政务公开网站建设重点seo优化方案模板
大模型 | NEFTune之引入随机噪声对大模型训练的收益
paper中提到,在模型foward过程中,对inputs_embedding增加适度的随机噪声,会带来显著的收益。
Paper: https://arxiv.org/pdf/2310.05914.pdf
Github: https://github.com/neelsjain/NEFTune
文章目录
- 大模型 | NEFTune之引入随机噪声对大模型训练的收益
- 理论
- 一. 实践方法
- 1.1 等待Hugging发布该功能
- 1.2 直接封装model
- 1.3 改写compute_loss
理论
核心是输入经过Embedding层后,再加入一个均匀分布的噪声,噪声的采样范围为 [ − α L d , α L d ] [-\frac{\alpha}{\sqrt{Ld}},\frac{\alpha}{\sqrt{Ld}}] [−Ldα,Ldα]之间,其中 α \alpha α为噪声超参,L为输入长度,d为Embedding层维度(即hidden维度)
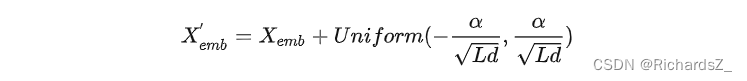
在AlpacaEval榜单上,利用GPT4作为评分器,在多个数据上微调Llama2-7B模型,NEFTune方法相较于直接微调方法,均有显著提高。

可以缓解模型在指令微调阶段的过拟合现象,可以更好的利用预训练阶段的知识内容。
一. 实践方法
1.1 等待Hugging发布该功能
进度:等待hugging face正式发布此功能,2023-10-26
[10/17/2023] NEFTune has been intregrated into the Huggingface’s TRL (Transformer Reinforcement Learning) library. See Annoucement.
1.2 直接封装model
进度:直接对模型进行如下封装,原理是对model.embed_tokens.forward()进行改写,经实践,这种方法不管用,会报堆栈溢出的error。
from torch.nn import functional as Fdef NEFTune(model, noise_alpha=5)def noised_embed(orig_embed, noise_alpha):def new_func(x):# during training, we add noise to the embedding# during generation, we don't add noise to the embeddingif model.training:embed_init = orig_embed(x)dims = torch.tensor(embed_init.size(1) * embed_init.size(2))mag_norm = noise_alpha/torch.sqrt(dims)return embed_init + torch.zeros_like(embed_init).uniform_(-mag_norm, mag_norm)else:return orig_embed(x)return new_func##### NOTE: this is for a LLaMA model ##### ##### For a different model, you need to change the attribute path to the embedding #####model.base_model.model.model.embed_tokens.forward = noised_embed(model.base_model.model.model.embed_tokens, noise_alpha)return model
1.3 改写compute_loss
进度:loss能够正常计算,但optimzer会报错,可能与精度有关,尚未解决
由于损失函数是自己写的,因此尝试在model(**input)前,追加噪声代码。注意,原先传入model的是input_ids,而当下由于我们将inputs_embeds增加了噪声,因此传入model的将直接替换为inputs_embeds,代码如下
class TargetLMLossNeft(Loss):def __init__(self, ignore_index):super().__init__()self.ignore_index = ignore_indexself.loss_fn = nn.CrossEntropyLoss(ignore_index=ignore_index)def __call__(self, model, inputs, training_args, return_outputs=False):input_ids = inputs['input_ids'] # B x L [3, 964]attention_mask = inputs['attention_mask'] # B x L target_mask = inputs['target_mask'] # B x L### ----------------------------- add noise to embedsneftune_alpha = 5embed_device = model.base_model.model.model.embed_tokens.weight.deviceembeds_init = model.base_model.model.model.embed_tokens.forward(input_ids).to(embed_device) # 先forward一下, 变成B X L X hidden_state# embed_device = model.model.embed_tokens.weight.device# embeds_init = model.model.embed_tokens.forward(input_ids).to(embed_device)input_mask = attention_mask.to(embeds_init) # B x Linput_lengths = torch.sum(input_mask, 1) # B, 计算每个sample的实际长度noise_ = torch.zeros_like(embeds_init).uniform_(-1,1) # B X L X hidden_state, 且值域在[-1,1]正态分布delta = noise_ * input_mask.unsqueeze(2) # 追加一个维度,由B X L 变成 B X L X hidden_statedims = input_lengths * embeds_init.size(-1)mag = neftune_alpha / torch.sqrt(dims)delta = (delta * mag.view(-1, 1, 1)).detach() # B X L X hidden_stateinputs_embeds = delta + embeds_init### ----------------------------- add noise to embeds# 模型前馈预测, 原来传入的是input_ids,而现在需要直接将增加了noise的inputs_embeds传入# outputs = model(input_ids=input_ids, attention_mask=attention_mask, return_dict=True)outputs = model(inputs_embeds=inputs_embeds, attention_mask=attention_mask, return_dict=True)logits = outputs["logits"] if isinstance(outputs, dict) else outputs[0] # 正常应该是torch.float32#logits.requires_grad = True # 奇怪,为什么这里会默认为False, 难道是因为上边的detach()# 将labels中不属于target的部分,设为ignore_index,只计算target部分的losslabels = torch.where(target_mask == 1, input_ids, self.ignore_index)shift_logits = logits[..., :-1, :].contiguous()shift_labels = labels[..., 1:].contiguous()# Flatten the tokensloss = self.loss_fn(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)) # float32loss.requires_grad = Truereturn (loss, outputs) if return_outputs else loss