有没有什么网站免费做名片南京seo优化推广
文章目录
- 专栏导读
- 一、前言
- 二、ddddocr库使用说明
- 1. 介绍
- 2. 算法步骤
- 3. 安装
- 4. 参数说明
- 5. 纯数字验证码识别
- 6. 纯英文验证码识别
- 7. 英文数字验证码识别
- 8. 带干扰的验证码识别
- 三、验证码识别登录代码实战
- 1. 输入账号密码
- 2. 下载验证码
- 3. 识别验证码并登录
- 书籍推荐
专栏导读
🔥🔥本文已收录于《100天精通Python从入门到就业》:本专栏专门针对零基础和需要进阶提升的同学所准备的一套完整教学,从0到100的不断进阶深入,后续还有实战项目,轻松应对面试,专栏订阅地址:https://blog.csdn.net/yuan2019035055/category_11466020.html
- 优点:订阅限时9.9付费专栏进入千人全栈VIP答疑群,作者优先解答机会(代码指导、远程服务),群里大佬众多可以抱团取暖(大厂内推机会)
- 专栏福利:简历指导、招聘内推、每周送实体书、80G全栈学习视频、300本IT电子书:Python、Java、前端、大数据、数据库、算法、爬虫、数据分析、机器学习、面试题库等等
一、前言
兄弟们使用selenium自动登录网站的时候,是不是经常遇到数字验证码,使用传统的OCR库识别效果又不是很好,今天介绍一款效果非常棒的验证码识别模块——ddddocr。
二、ddddocr库使用说明
1. 介绍
ddddocr(带带弟弟ocr)是一个用于文字识别的开源库。它是基于深度学习技术的,具有高度的准确性和鲁棒性。ddddocr使用了深度神经网络来处理各种类型的文本,包括印刷体和手写体等。其双解码机制使其在处理复杂文本时表现出色。
这个库的特点之一是其模型结构的密集性(Dense),这意味着它能够更好地捕捉文本中的细节和特征,从而提高了识别的准确性。此外,它还采用了双解码机制(Dual Decode),这意味着它可以同时从多个角度对图像进行解码,进一步提高了识别的鲁棒性和准确性。
Github地址:https://github.com/sml2h3/ddddocr
2. 算法步骤
ddddocr这个库的算法主要包括以下几个步骤:
-
图像预处理:
- 图像预处理是任何OCR系统中的第一步。它旨在使图像更容易处理,并提高文本识别的准确性。预处理步骤可能包括灰度化、二值化、去噪声、图像增强等操作,以减少后续步骤中的噪声和干扰。
-
文本检测:
- 文本检测是指识别图像中文本的位置和边界框。这一步通常使用深度学习技术,如卷积神经网络 (CNN) 或循环神经网络 (RNN) 来实现。检测到的文本通常用矩形边界框表示。
-
文本识别:
- 文本识别是从检测到的文本区域中提取出实际的文本内容。这通常涉及到使用循环神经网络 (RNN)、注意力机制或转录网络等模型来识别文本。这些模型可以是基于字符的,也可以是基于单词或子词的。
-
后处理:
- 后处理步骤旨在提高识别准确性并改善结果的质量。这可能包括语言模型的应用、纠正错误、识别字体或手写风格等。
-
输出结果:
- 最终结果通常以文本形式呈现,或者以标记文本的边界框和对应的文本内容的形式提供。
ddddOCR库可能会结合这些步骤,利用深度学习模型和传统的计算机视觉技术来实现文本识别。在不同的应用场景下,可能会有一些额外的步骤或优化,比如针对特定的文档类型进行优化、处理不同语言的文本等。
3. 安装
硬性要求 Python >= 3.8,通过pip命令进行安装:
pip install ddddocr
4. 参数说明
我们这里使用的是ddddocr.DdddOcr()类:
