网站建好了怎么做淘宝客2023年8月新冠疫情
目录
一、此处需要安装第三方库requests:
二、抓包分析及编写Python代码
1、打开百度翻译的官网进行抓包分析。
2、编写请求模块
3、输出我们想要的消息
三、所有代码如下:
一、此处需要安装第三方库requests:
在Pycharm平台终端或者命令提示符窗口中输入以下代码即可安装
pip install requests二、抓包分析及编写Python代码
1、打开百度翻译的官网进行抓包分析
- 打开百度翻译的官网
- 按下F12键,打开开发者界面
- 此时由于翻译页面没有数据传输,属于静态页面,开发者界面也就没有任何数据传输的情况
- 在单词输入框中输入单词cat
- 在开发者界面中可以看到有数据正在进行传输(百度翻译是局部刷新,也就是Ajax框架的异步加载)
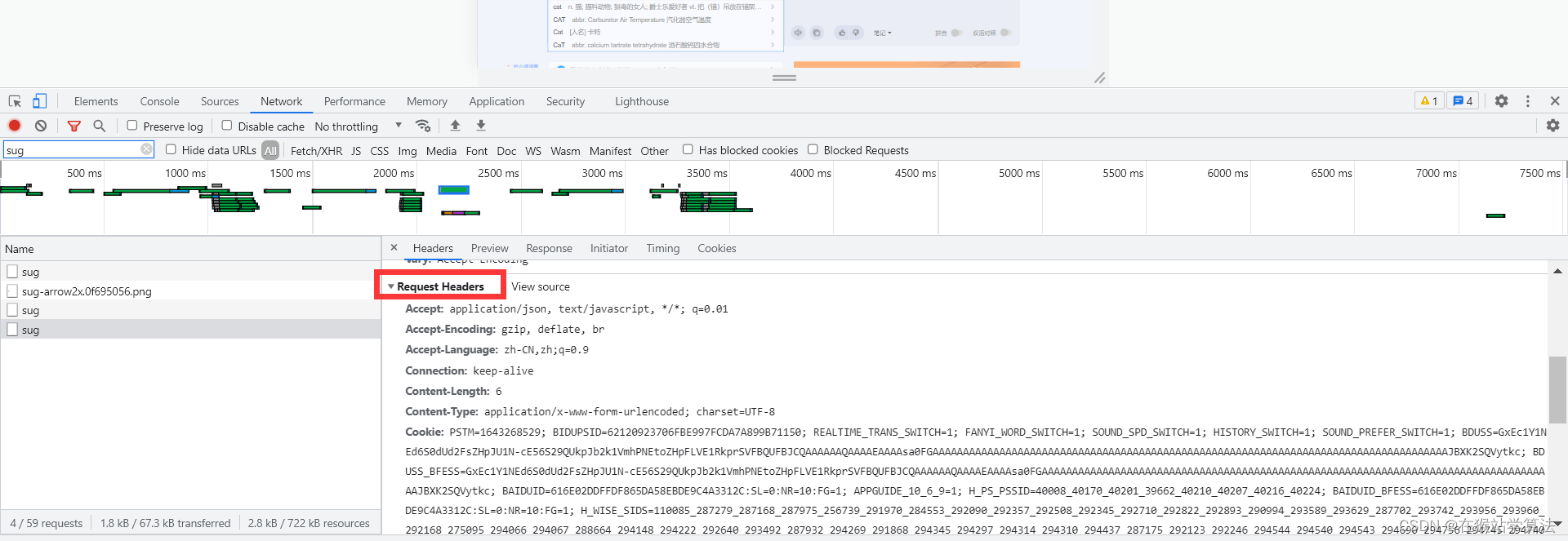
- 在过滤器中输入sug(sug是服务器响应给客户端的数据)
- 这里可以看到有3条sug,这是因为单词是由三个字母所组成的:
- 第一个sug是输入c,服务器所响应的消息,里面携带翻译c数据,在data中可以看到
- 第二个sug是输入ca,服务器所响应的消息,里面携带翻译ca数据,在data中可以看到
- 第三个sug是输入cat,服务器所响应的消息,里面携带翻译cat数据,在data中可以看到
- 如下图所示:
- 展开第三个sug中的data,可以看到翻译的数据如下:
可以看到:
- 里面除了有单词cat的翻译,还有其相似单词的翻译。
- 其中data为字典类型,k和v是key值,k为单词,v为翻译。
- 此处就是我们所需要的信息了
- 我们需要的是输入的完整单词的sug,故此处需要的是第三个sug。

2、编写请求模块
此处有两种方式编写,第一种是借助第三方网站的方式编写,第二种为自己抓包分析的方式编写。
