什么地方可以做网站如何做好推广
论生物神经元与神经网络中的神经元联系——为什么使用激活函数?
我们将生物体中的神经元与神经网络中的神经元共同分析。从下图可以看出神经网络中的神经元与生物体中的神经元有很多相似之处,由于只有刺激达到一定的程度人体才可以感受到刺激,并且人体对刺激做出的响应是有限的,所以在输出之前应该经过激活函数。这个激活函数可以将原来发散的数据变成收敛的数据。

什么是梯度?
函数在某一点的梯度是这样一个向量,它的方向与取得最大方向导数的方向一致,而它的模为方向导数的最大值。
接下来我们将研究激活函数的梯度问题,我们将从代码实践中,获得明确的结果,更清楚激活函数的作用。
激活函数及其梯度
我们如果使用如下函数,会发现在0点函数是不可导的,我们找到一个近似此函数的分布的可导函数。

1、Sigmoid/Logistic
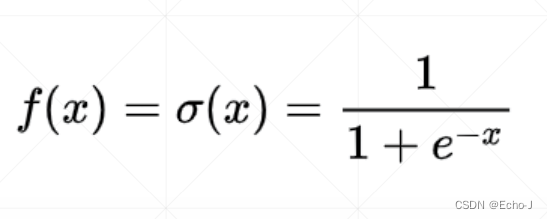
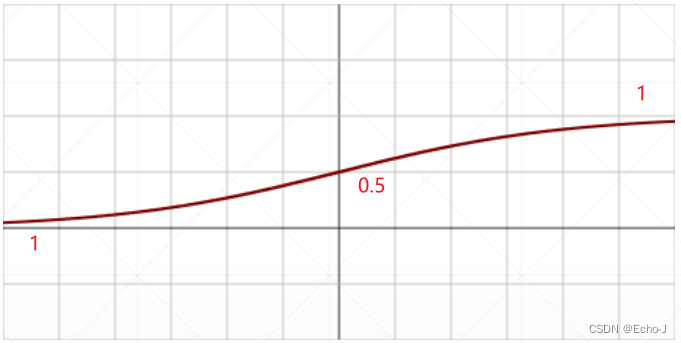
sigmoid函数的取值范围为[0, 1],因此可以使用sigmoid函数可以对数据进行压缩。
注意:由于sigmoid函数随着x的增大会逐渐趋近于1,此时sigmod的导数,就是趋近于0,就是梯度为0,在对参数进行更新的过程中我们会使用到梯度,新参数=旧参数-学习率*梯度,这就会导致参数长时间得不到更新,造成梯度离散的情况。
对sigmoid函数求导,可以得到![]() 。由于激活函数在神经网络中是已知的,因此sigmoid函数的导数也是已知的,这非常有利于我们的计算。
。由于激活函数在神经网络中是已知的,因此sigmoid函数的导数也是已知的,这非常有利于我们的计算。
代码演示:
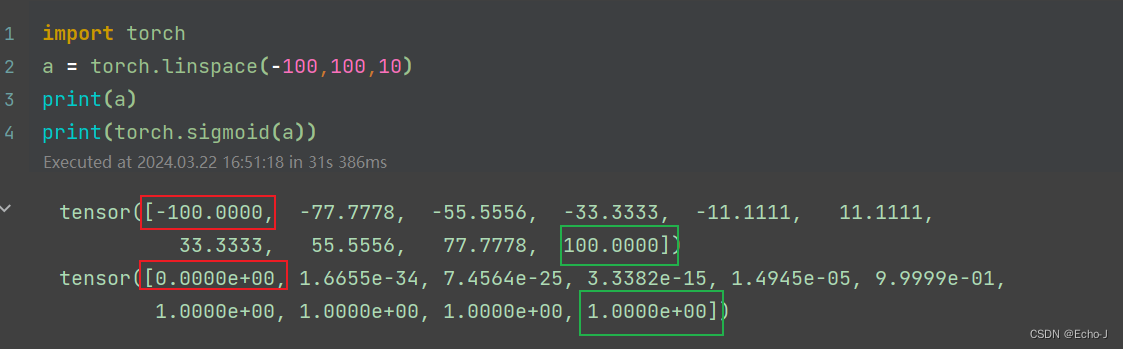
我们从代码情况中可以明显看到,经过sigmoid 函数之后所有的值都在0-1范围内,sigmoid函数的确对数据起到了一个压缩效果。
这里的torch.sigmoid()也可以使用F.sigmoid(),其中F来自于torch.nn.functional as F。
2、Tanh