class DdddOcr(object):def __init__(self, ocr: bool = True, det: bool = False, old: bool = False, beta: bool = False,use_gpu: bool = False,device_id: int = 0, show_ad=True, import_onnx_path: str = "", charsets_path: str = "")
这个__init__方法是一个Python类的构造函数,它定义了类的初始化过程,其中包含了一系列参数。让我来解释一下这些参数的含义:
-
ocr: 这是一个布尔类型的参数,用于指定是否进行光学字符识别(OCR)。默认值为True,表示默认情况下会进行OCR。 -
det: 这也是一个布尔类型的参数,用于指定是否进行文本检测(Text Detection)。默认值为False,表示默认情况下不会进行文本检测。 -
old: 这是一个布尔类型的参数,用于指定是否使用旧版本的模型或方法。默认值为False,表示默认情况下不使用旧版本。 -
beta: 这也是一个布尔类型的参数,用于指定是否使用测试版本(beta版本)的功能或方法。默认值为False,表示默认情况下不使用测试版本。 -
use_gpu: 这是一个布尔类型的参数,用于指定是否使用GPU来进行计算。默认值为False,表示默认情况下不使用GPU,而使用CPU。 -
device_id: 这是一个整数类型的参数,用于指定在使用GPU时要使用的GPU设备的ID。默认值为0,表示默认情况下使用ID为0的GPU设备。 -
show_ad: 这是一个布尔类型的参数,用于指定是否显示广告。默认值为True,表示默认情况下会显示广告。 -
import_onnx_path: 这是一个字符串类型的参数,用于指定导入ONNX模型的路径。默认值为空字符串,表示默认情况下不导入任何ONNX模型。 -
charsets_path: 这是一个字符串类型的参数,用于指定字符集的路径。默认值为空字符串,表示默认情况下字符集的路径未指定。
这个类中有一个classification方法,需要传递一个图片对象进入就可以识别了:
def classification(self, img, png_fix: bool = False):if self.det:raise TypeError("当前识别类型为目标检测")if not isinstance(img, (bytes, str, pathlib.PurePath, Image.Image)):raise TypeError("未知图片类型")if isinstance(img, bytes):image = Image.open(io.BytesIO(img))elif isinstance(img, Image.Image):image = img.copy()elif isinstance(img, str):image = base64_to_image(img)else:assert isinstance(img, pathlib.PurePath)image = Image.open(img)if not self.use_import_onnx:image = image.resize((int(image.size[0] * (64 / image.size[1])), 64), Image.ANTIALIAS).convert('L')else:if self.__resize[0] == -1:if self.__word:image = image.resize((self.__resize[1], self.