第一种方式:此种方式比较小白,不利于对爬虫的学习。
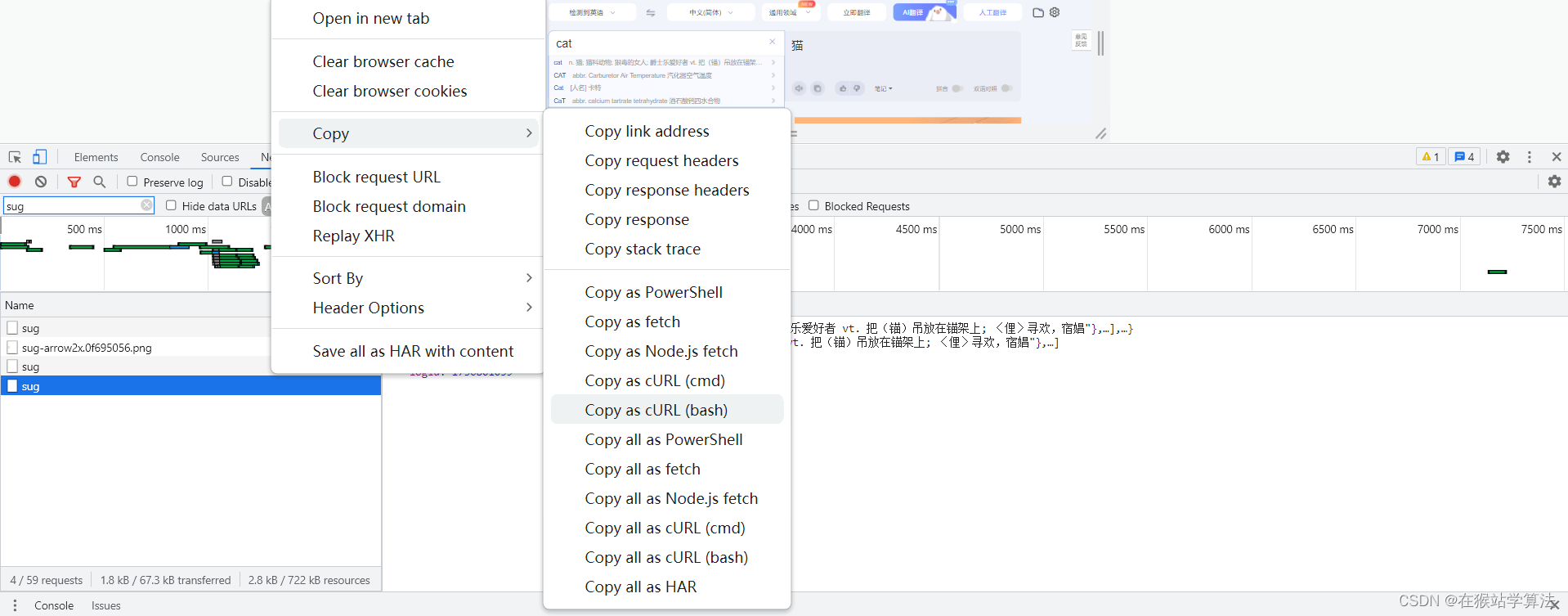
- 借助第三方网站(Convert curl commands to code)
(1)选中需要的输入的完整单词的sug,右键鼠标复制为cURL(bash)
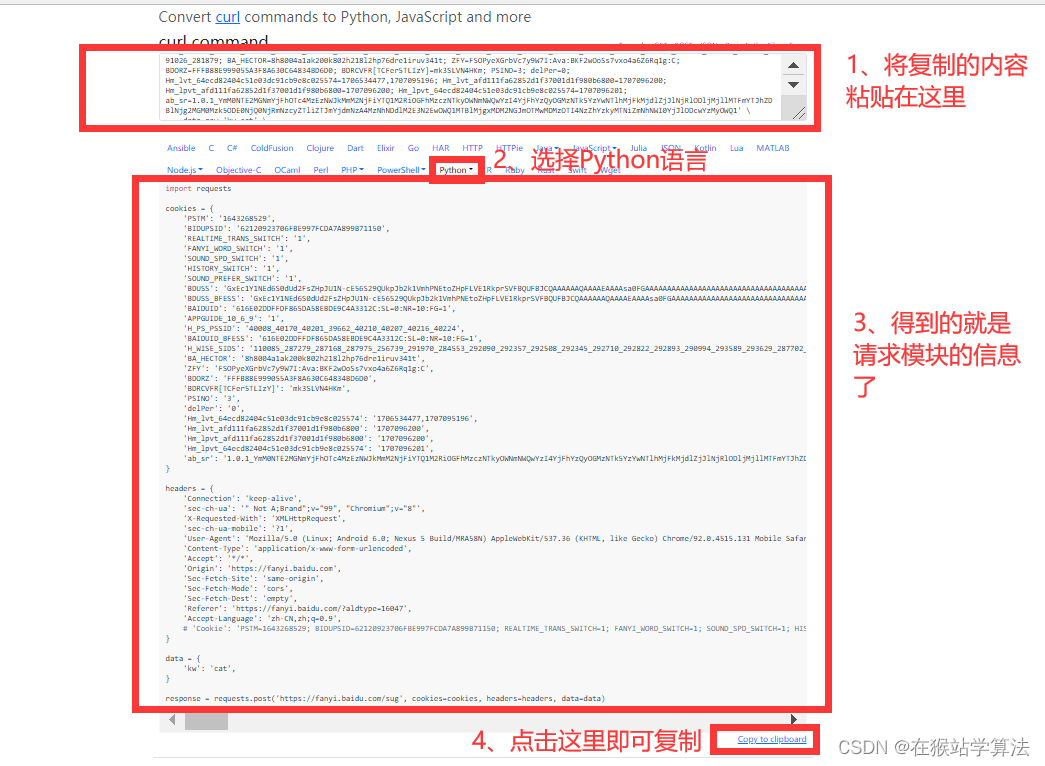
(2)打开第三方网站,复制。选择Python,即可得到请求的Python代码。
(3)复制Python代码,到Pycharm中。
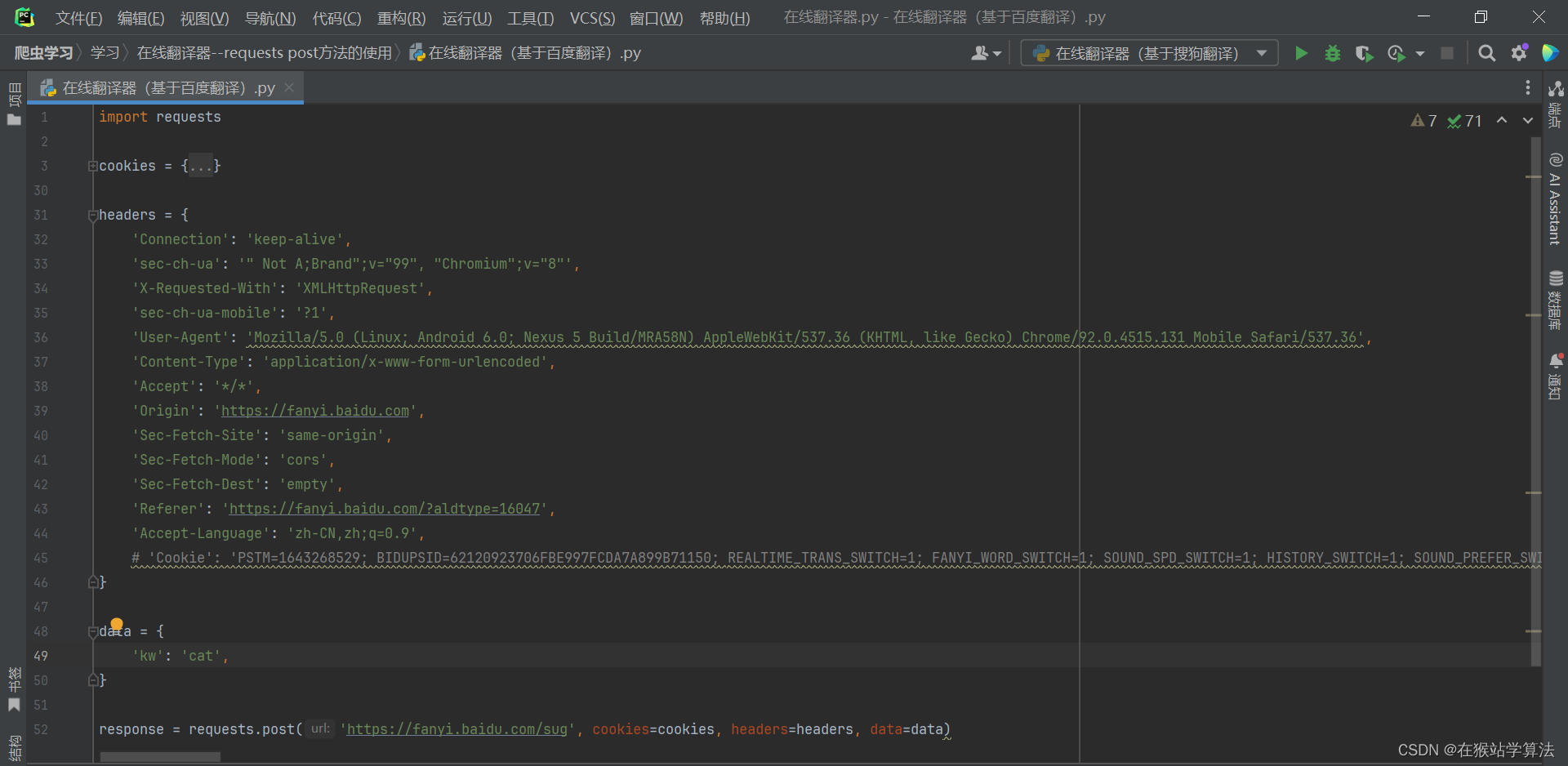
此处已经帮我们把请求头书写完了,但需要注意的是data中的kw的值为cat。也就是只翻译cat的请求信息,此处我们希望通过键盘输入需要翻译的单词来进行请求翻译。故需要进行一点修改:
keyword = input("请输入需要翻译的单词:") data = {'kw': keyword }这样就可以通过键盘来输入单词进行翻译
第二种方式:此种是自己通过抓包分析后,自己编写请求头模块,利于对爬虫的学习。
- requests请求模块有get方法和post方法,此处使用的是post方法。(不清楚的可以百度一下)
- post方法里面包含多个参数(不写的话requests模块会有默认的参数),里面需要自己写明三个参数。分别为url(访问地址),header(请求头),data(请求数据)
- 通过抓包分析我们可以知道以上三个参数:
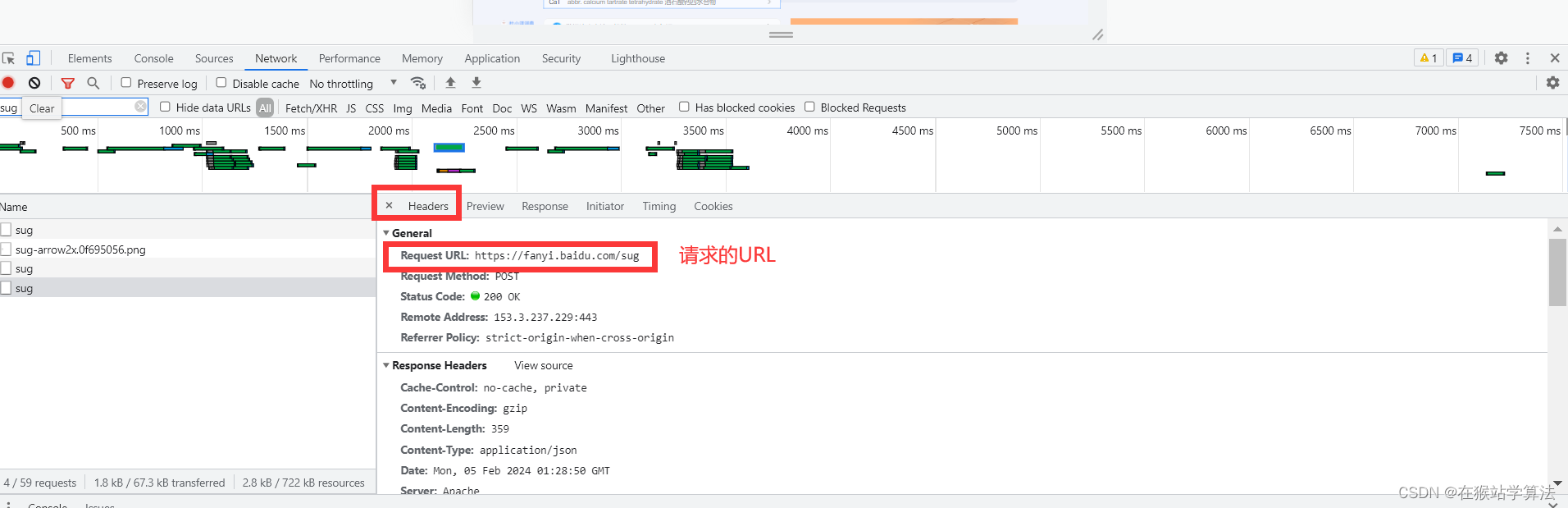
url所在位置:
header所在位置:
可以把header中的信息全部复制,以字典的类型封装为请求头。但此处只需要使用到一个关键信息--User Agent(用户身份认证),也可以只将这一个关键信息放入header中。