对Tanh函数进行求导,得到:
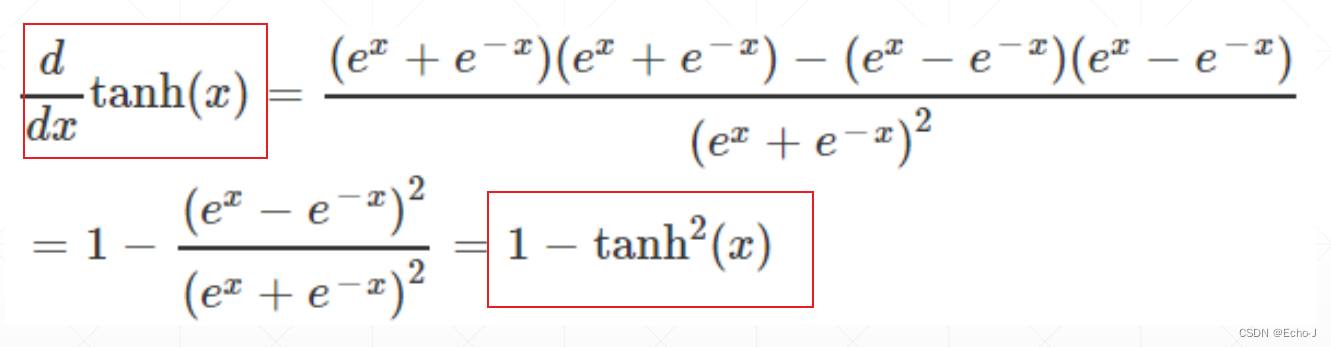
代码演示:
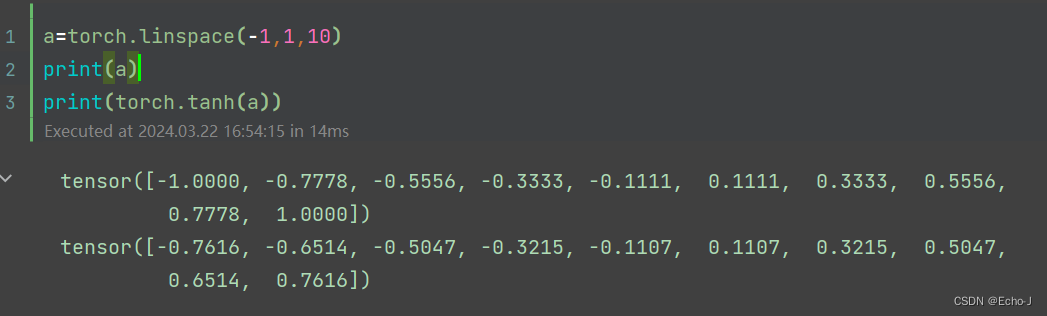
应用:RNN
3、ReLU

ReLU激活函数是我们使用最多的,因为它再一定程度上解决了梯度离散的问题,并且它的导数非常的简单,在小于0时,为0;在大于0时,为1。相对于Sigmoid激活函数,在一定情况下解决了梯度离散的情况,在现实中,它表现出来的深度学习效果也是非常好的。
对ReLU函数进行求导:

代码演示:

最后的结果,小于零的数值都取值为0,大于零的不改变。但是这个函数怎么对数据进行压缩锕?我们可以通过多个ReLU函数进行叠加,具体可以参考机器学习笔记(持续更新)-CSDN博客,ReLU函数在最后。
4、Leaky ReLU
ReLU函数再x <= 0时,导数为0,会出现梯度离散的情况,Leaky ReLU函数很好的解决了这一问题。

并且使用非常简单,直接调用LeakyReLU()函数即可,并且可以通过属性指定x <= 0时的倾斜角度,代码示例:

5、SELU
为了解决ReLU函数在x = 0时是不可导的,引入了SELU函数,这个函数是由ReLU函数和一个指数函数组合而成。

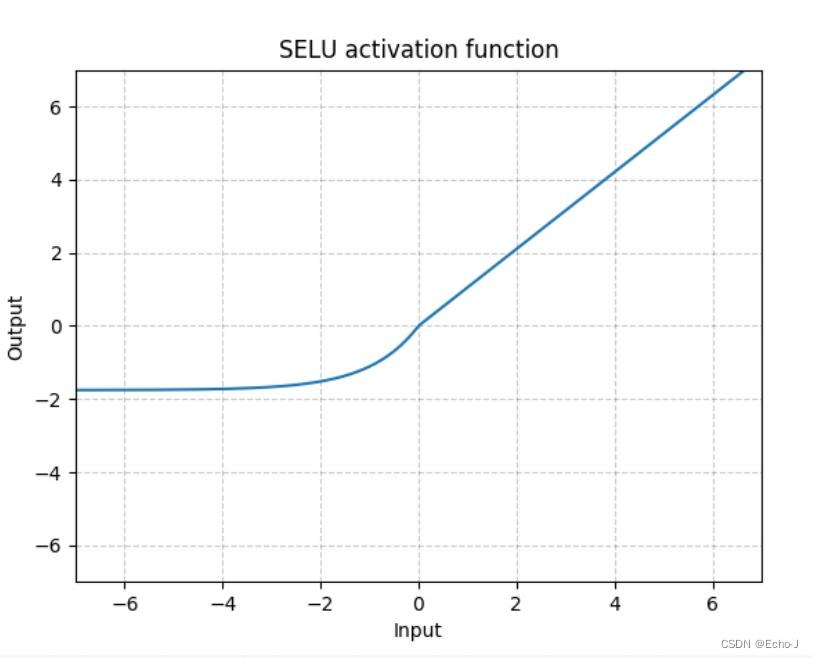
6、softplus
softplus函数在0点左右的切线正好交与原点。

Loss及其梯度
损失函数主要分为均方差损失(Mean Squared Error)、交叉熵损失(Cross Entropy Loss)。
1、MSE(Mean Squared Error)
我们使用一个线性感知机问题讨论MSE。我们来看两种损失函数计算的方式:


将模型(预测值模型)推广到任意模型,将参数统称为,对损失函数进行求导。

注意:在对w求梯度之前一定要记得对参数进行更新
(1)利用autograd.grad()求梯度:

不对w进行更新会报错element 0 of tensors does not require grad and does not have a grad_fn
蓝色标记的话就是答案,意思就是将每次的损失添加到总损失中,可以通过添加 requires_grad=True解决问题。以上代码也可以这样写,直接在w初始化时,加入requires_grad=True。

(2)利用backward()求梯度:

2、Cross Entropy Loss
交叉熵损失可以用于二分类问题、多分类问题、逻辑回归。通常使用softmax函数作为激活函数。
softmax函数:
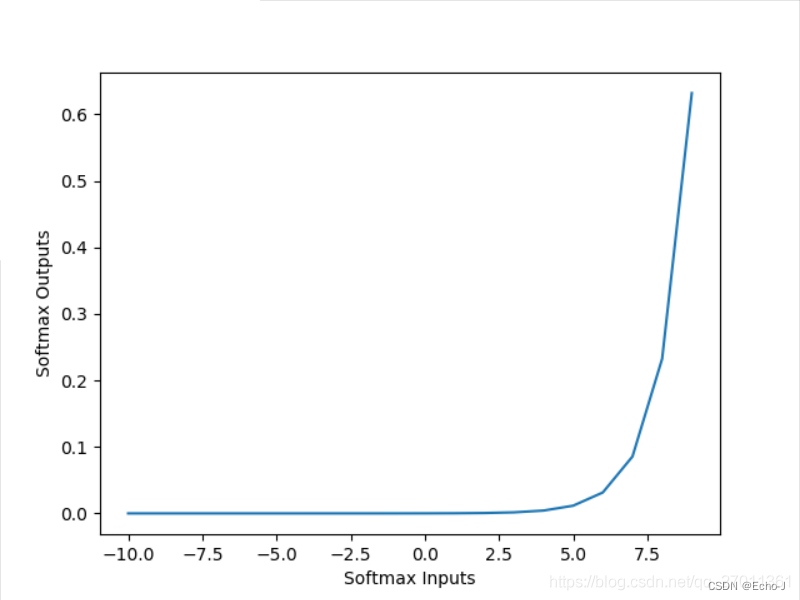

