做移动网站优化快速排名软件业务网站制作
SERP是搜索引擎结果页的缩写,它是你在百度、谷歌、Bing等搜索引擎中提交查询后所得到的页面。搜索引擎需要给所有页面做排序,把最能解决我们需求的页面展示给我们,企业会非常关注结果页的排序,也就是本企业内容的自然排名情况。手工研究这个结果,非常困难,一般都会借助一些成熟产品、或者集成SERP API接口,例如:
- Serpapi-Google搜索,快速、简单和完整的抓取Google、百度、Bing、易趣、雅虎、沃尔玛等和其他搜索引擎的数据
- Serpdog搜索引擎数据抓取,该API为企业和开发者提供了一种迅速且高效的途径来搜集搜索引擎的数据,可在线体验
- Bright Data – SERP API,通过该API,用户可以获取搜索结果、排名信息、广告数据、关键词建议等,帮助他们深入了解市场动态、分析竞争对手、调整SEO策略等。
本文讲述另外一种方法,如何通过网页抓取API来获取结果,而不是直接使用SERP API。
什么是网页抓取API?
网页抓取(即网络抓取、网站抓取、网络数据提取)是指从目标网站收集公共网络数据的自动化流程。不必手动采集数据,使用网页抓取工具几秒钟就可以获取大量信息。
网页抓取API通常用于分析竞争对手、市场趋势,获取消费者行为的宝贵见解等场景,是企业营销自动化的必需品。
网页抓取API是否存在风险?可以阅读《网页抓取API是否存在风险》一文。
定制化获取SERP信息的过程
本文主要用Scraperbox 公司提供的网页抓取API示例使用过程。一般网页抓取API包括如下几个过程:抓取 –> 解析 –> 结构化存储 –>数据分析。
集成网页抓取API
对于此示例,让我们创建一个调用 ScraperBox API 的 Python 程序,确保YOUR_API_KEY用您的 API 密钥替换:
import urllib.parseimport urllib.requestimport sslssl._create_default_https_context = ssl._create_unverified_context# Urlencode the URLurl = urllib.parse.quote_plus("https://www.google.com/search?q=用幂简集成搜索API")# Create the query URL.query = "https://api.scraperbox.com/scrape"query += "?api_key=%s" % "YOUR_API_KEY"query += "&url=%s" % url# Call the API.request = urllib.request.Request(query)raw_response = urllib.request.urlopen(request).read()html = raw_response.decode("utf-8")print(html)谷歌和大多数网站一样,并不太喜欢自动化程序获取搜索结果页面。
一个解决方案是通过设置正常的标题来掩盖我们是自动化程序的事实User-Agent。
...request = urllib.request.Request(query)# Set a normal User Agent headerrequest.add_header('User-Agent', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36')raw_response = urllib.request.urlopen(request).read()# Read the repsonse as a utf-8 stringhtml = raw_response.decode("utf-8")print(html)request = urllib.request.Request(query)用户BeautifulSoup解析数据
想要从页面中提取实际的搜索结果。先要弄清楚如何访问搜索结果,启动了 Chrome 并检查了 Google 搜索结果页面:
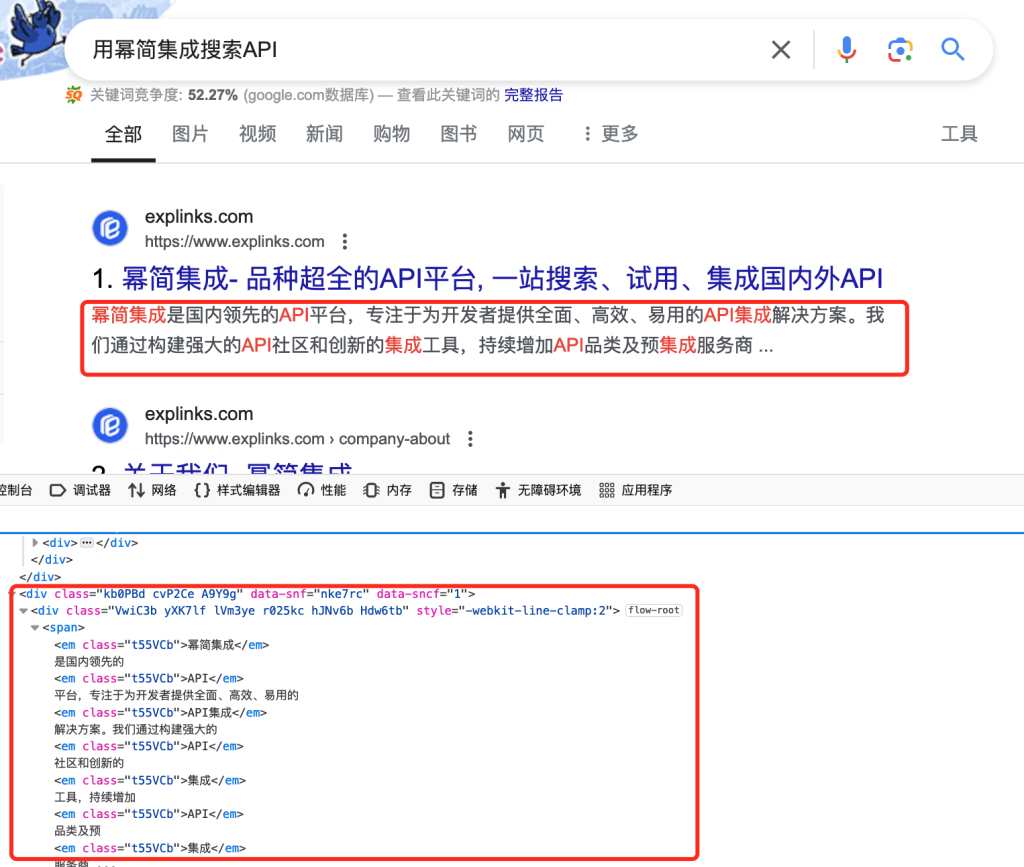
我们可以使用这些信息通过 BeautifulSoup 提取搜索结果。
# Construct the soup objectsoup = BeautifulSoup(html, 'html.parser')# Find all the search result divsdivs = soup.select("#search div.g")for div in divs:# For now just print the text contents.print(div.get_text() + "\n\n")当我检查页面时,我发现搜索标题包含在h3标签中。我们可以利用这些信息来提取标题。
# Find all the search result divsdivs = soup.select("#search div.g")for div in divs:# Search for a h3 tagresults = div.select("h3")# Check if we have found a resultif (len(results) >= 1):# Print the titleh3 = results[0]print(h3.get_text())</code></pre>按此方式解析其它要素。
其它两个步骤比较简单,不再讲解。
抓取大量页面时,被拦截怎么办?
Google 很快就会发现这是一个机器人并做出 IP拦截 。
方案一:以非常稀疏的方式进行抓取,并在每次请求之间等待 10 秒。但是,如果您需要抓取大量搜索查询,那么这不是最佳解决方案。
方案二:另一个解决方案是购买 IP代理服务器。这样你就可以从不同的 IP 地址抓取数据。但这里又有一个问题。很多人想抓取 Google 搜索结果,因此大多数代理已被 Google 屏蔽。
方案三:再一种方法是购买住宅IP代理,这些 IP 地址与真实用户无法区分。