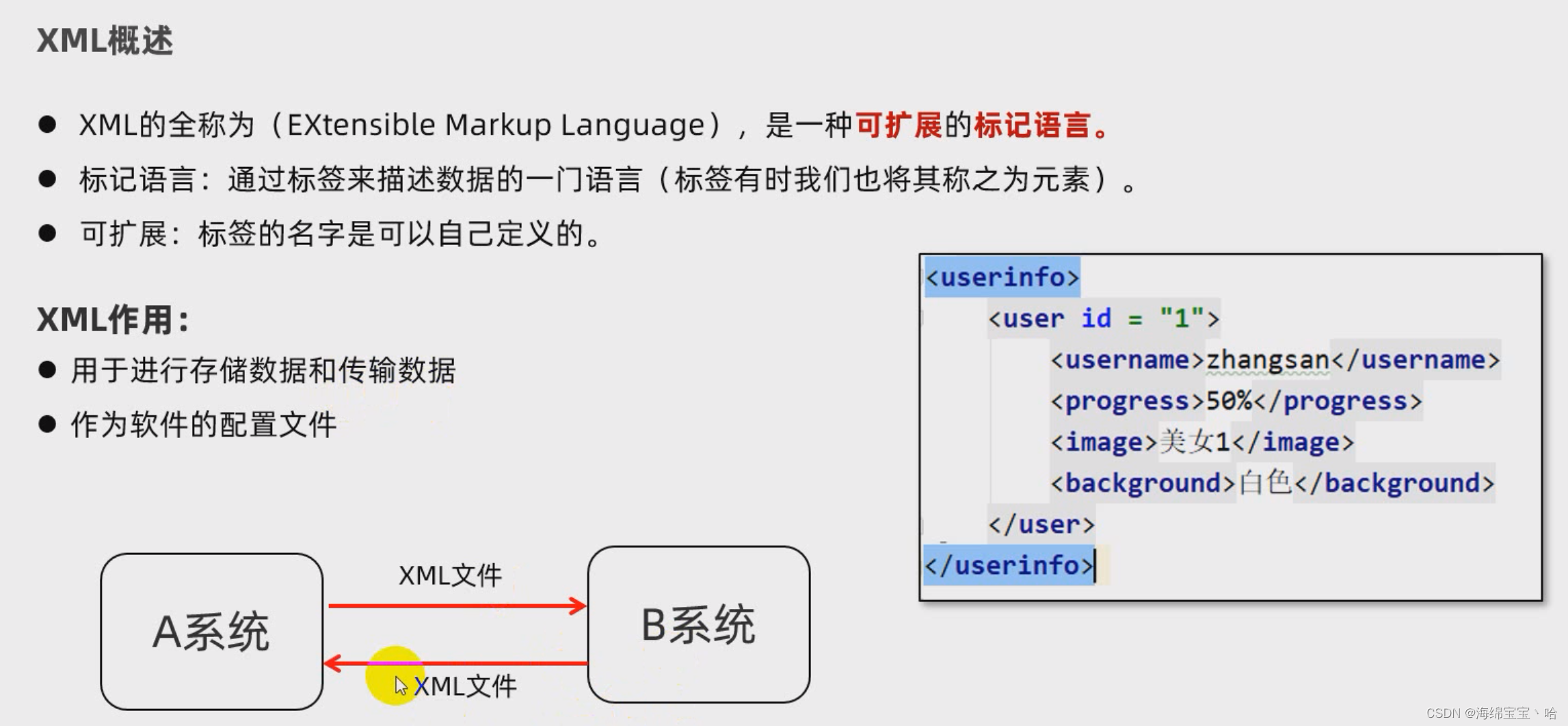
1.1概述【理解】




1.2语法规则【应用】




1.5DTD约束【理解】


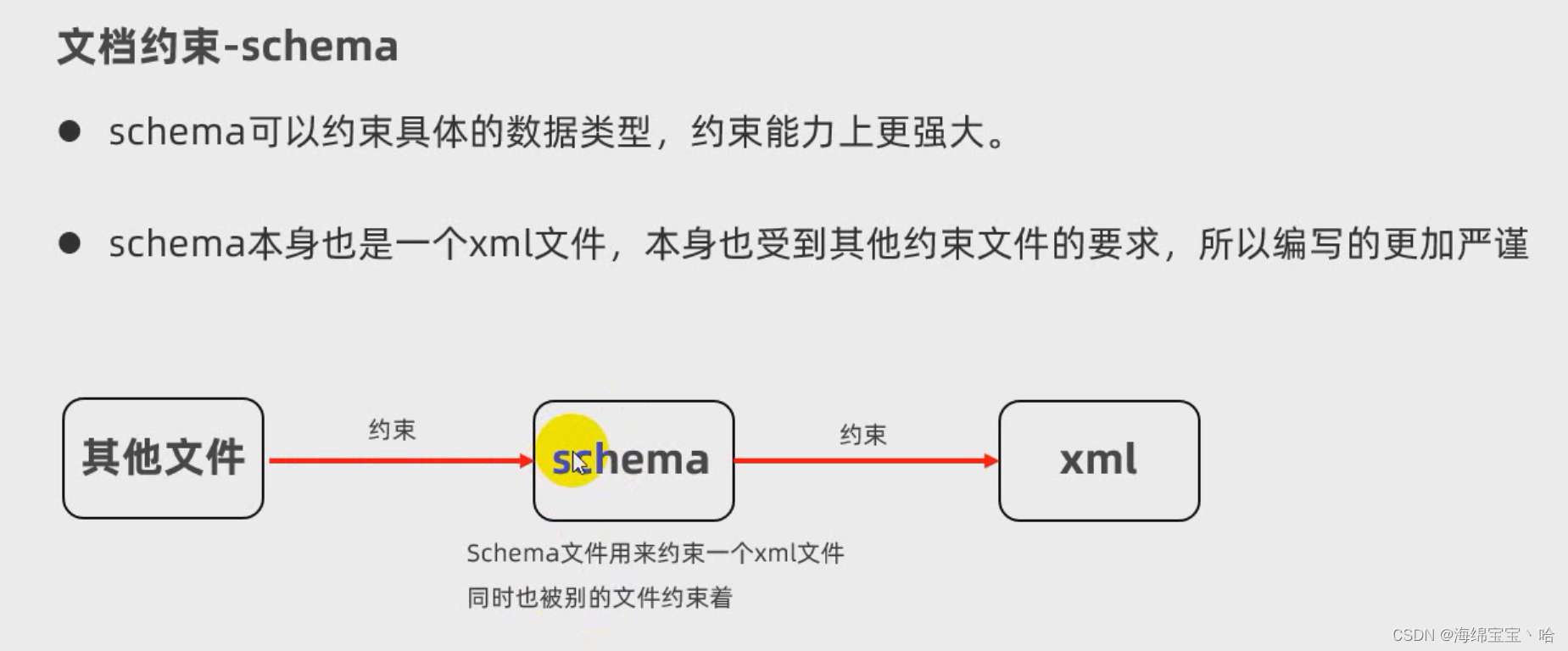
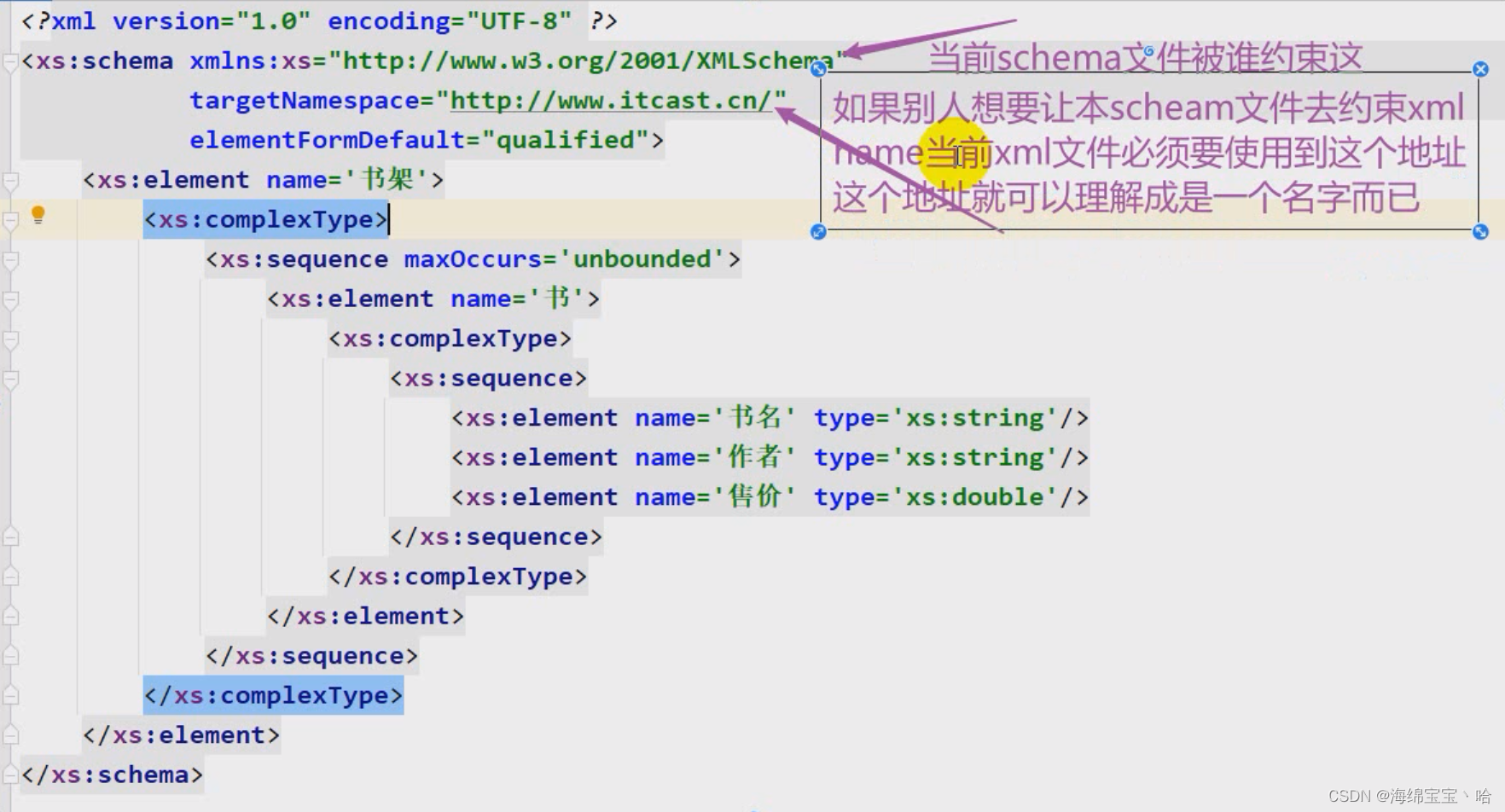
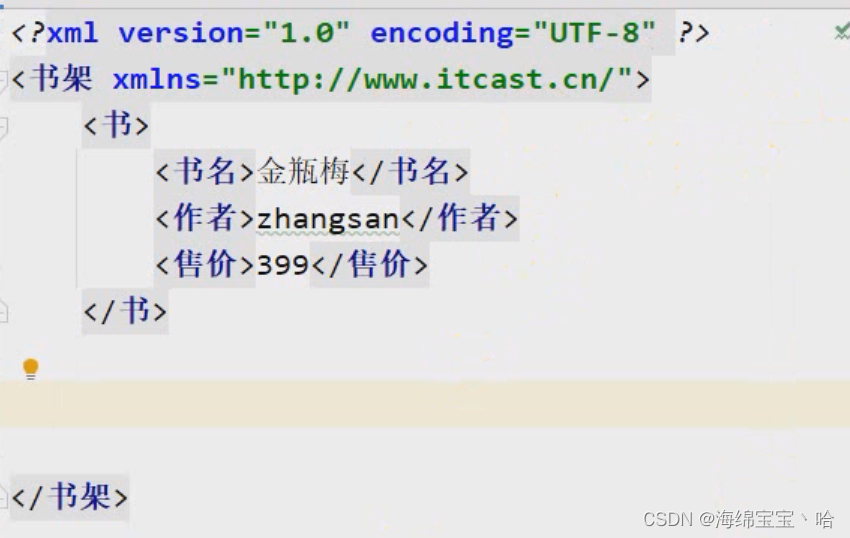
1.6schema约束【理解】

1.4xml解析【应用】


-
概述
xml解析就是从xml中获取到数据
-
常见的解析思想
DOM(Document Object Model)文档对象模型:就是把文档的各个组成部分看做成对应的对象。
会把xml文件全部加载到内存,在内存中形成一个树形结构,再获取对应的值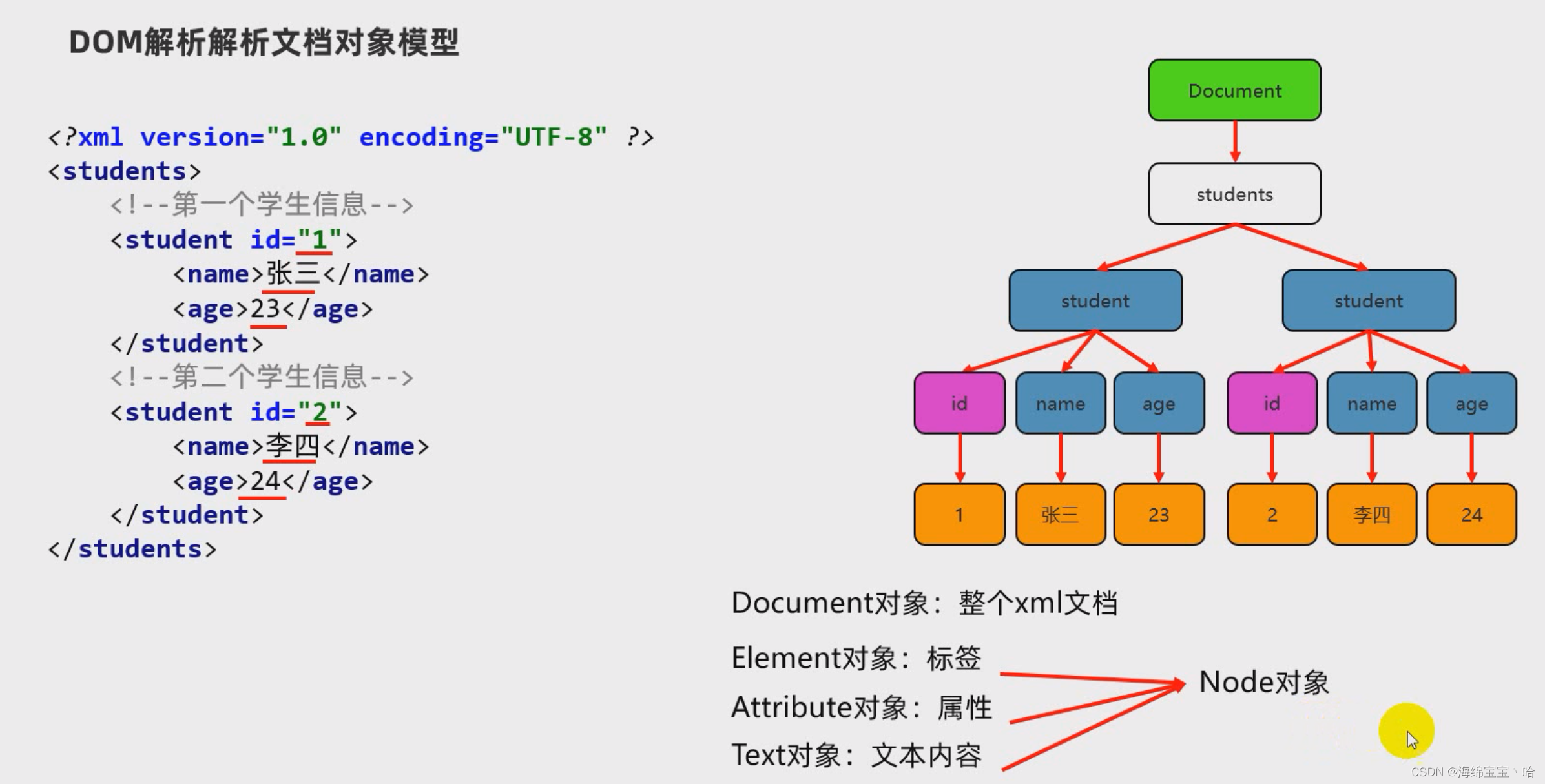
-
解析的准备工作
-
我们可以通过网站:https://dom4j.github.io/ 去下载dom4j
今天的资料中已经提供,我们不用再单独下载了,直接使用即可
-
将提供好的dom4j-1.6.1.zip解压,找到里面的dom4j-1.6.1.jar
-
在idea中当前模块下新建一个libs文件夹,将jar包复制到文件夹中
-
选中jar包 -> 右键 -> 选择add as library即可
-
-
需求
- 解析提供好的xml文件
- 将解析到的数据封装到学生对象中
- 并将学生对象存储到ArrayList集合中
- 遍历集合

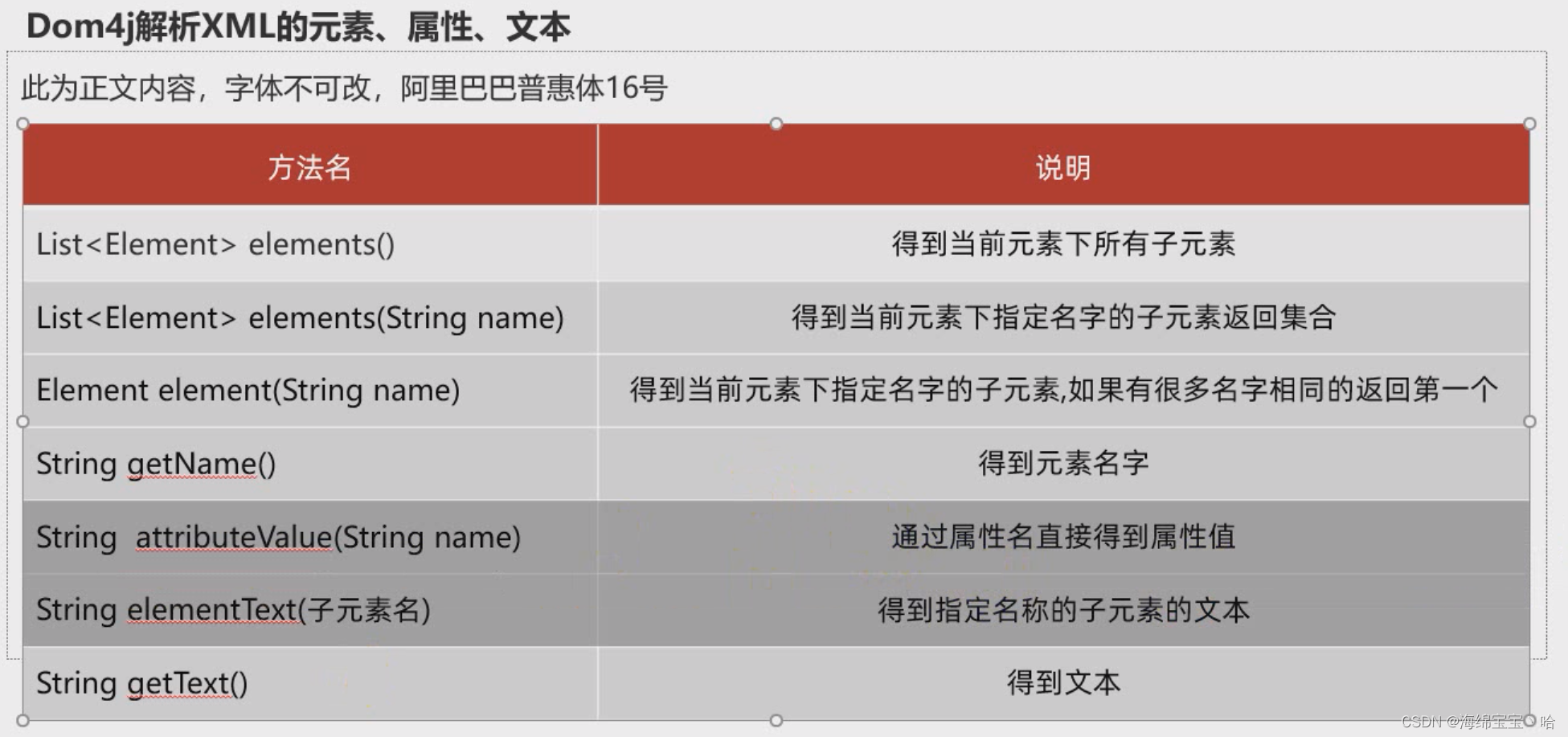

- 代码实现
<?xml version="1.0" encoding="UTF-8" ?>