__resize[1]), Image.ANTIALIAS)else:image = image.resize((int(image.size[0] * (self.__resize[1] / image.size[1])), self.__resize[1]),Image.ANTIALIAS)else:image = image.resize((self.__resize[0], self.__resize[1]), Image.ANTIALIAS)if self.__channel == 1:image = image.convert('L')else:if png_fix:image = png_rgba_black_preprocess(image)else:image = image.convert('RGB')image = np.array(image).astype(np.float32)image = np.expand_dims(image, axis=0) / 255.if not self.use_import_onnx:image = (image - 0.5) / 0.5else:if self.__channel == 1:image = (image - 0.456) / 0.224else:image = (image - np.array([0.485, 0.456, 0.406])) / np.array([0.229, 0.224, 0.225])image = image[0]image = image.transpose((2, 0, 1))ort_inputs = {'input1': np.array([image]).astype(np.float32)}ort_outs = self.__ort_session.run(None, ort_inputs)result = []
5. 纯数字验证码识别
测试图片:

测试代码:
import ddddocr
import timestart = time.time() # 开始时间# 1. 创建DdddOcr对象
ocr = ddddocr.DdddOcr(show_ad=False)# 2. 读取图片
with open('test.png', 'rb') as f:img = f.read()# 3. 识别图片内验证码并返回字符串
result = ocr.classification(img)
print("识别结果:",result)end = time.time()
print("耗时:%s 秒" % str(start-end))
运行结果:
识别结果: 0413
耗时:-0.12942123413085938 秒
6. 纯英文验证码识别
测试图片:

运行结果:
识别结果: bcsm
耗时:-0.11309981346130371 秒
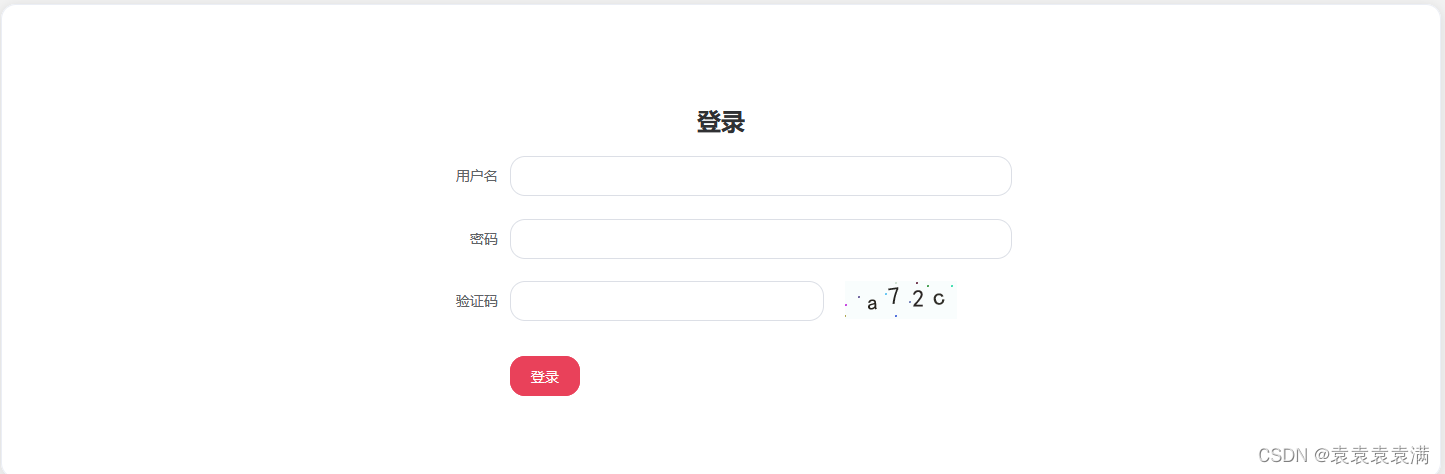
7. 英文数字验证码识别
测试图片:

运行结果:
识别结果: a72c
耗时:-0.09667587280273438 秒
8. 带干扰的验证码识别
测试图片:

运行结果:
识别结果: i27kYk
耗时:-0.09169244766235352 秒
可以看到ddddocr库识别验证码还是特别给力的!!!
三、验证码识别登录代码实战
上一期我们讲了如何使用selenium输入账号信息登录网站,还不会的可以去复习一下:https://blog.csdn.net/yuan2019035055/article/details/136284263
测试网站:https://captcha7.scrape.center/