这个激活函数经常用来处理分类问题。如上图,我们对这个函数输入2、1、0.1这几个数,经过softmax函数,输出的结果为0.7、0.2、0.1范围都在0-1之间,并且总和为1。而且这个函数还起到强化的作用,在输入方2:1=2,在输出方0.7:0.2=3.5,比原来强的更强、弱的更弱。
对于此函数的导数:
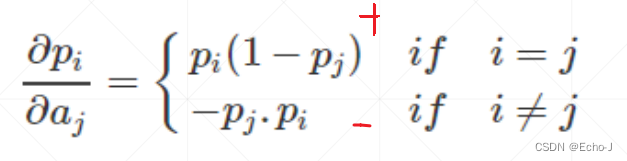
在 i = j 的时候大于0,在 i != j 的时候小于0。
代码演示:
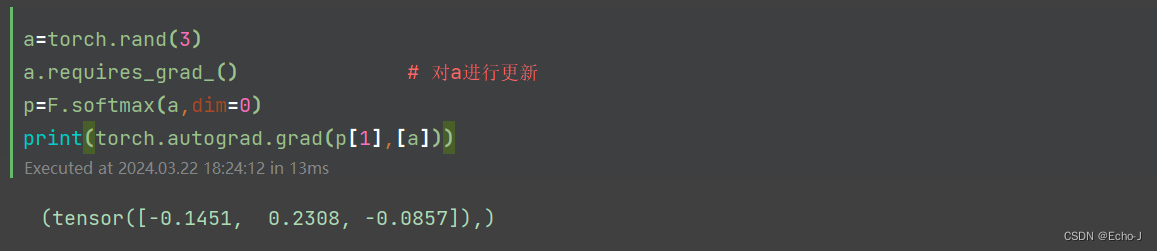
a=torch.rand(3)
a.requires_grad_() # 对a进行更新
p=F.softmax(a,dim=0)
print(p)
print(torch.autograd.grad(p[1],[a],retain_graph=True))
print(torch.autograd.grad(p[2],[a])) 为什么需要添加retain_graph=True?我想以下的回答将会为你解答:

大意就是retain_graph=True不会释放被保存的张量(不会释放中间体),而这些张量在以后计算梯度时将会被用到。导致的结果就是使用backward来计算梯度的次数不能超过一次。
我尝试了多次使用了backward来计算梯度,得到:RuntimeError: Trying to backward through the graph a second time (or directly access saved tensors after they have already been freed). Saved intermediate values of the graph are freed when you call .backward() or autograd.grad(). Specify retain_graph=True if you need to backward through the graph a second time or if you need to access saved tensors after calling backward.
代码演示:
第一次测试
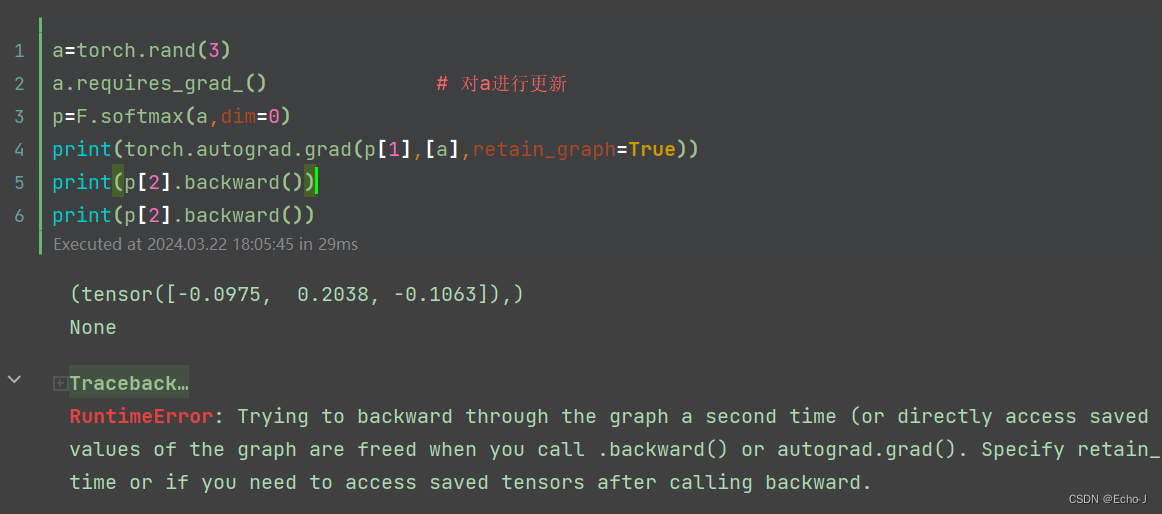
第2次测试:
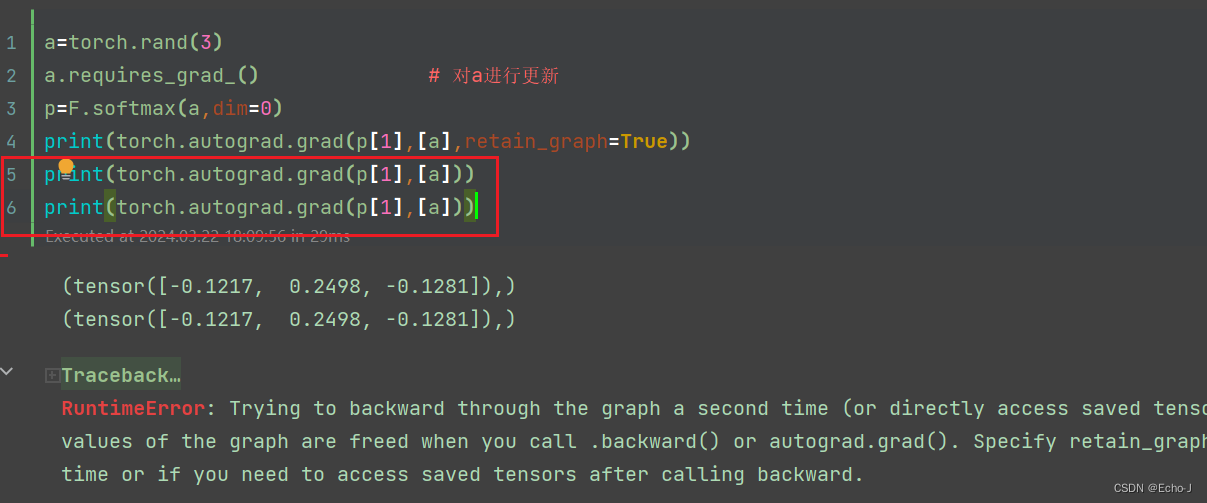
第3次测试:

第4次测试:
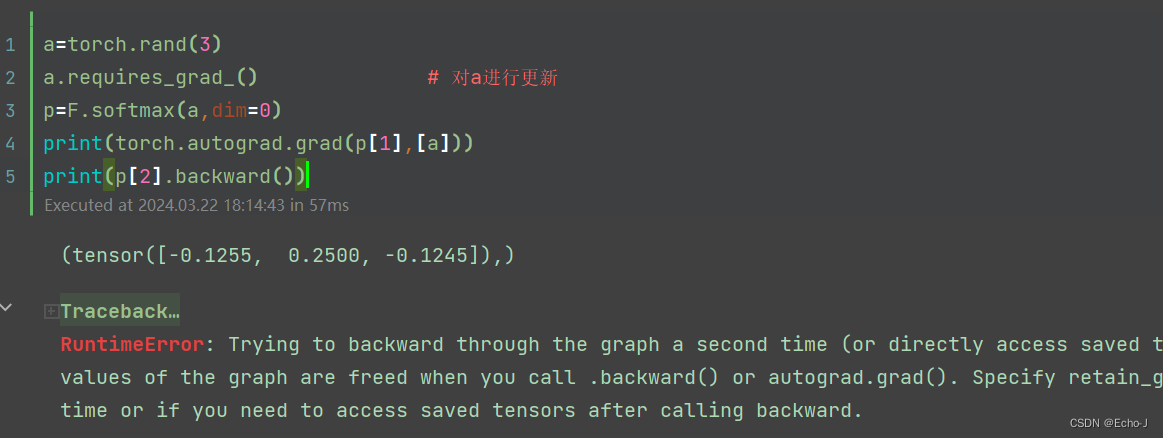 经过多次测验,我发现上面的回答是不是有问题?因此我又找了一个:
经过多次测验,我发现上面的回答是不是有问题?因此我又找了一个:
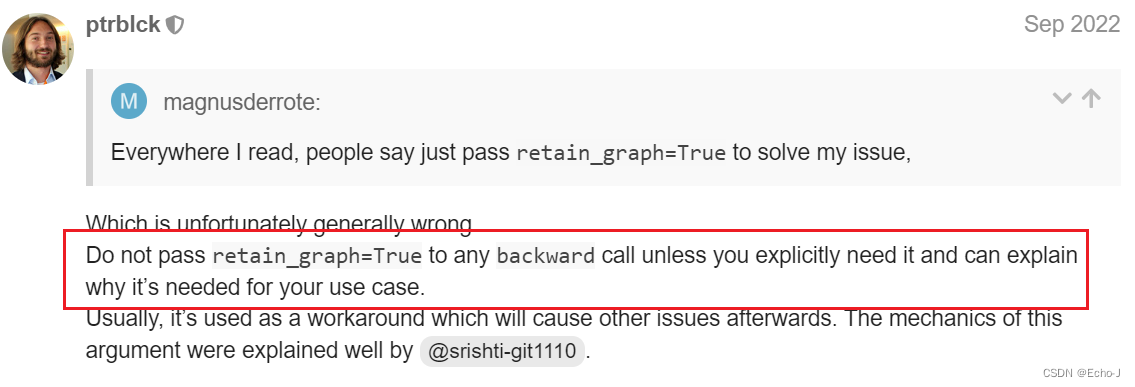
大意就是retain_graph=True非必要不使用。
因此最后的代码应该是:
如果以上内容有什么问题,欢迎指正,I would be grateful。