data所在位置:
这里我们只需要用到kw信息,将其放入到data中,以字典的形式进行存入即可。
此处的代码书写为:
# 1、导入请求模块
import requests
# 将url地址复制过来
url = "https://fanyi.baidu.com/sug"
# 2、通过键盘输入需要翻译的单词
keyword = input("请输入需要翻译的单词:")
# 3、请求数据即为输入需要翻译的单词
data = {'kw': keyword
}
# 4、header请求头装入了user—angent信息
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36'
}
# 5、使用post,按照url,header,data顺序依次写入数据
response = requests.post(url=url, headers=header, data=data)
3、输出我们想要的消息
此时,response里面所有的内容就是我们在抓包分析过程中sug中的视图内容。找到我们所需要的信息,对其进行打印即可。
- 如果只要翻译所输入的单词,不需要拓展其相关单词的翻译。
# a、如果只需要翻译单词,不需要其他相关单词及其翻译
# 将response变成字典形式并提取data中的信息
res = response.json()['data']
# 我们需要的信息是data中的第一行数据,找到后对其进行打印
print(res[0]['k']+"\t"+res[0]['v'])- 如果既要翻译所输入的单词,又需要拓展其相关单词的翻译。
# b、如果需要翻译单词,还需要其他相关单词及其翻译
# 将response变成字典形式并提取data中的信息
res = response.json()['data']