<students><!--第一个学生信息--><student id="1"><name>张三</name><age>23</age></student><!--第二个学生信息--><student id="2"><name>李四</name><age>24</age></student></students>
public class Student {private String id;private String name;private int age;public Student() {}public Student(String id, String name, int age) {this.id = id;this.name = name;this.age = age;}/*** 获取* @return id*/public String getId() {return id;}/*** 设置* @param id*/public void setId(String id) {this.id = id;}/*** 获取* @return name*/public String getName() {return name;}/*** 设置* @param name*/public void setName(String name) {this.name = name;}/*** 获取* @return age*/public int getAge() {return age;}/*** 设置* @param age*/public void setAge(int age) {this.age = age;}public String toString() {return "Student{id = " + id + ", name = " + name + ", age = " + age + "}";}
}import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;import java.io.File;
import java.util.ArrayList;
import java.util.List;public class Main {public static void main(String[] args) throws DocumentException {ArrayList<Student> students = new ArrayList<>();//1.创建解析器对象SAXReader saxReader = new SAXReader();//2.利用解析器去读取xml文件,并返回文档对象File file = new File("hello.xml");Document document = saxReader.read(file);//3.下面一层一层解析//4.获取根标签Element rootElement = document.getRootElement();//5.获取根标签的子标签List<Element> elements = rootElement.elements();for (Element element : elements) {//6. 获取里面的内容//获取属性和属性值Attribute id = element.attribute("id");String idValue = id.getText();//或者String idValue_ = element.attributeValue("id");//7.