旅游门户网站源码怎么做的营销方案策划
spark的使用
spark是一款分布式的计算框架,用于调度成百上千的服务器集群。
安装pyspark
# os.environ['PYSPARK_PYTHON']='解析器路径' pyspark_python配置解析器路径
import os
os.environ['PYSPARK_PYTHON']="D:/dev/python/python3.11.4/python.exe"
pip install pyspark # 原始国外安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark #网址安装
java安装
前置安装软件java包
java官网下载地址
一键下一步安装,配置环境变量
首先创建一个JAVA_HOME的全局变量然后在path中通过%%引入执行下面的bin 路径%JAVA_HOME%\bin


执行成功
from pyspark import SparkConf,SparkContext# 创建sparkConf 类对象
conf= SparkConf().setMaster("local[*]").setAppName("test_spark_app")
# 创建sparkConf类对象创建sparkContext对象
sc =SparkContext(conf=conf)
# 打印pySpark的运行脚本
print(sc.version)
# 停止sparkContext对象的运行(停止pySpark程序)
sc.stop()
PySpark的数据计算,都是基于RDD对象来进行的,RDD对象内置丰富的:成员方法(算子)
map算子
功能:map算子,是将RDD的数据一条条处理,处理的逻辑基于map算子中接收的处理函数,返回新的RDD语法:

# 简单执行map将数据乘以10返回,如果不引入python解析器的路径引入就会报错,
from pyspark import SparkConf, SparkContext
# 指定spark的python解析器路径
import os
os.environ['PYSPARK_PYTHON']="D:/dev/python/python3.11.4/python.exe"
# 创建sparkConf 类对象
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
# 创建sparkConf类对象创建sparkContext对象
sc = SparkContext(conf=conf)rdd = sc.parallelize([1, 2, 3, 4, 5, 6])def func(data):return data * 10# map传入一个参数有返回值,是函数或者是值
rdd2 = rdd.map(func)
print(rdd2.collect())

flatMap
flatMap跟map差不多就是在最后做了一个解除嵌套的功能
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON']="D:/dev/python/python3.11.4/python.exe"
# 创建sparkConf 类对象
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
# 创建sparkConf类对象创建sparkContext对象
sc = SparkContext(conf=conf)rdd = sc.parallelize(['中石科技 时间还复活甲 如今房价','慰问金 咖啡机 姐夫哥','格很高 客服管家二恶烷 可归结为'])rdd2 = rdd.flatMap(lambda x:x.split(' '))print(rdd2.collect())
map的结果

reduceByKey
reduceByKey对数据进行分组可以两两计算
from pyspark import SparkConf, SparkContext
import osos.environ['PYSPARK_PYTHON'] = "D:/dev/python/python3.11.4/python.exe"
# 创建sparkConf 类对象
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
# 创建sparkConf类对象创建sparkContext对象
sc = SparkContext(conf=conf)rdd = sc.parallelize([('男', 11), ('男', 22), ('女', 21), ('男', 31), ('女', 99)])
# 把男女进行分组value值进行计算
rdd2 = rdd.reduceByKey(lambda a, b:a+b)print(rdd2.collect()) # [('女', 120), ('男', 64)]reduce
与reduce的区别就是没有进行分组
take
取出前几个数据
...
rdd = sc.parallelize([1,2,3,4,5]).take(3) # [1,2,3]
count
计算rdd中的数据个数
filter