# 通过循环读取res中的k和v的值即可
for x in res:print(x['k']+"\t"+x['v'])三、所有代码如下:
# 1、导入请求模块
import requests
# 将url地址复制过来
url = "https://fanyi.baidu.com/sug"
# 2、通过键盘输入需要翻译的单词
keyword = input("请输入需要翻译的单词:")
# 3、请求数据即为输入需要翻译的单词
data = {'kw': keyword
}
# 4、header请求头装入了user—angent信息
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36'
}
# 5、使用post,按照url,header,data顺序依次写入数据
response = requests.post(url=url, headers=header, data=data)
# print(response)
# # 6、输出我么想要的信息
# # a、如果只需要翻译单词,不需要其他相关单词及其翻译
# # 将response变成字典形式并提取data中的信息
# res = response.json()['data']
# # 我们需要的信息是data中的第一行数据,找到后对其进行打印
# print(res[0]['k']+"\t"+res[0]['v'])
# b、如果需要翻译单词,还需要其他相关单词及其翻译
# 将response变成字典形式并提取data中的信息
res = response.json()['data']
# 通过循环读取res中的k和v的值即可
for x in res:print(x['k']+"\t"+x['v'])运行以上代码即可(注:运行代码时,需要保证处于联网状态。因为requests模块会对服务器进行请求,服务器会响应数据。需要联网,才能传输数据)