1. 输入账号密码
运行下面代码将会输入账号密码:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time# 1. 创建链接
# 创建ChromeOptions对象,用于配置Chrome浏览器的选项
chrome_options = webdriver.ChromeOptions()
# 添加启动参数,'--disable-gpu'参数用于禁用GPU加速,适用于部分平台上的兼容性问题
chrome_options.add_argument('--disable-gpu')# 2. 添加请求头伪装浏览器
chrome_options.add_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36')
driver = webdriver.Chrome(chrome_options=chrome_options)# 3. 执行 `stealth.min.js` 文件进行隐藏浏览器指纹
with open('stealth.min.js') as f:js = f.read()
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": js
})# 4. 最大化浏览器窗口
driver.maximize_window()# 5. 发送请求,打开网页
driver.get('https://captcha7.scrape.center/')
time.sleep(1)# 6. 输入账号密码
username_input = driver.find_element(by=By.XPATH, value="//div[@class='el-tooltip username item el-input']/input") # 定位账号框
username_input.send_keys("your_username") # 输入账号信息(这里自行替换)password_input = driver.find_element(by=By.XPATH, value="//div[@class='el-tooltip password item el-input']/input") # 定位密码框
password_input .send_keys("your_username") # 输入密码信息(这里自行替换)time.sleep(100)
运行结果:

2. 下载验证码
1、先找到验证码图片的ID:
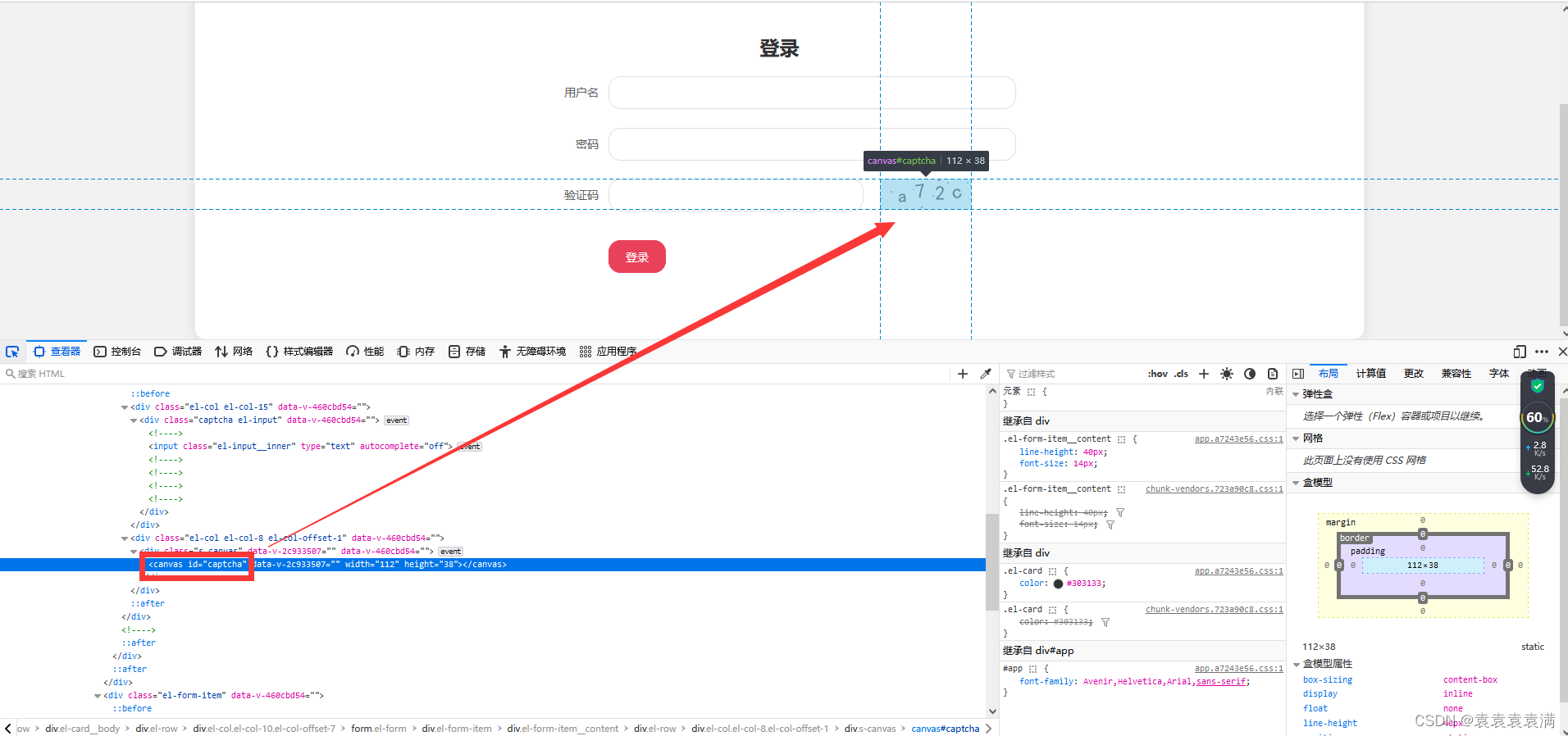
ID为:
captcha
2、定位验证码:
element = driver.find_element(By.ID, 'captcha') # 定位验证码
3、使用screenshot('test.png')方法保存截图在本地:
element.screenshot('test.png') # 保存截图
完整代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time# 1. 创建链接
# 创建ChromeOptions对象,用于配置Chrome浏览器的选项
chrome_options = webdriver.ChromeOptions()
# 添加启动参数,'--disable-gpu'参数用于禁用GPU加速,适用于部分平台上的兼容性问题
chrome_options.add_argument('--disable-gpu')# 2. 添加请求头伪装浏览器
chrome_options.add_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36')