from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON']='D:/dev/python/python3.11.4/python.exe'conf=SparkConf().setMaster('local[*]').setAppName('test_spark')
sc=SparkContext(conf=conf)rdd=sc.parallelize([1,2,3,4,5])rdd2=rdd.filter(lambda a:a%2==0)
print(rdd2.collect()) # [2,4]distinct
进行数据去重
from pyspark import SparkConf,SparkContext
import os
os.environ['PYSPARK_PYTHON']='D:/dev/python/python3.11.4/python.exe'conf=SparkConf().setMaster('local[*]').setAppName('test_spark')
sc=SparkContext(conf=conf)add= sc.parallelize([1,2,3,4,5,6,73,3,2,4,56,3,5])add2=add.distinct()
print(add2.collect()) # [56, 1, 73, 2, 3, 4, 5, 6]
sortBy排序
from pyspark import SparkConf, SparkContext
import osos.environ['PYSPARK_PYTHON'] = 'D:/dev/python/python3.11.4/python.exe'conf = SparkConf().setMaster('local[*]').setAppName('test_spark')
sc = SparkContext(conf=conf)add = sc.textFile('D:/wordText.txt')word_rdd = add.flatMap(lambda x: x.split(' '))
word_with_rdd = word_rdd.map(lambda word: (word, 1))
result_rdd =word_with_rdd.reduceByKey(lambda a,b:a+b)