基于以上内容, 可以基于搜狗翻译(或其他翻译网站)进行编写PYthon3在线翻译爬虫程序。
四、基于搜狗翻译的PYthon3在线翻译爬虫程序
可以基于以上内容,自己制作一个基于搜狗翻译的PYthon3在线翻译的爬虫程序,下面给出其代码:
# 基于搜狗翻译,编程成Python爬虫程序,输入单词,进行实时翻译,并附加相关单词的翻译学习
# post方法是用于向Web服务器提交数据的HTTP请求方法。它允许客户端将数据作为请求的一部分发送给服务器,以便服务器进行处理或存储。
# 1、导入requests模块
import pprint
import requests
# 2、复制搜狗翻译的链接
query_url = 'https://fanyi.sogou.com/reventondc/suggV3'
# 3、制作请求头,模拟人的操作
keyword = input("请输入你要翻译的单词:")
data = {'from':'auto','to': 'zh-CHS','client': 'wap','text': keyword,'uuid': '21ef11c5-e2cd-49b8-a397-c89a32dd67da','pid': 'sogou-dict-vr','addSugg': 'on',
}
# 4、模拟识别码
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36'}
# 5、使用post方法进行请求
response = requests.post(url=query_url, headers=header, data=data)
# 6、提取所需要的信息
result = response.json()['sugg']
# 循环打印
for x in result:print(x['k']+': '+x['v'])注:此贴只用于学习交流,禁止商用。