获取对应的标签和标签值Element name = element.element("name");String nameValue = name.getText();Element age = element.element("age");int ageValue =Integer.parseInt(age.getText());//8.把Student对象添加到集合中Student student = new Student(idValue, nameValue, ageValue);students.add(student);}System.out.println(students);//[Student{id = 1, name = 张三, age = 23}, Student{id = 2, name = 李四, age = 24}]}
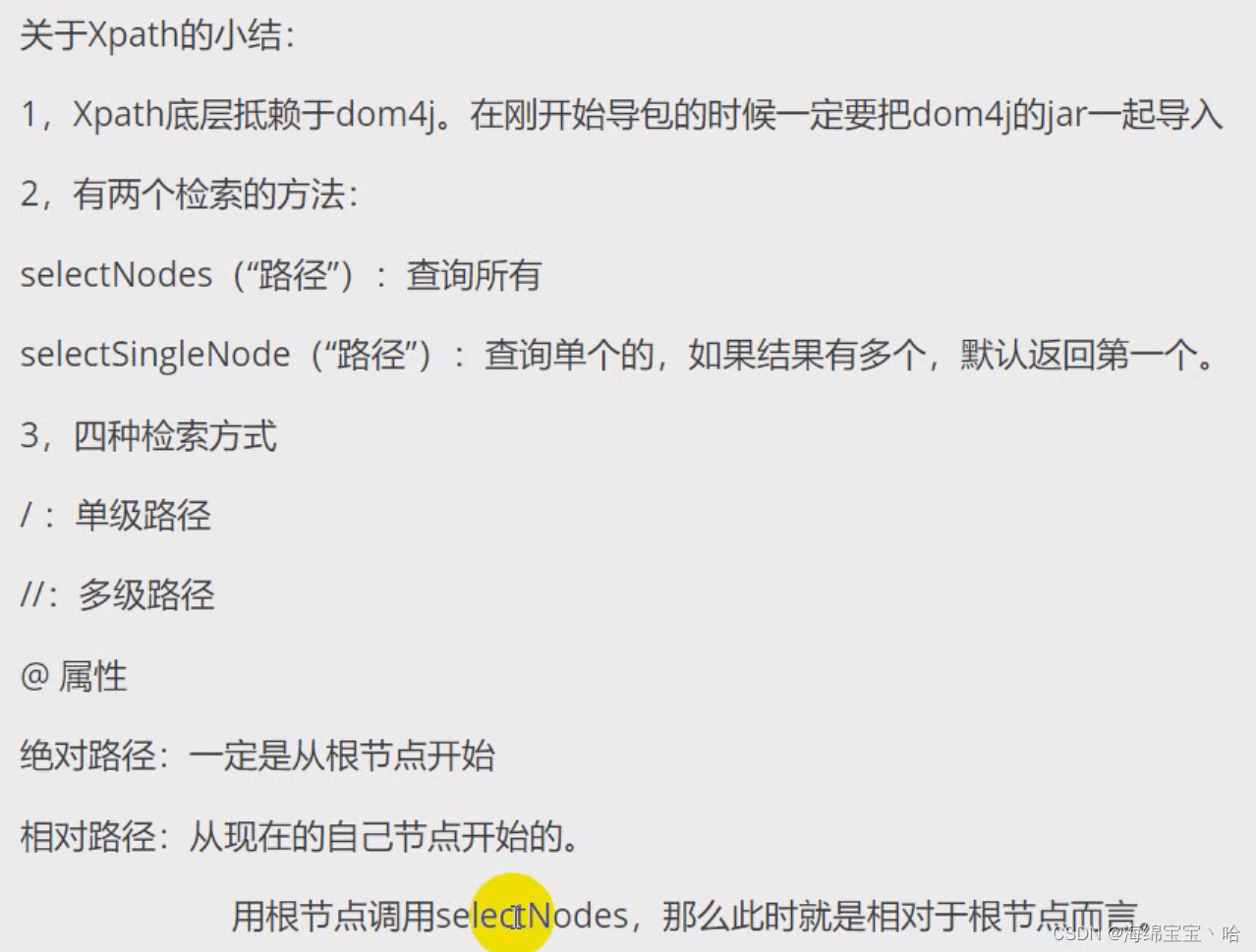
}2.Xpath


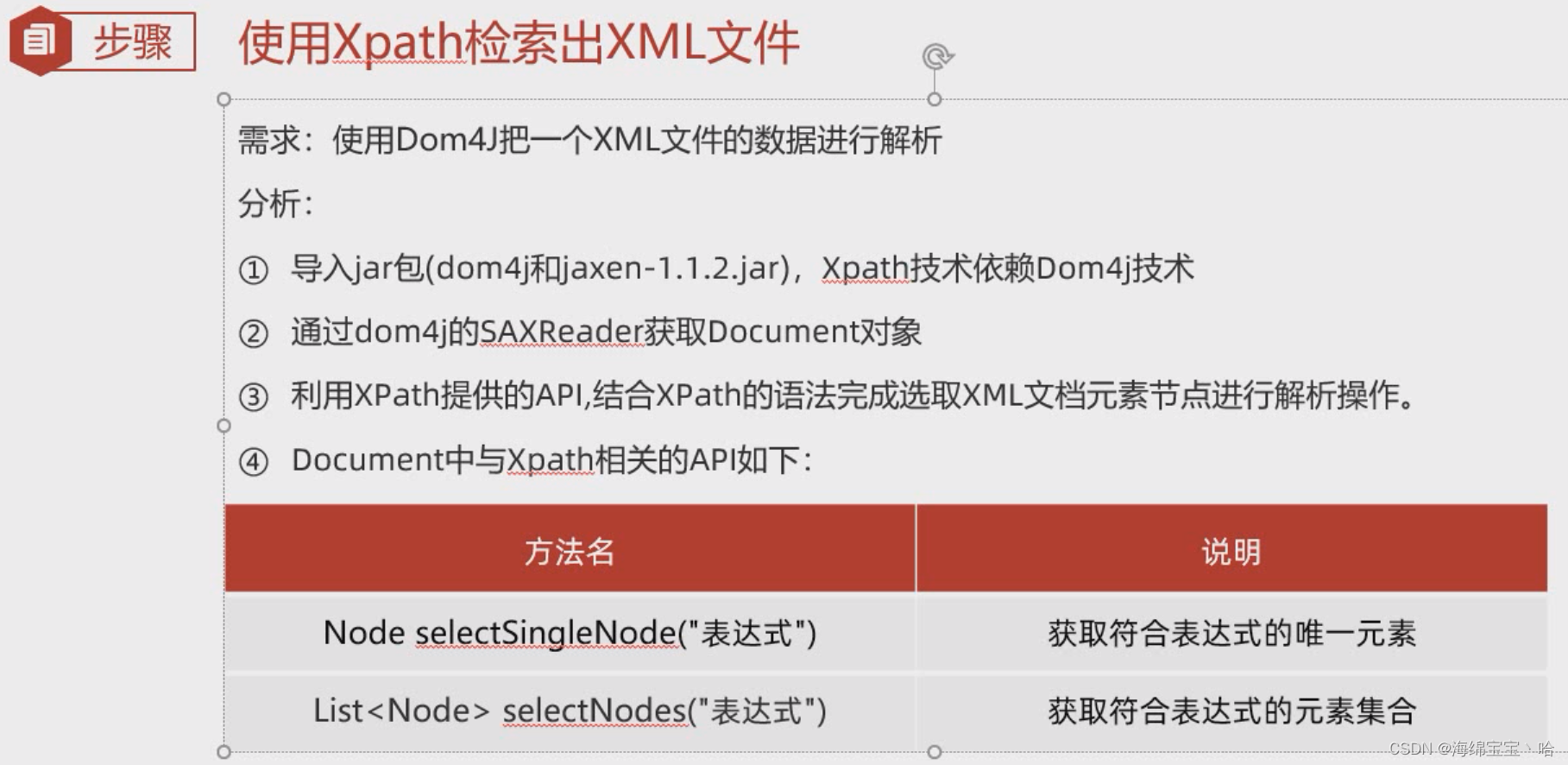
jaxen包下载
<?xml version="1.0" encoding="UTF-8" ?><students><!--第一个学生信息--><student id="1"><name>张三</name><age>23</age></student><!--第二个学生信息--><student id="2"><name>李四</name><age>24</age></student></students>

-