result_num=result_rdd.sortBy(lambda x:x[1],ascending=False,numPartitions=1) # 1.根据什么排序,2.True 升序 False降序 3.分布式分区
print(result_num.collect())
collect
将rdd内容变成list,从而就可以打印出来
spark写入文件
首先安装
- 下载Hadoop安装包Hadoop安装包
- 然后把hadoop.dll放入指定文件夹内
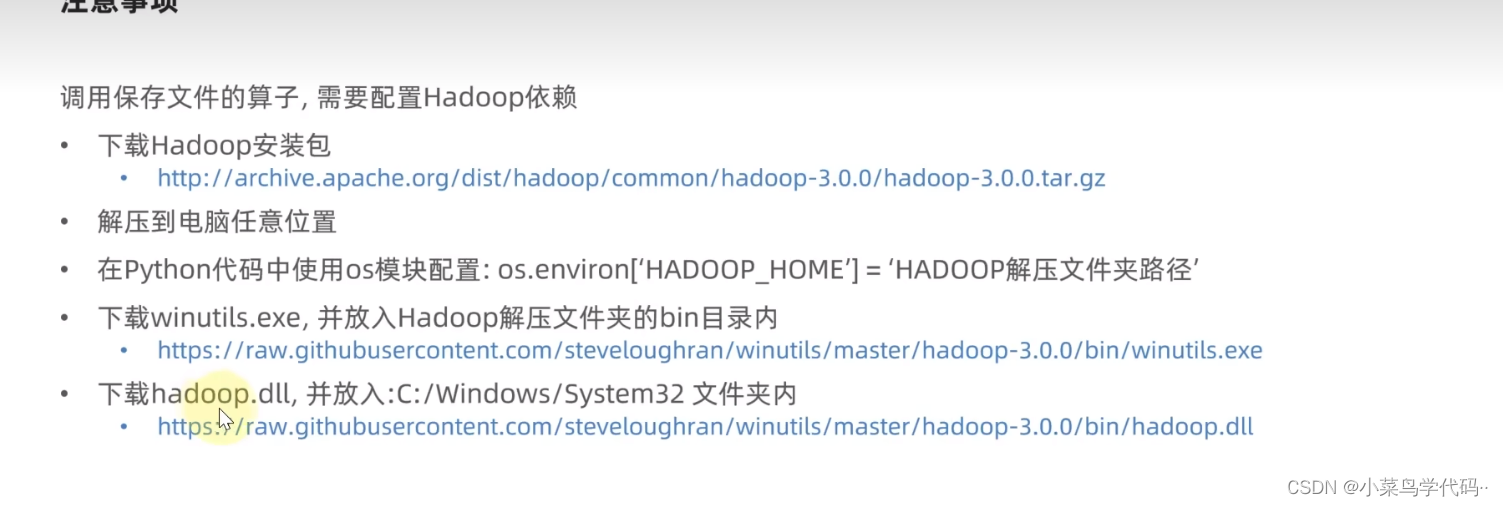
os.environ['HADOOP_HOME']='D:/dev/hadoop/hadoopjob3.0'
conf = SparkConf().setMaster('local[*]').setAppName('test_spark')
sc = SparkContext(conf=conf)rdd2=sc.parallelize([[1,3,5],[6,7,9]])
rdd2.saveAsTextFile('D:/output1')
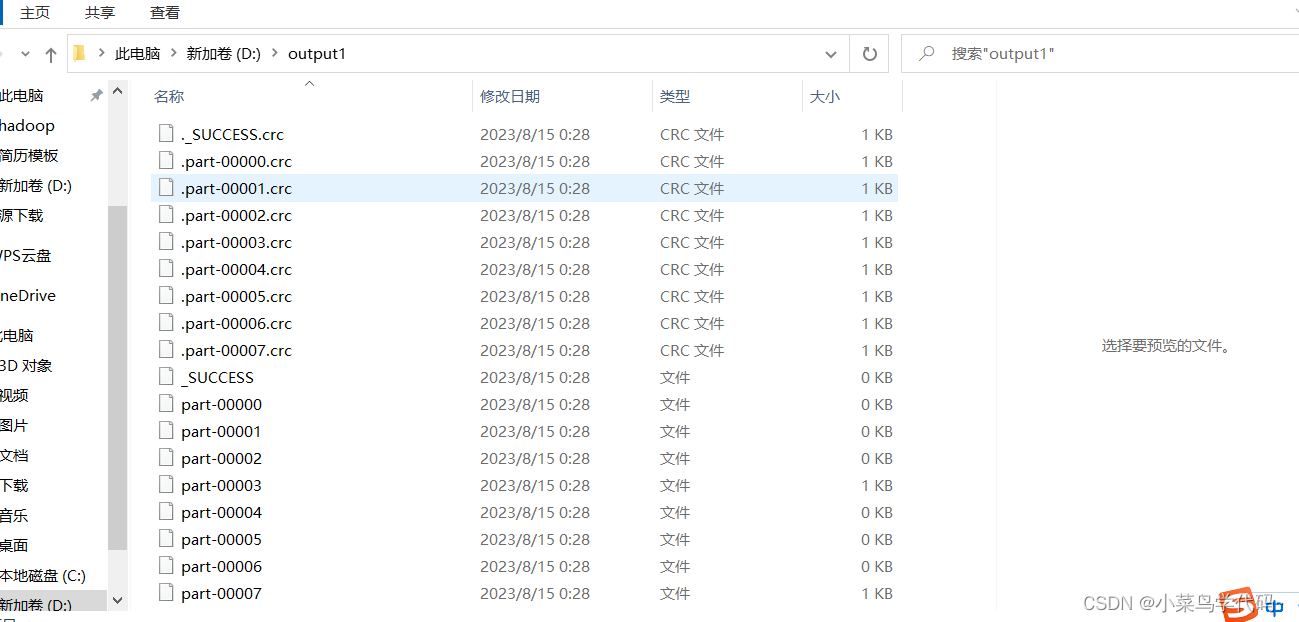
这样创建出来的文件就有16个分区,因为我的是16内核
如果想要在一个分区就要设置参数
import ...
os.environ['PYSPARK_PYTHON'] = 'D:/dev/python/python3.11.4/python.exe'
os.environ['HADOOP_HOME']='D:/dev/hadoop/hadoopjob3.0'
conf = SparkConf().setMaster('local[*]').setAppName('test_spark')
# 第一种
conf.set("spark.default.parallelism",'1') # 设置一个分区
sc = SparkContext(conf=conf)# rdd2=sc.parallelize([[1,3,5],[6,7,9]])
# 第二种设置一个分区
rdd2=sc.parallelize([[1,3,5],[6,7,9]],1) # numSlices=1 参数可以不写直接传1
rdd2.saveAsTextFile('D:/output1')