网站界面宽搜索优化软件
1. 背景
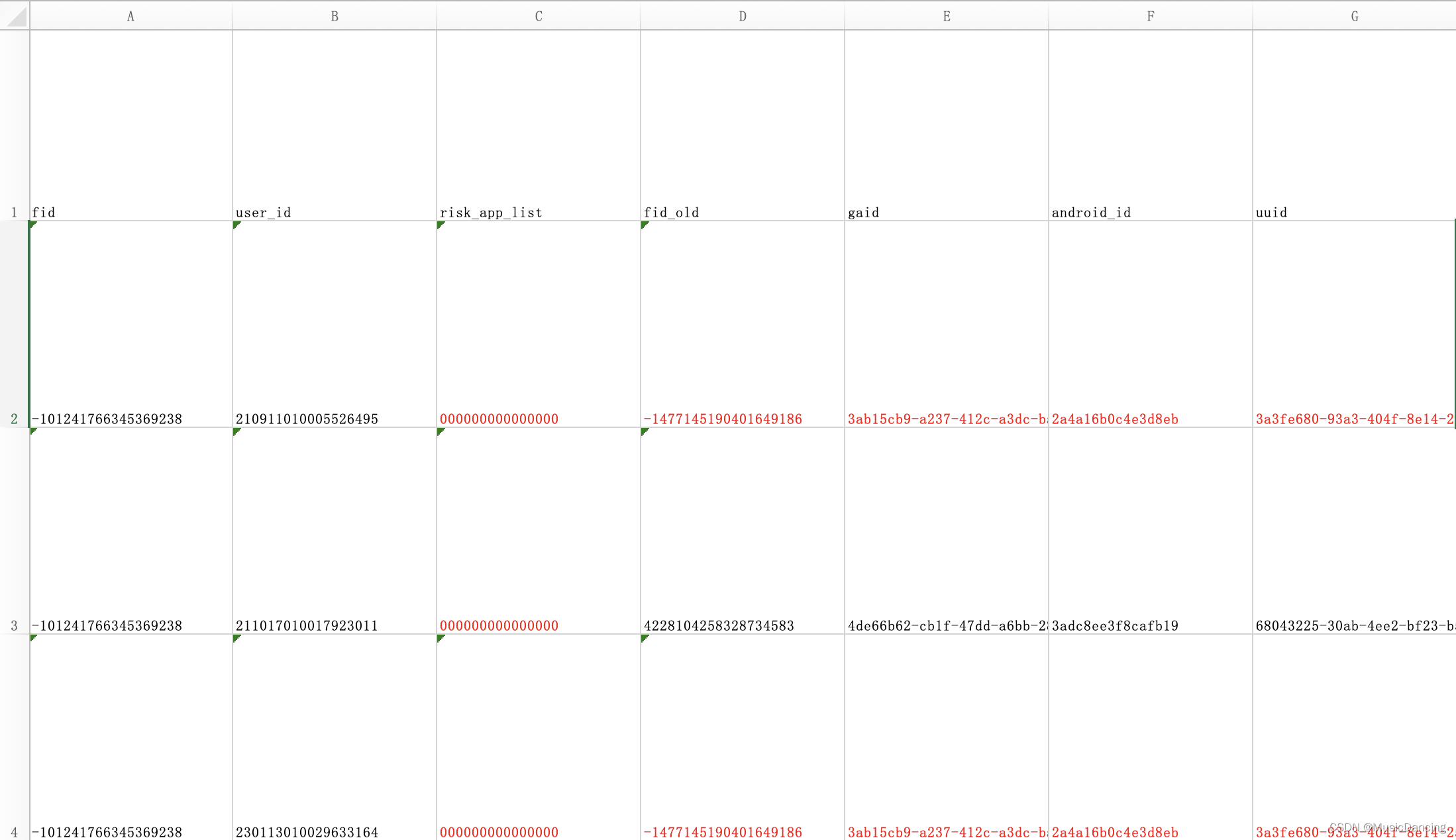
针对下面的文件data.csv,首先根据fid进行排序,然后分组,使相同fid的记录放到同一个excel文件中,并对每列重复的数据元素染上红色。
fid,user_id
-1000078398032092029,230410010036537520
-1000078398032092029,230423010026993942
-1000078398032092029,230505010027684603
-101241766345369238,210911010005526495
-101241766345369238,211017010017923011
-101241766345369238,230113010029633164
-101241766345369238,230514010028256452
-101241766345369238,230518010036813773
-1045165137456710,220401010038956742
-1045165137456710,220401010038956742
-1050918014514687463,210805010001898014
-1050918014514687463,210805010001898014
-111(手动添加一个结束标志)2. 分组切割文件
import pandas as pd
pd.set_option('display.max_rows', None)# 根据fid对文件进行分割,每个fid一个文件
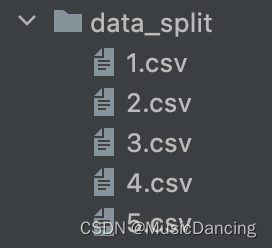
def split_df_by_fid():df = pd.read_csv('data.csv', dtype=str)row_split_list = [] # 记录分割点索引current_fid = '-1000078398032092029' # 第一个fidstart = 0end = startcnt = 1 # 记录当前是第几个分割子文件for fid in df['fid']:if fid != current_fid:row_split_list.append((start, end))# 当前fid组写入一个新文件df[start:end].to_csv('data_split/' + str(cnt) + '.csv', index=0)cnt += 1current_fid = fidstart = endend += 1print("总文件数: ", len(row_split_list))print(row_split_list)# [(0, 3), (3, 8), (8, 10), (10, 12)]
输出
3. 染色-写入excel
1. 找到同列重复元素
def group_by_find_duplicate_values(group_df: pd.DataFrame, col: str) -> list:value_counts = group_df[col].value_counts().reset_index()return value_counts[value_counts[col] > 1]['index'].to_list()2. 插入图片