selectNodes:public class Main {public static void main(String[] args) throws DocumentException {ArrayList<Student> students = new ArrayList<>();//1.创建解析器对象SAXReader saxReader = new SAXReader();//2.利用解析器去读取xml文件,并返回文档对象File file = new File("hello.xml");Document document = saxReader.read(file);//3.利用xpath方式快速检索List<Node> nodes = document.selectNodes("/students/student/name");for (Node node : nodes) {System.out.println(node.getText());//张三//李四}} } -
selectSingleNode:如果有多个,则只获取第一个public class Main {public static void main(String[] args) throws DocumentException {//1.创建解析器对象SAXReader saxReader = new SAXReader();//2.利用解析器去读取xml文件,并返回文档对象File file = new File("hello.xml");Document document = saxReader.read(file);//3.利用xpath方式快速检索List<Node> nodes = document.selectNodes("/students/student/name");for (Node node : nodes) {System.out.println(node.getText());//张三//李四}} }

public class Main {public static void main(String[] args) throws DocumentException {//1.创建解析器对象SAXReader saxReader = new SAXReader();//2.利用解析器去读取xml文件,并返回文档对象File file = new File("hello.xml");Document document = saxReader.read(file);//3.利用xpath方式快速检索//首先获取根节点Element rootElement = document.getRootElement();//从根节点这个相对路径获取下面的节点Node node = rootElement.selectSingleNode("./student/name");System.out.println(node.getText());//张三}
}


<?xml version="1.0" encoding="UTF-8" ?><students><!--第一个学生信息--><student id="1"><a><name>张三</name></a><age>23</age></student><!--第二个学生信息--><student id="2"><name>李四</name><age>24</age></student><name>哈哈</name></students>