driver = webdriver.Chrome(chrome_options=chrome_options)# 3. 执行 `stealth.min.js` 文件进行隐藏浏览器指纹
with open('stealth.min.js') as f:js = f.read()
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": js
})# 4. 最大化浏览器窗口
driver.maximize_window()# 5. 发送请求,打开网页
driver.get('https://captcha7.scrape.center/')
time.sleep(1)# 6. 输入账号密码
username_input = driver.find_element(by=By.XPATH, value="//div[@class='el-tooltip username item el-input']/input") # 定位账号框
username_input.send_keys("your_username") # 输入账号信息(这里自行替换)password_input = driver.find_element(by=By.XPATH, value="//div[@class='el-tooltip password item el-input']/input") # 定位密码框
password_input .send_keys("your_username") # 输入密码信息(这里自行替换)# 7. 下载验证码
element = driver.find_element(By.ID, 'captcha') # 定位验证码
element.screenshot('test.png') # 保存截图
运行结束就会在当前路径下保存验证码图片:
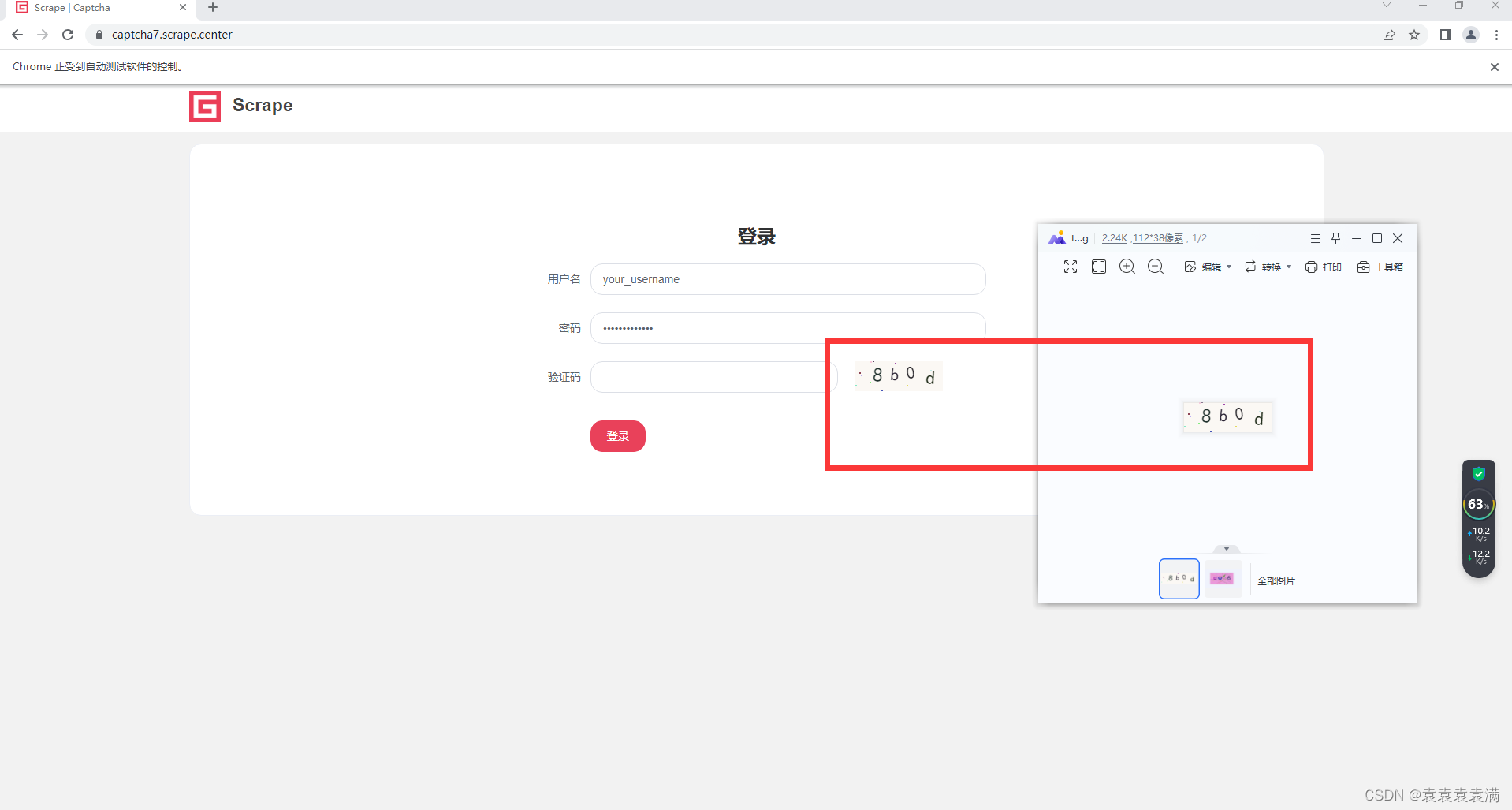
注意:当网站的验证码图片没法定位下载的时候,可以使用Python定位屏幕指定位置截图的模块,如:pyautogui等等,进行截图下载验证码图片
3. 识别验证码并登录
接下来需要识别验证码内容,定位验证码文本框,输入验证码,点击登录,完整代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import ddddocr# 1. 创建链接
# 创建ChromeOptions对象,用于配置Chrome浏览器的选项
chrome_options = webdriver.ChromeOptions()
# 添加启动参数,'--disable-gpu'参数用于禁用GPU加速,适用于部分平台上的兼容性问题
chrome_options.add_argument('--disable-gpu')# 2. 添加请求头伪装浏览器
chrome_options.add_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36')
driver = webdriver.Chrome(chrome_options=chrome_options)# 3. 执行 `stealth.min.js` 文件进行隐藏浏览器指纹
with open('stealth.min.js') as f:js = f.read()
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": js
})# 4. 最大化浏览器窗口
driver.maximize_window()# 5. 发送请求,打开网页