def inset_a_img(row_index, col_index, img_name):image_path = os.path.join("data_img/", img_name.replace('/', '_'))h, w, *_ = cv2.imread(image_path).shapescale = CEIL_HEIGHT * 1.3 / hSHEET.insert_image(row_index, col_index, image_path, # x_offset可调整x轴图片偏移{'x_offset': 0, 'y_offset': 0, 'x_scale': scale, 'y_scale': scale, 'positioning': 1})3. 同列相同元素染色
# -*- coding: utf-8 -*-
import os
import cv2
import tqdm
import pandas as pd
import xlsxwriter
CEIL_HEIGHT = 156def write_color():df = pd.read_csv(input_file, dtype=str)for i, col in enumerate(df.columns):SHEET.write(0, i, col) # 第0行第i列插入表头字段try:for i, line in tqdm.tqdm(enumerate(df.itertuples())): # tqdm: 显示进度条temp_df = df[df['fid'] == line.fid]for j, col in enumerate(df.columns):duplicate_values = group_by_find_duplicate_values(temp_df, col)content = str(df.iloc[i, j])# 染色cell_format = BOOK.add_format({'font_color': 'red' if (content in duplicate_values and j > 0) else 'black'})if col not in ('face_path', 'ocr_path'):# SHEET.write(*(i + 1, j), content, cell_format)SHEET.write(i+1, j, content, cell_format)else:if col == 'face_path' and not pd.isna(line.face_path):inset_a_img(i+1, j, line.face_path) # 为Nan的置空,不写入图片if col == 'ocr_path' and not pd.isna(line.ocr_path):inset_a_img(i+1, j+1-1, line.ocr_path)BOOK.close()except Exception as e:print(e)if __name__ == '__main__':for file in os.listdir('data_split'):input_file = 'data_split/' + fileoutput_file = 'data_split_xlsx/' + file.replace('csv', 'xlsx')BOOK = xlsxwriter.Workbook(output_file)SHEET = BOOK.add_worksheet('sheet1')SHEET.set_default_row(CEIL_HEIGHT)SHEET.set_column(0, 60, 25) # 分别为要修改的起始列,终止列,设置的列宽write_color()
输出