public class Main {public static void main(String[] args) throws DocumentException {//1.创建解析器对象SAXReader saxReader = new SAXReader();//2.利用解析器去读取xml文件,并返回文档对象File file = new File("hello.xml");Document document = saxReader.read(file);//3.利用xpath方式快速检索List<Node> nodes = document.selectNodes("//name");for (Node node : nodes) {System.out.println(node.getText());//张三//李四//哈哈}List<Node> nodes1 = document.selectNodes("//student/name");for (Node node : nodes1) {System.out.println(node.getText());//李四}List<Node> nodes2 = document.selectNodes("//student//name");for (Node node : nodes2) {System.out.println(node.getText());//张三//李四}}
}
//@属性名:查找的是属性//元素[@属性名]:查找指定属性的标签
<?xml version="1.0" encoding="UTF-8" ?><students><!--第一个学生信息--><student id="1"><a><name>张三</name></a><age>23</age></student><!--第二个学生信息--><student id="2"><name>李四</name><age>24</age></student><name>哈哈</name></students>
public class Main {public static void main(String[] args) throws DocumentException {//1.创建解析器对象SAXReader saxReader = new SAXReader();//2.利用解析器去读取xml文件,并返回文档对象File file = new File("hello.xml");Document document = saxReader.read(file);//3.查属性List<Node> nodes = document.selectNodes("//@id");for (Node node : nodes) {System.out.println(node.getText());//1//2}List<Node> nodes1 = document.selectNodes("//student[@id]");System.out.println(nodes1.size());//2for (Node node : nodes1) {System.out.println(node.getName());//student//student}List<Node> nodes2 = document.selectNodes("//student[@id='1']");System.out.println(nodes2.size());//1for (Node node : nodes2) {System.out.println(node.getName());//student}}
}