driver.get('https://captcha7.scrape.center/')
time.sleep(1)# 6. 输入账号密码
username_input = driver.find_element(by=By.XPATH, value="//div[@class='el-tooltip username item el-input']/input") # 定位账号框
username_input.send_keys("your_username") # 输入账号信息(这里自行替换)password_input = driver.find_element(by=By.XPATH, value="//div[@class='el-tooltip password item el-input']/input") # 定位密码框
password_input .send_keys("your_username") # 输入密码信息(这里自行替换)# 7. 下载验证码
element = driver.find_element(By.ID, 'captcha') # 定位验证码
element.screenshot('test.png') # 保存截图# 8. 识别验证码
# 创建DdddOcr对象
ocr = ddddocr.DdddOcr(show_ad=False)
# 读取图片
with open('test.png', 'rb') as f:img = f.read()
# 识别图片内验证码并返回字符串
result = ocr.classification(img)
print("识别结果:",result)# 9. 输入验证码
yzm = driver.find_element(by=By.XPATH, value="//div[@class='captcha el-input']/input") # 定位账号框
yzm.clear() # 清空默认文本
yzm.send_keys(result)# 10. 点击登录按钮元素
login_button = driver.find_element(by=By.XPATH, value="//button[@class='el-button login el-button--primary']")
# 点击登录按钮
login_button.click()time.sleep(100)
运行结果:

书籍推荐
《Python机器学习 》

《Python机器学习》首先介绍Python机器学习的一些基本库,包括NumPy、Pandas和matplotlib。一旦牢固地掌握了基础知识,即可开始基于Python和Scikit-learn库进行机器学习,深入了解各种机器学习算法(如回归、聚类和分类)的底层工作原理。本书专门用一章的篇幅讲解如何使用Azure Machine Learning Studio进行机器学习;利用该平台,开发人员不必编写代码即可开始构建机器学习模型。本书最后讨论如何部署供客户端应用程序使用的已构建模型。
《Python机器学习》面向机器学习新手,主要内容如下:
● Python机器学习的一些基本库,包括NumPy、Pandas和matplotlib库
● 常见的机器学习算法,包括回归、聚类、分类和异常检测
● 使用Python和Scikit-learn库进行机器学习
● 将机器学习模型部署为Web服务
● 使用Microsoft Azure Machine Learning Studio进行机器学习
● 演习机器学习模型构建方案的实例
京东:https://item.jd.com/12672565.html