手机网站怎么做优化企业营销策划合同
特征缩放和学习率(多变量)
目标
- 利用上一个实验中开发的多变量例程
- 在具有多个特征的数据集上运行梯度下降
- 探索学习率对梯度下降的影响
- 通过 Z 分数归一化进行特征缩放,提高梯度下降的性能
import numpy as np
np.set_printoptions(precision=2)
import matplotlib.pyplot as plt
dlblue = '#0096ff'; dlorange = '#FF9300'; dldarkred='#C00000'; dlmagenta='#FF40FF'; dlpurple='#7030A0';
plt.style.use('./deeplearning.mplstyle')
from lab_utils_multi import load_house_data, compute_cost, run_gradient_descent
from lab_utils_multi import norm_plot, plt_contour_multi, plt_equal_scale, plot_cost_i_w
-
解释一下:
np.set_printoptions(precision=2)np.set_printoptions(precision=2)是 NumPy 中的函数,用于设置打印数组时的精度。通过设置precision参数为 2,它会将浮点数数组的打印精度限制为小数点后两位。这样可以使输出更加整洁和易读,尤其是在处理大型数组时。
问题陈述
与之前的实验类似,你将使用房价预测的示例。训练数据集包含许多具有 4 个特征(面积、卧室数、楼层数和房龄)的示例,如下表所示。请注意,在本实验中,大小特征是以平方英尺为单位的,而之前的实验中使用的是 1000 平方英尺。这个数据集比之前的实验数据集要大。
我们希望使用这些值构建一个线性回归模型,以便我们可以预测其他房屋的价格 - 比如,一所面积为 1200 平方英尺,有 3 间卧室,1 层,40 年房龄的房屋的价格。
数据集:
| 大小(平方英尺) | 卧室数 | 楼层数 | 房龄 | 价格(1000美元) |
|---|---|---|---|---|
| 952 | 2 | 1 | 65 | 271.5 |
| 1244 | 3 | 2 | 64 | 232 |
| 1947 | 3 | 2 | 17 | 509.8 |
| … | … | … | … | … |
# load the dataset
X_train, y_train = load_house_data()
X_features = ['size(sqft)','bedrooms','floors','age']
-
解释一下:
X_train, y_train = load_house_data()def load_house_data():data = np.loadtxt("./data/houses.txt", delimiter=',', skiprows=1)X = data[:,:4]y = data[:,4]return X, y这段代码定义了一个名为
load_house_data的函数,用于加载房屋数据集。函数的主要步骤如下:
- 使用 NumPy 的
loadtxt函数从指定路径的文件中加载数据集。加载的文件是一个以逗号分隔的文本文件,其中第一行是列标题,因此我们通过skiprows=1参数跳过第一行。 - 将加载的数据集分成特征矩阵
X和目标向量y。特征矩阵X包含所有行的前四列,而目标向量y包含所有行的第五列。 - 最后,函数返回特征矩阵
X和目标向量y。
通过这个函数,我们可以方便地加载房屋数据集,并将其用于训练线性回归模型。
-
data[:,:4]的含义是对二维数组
data进行的切片操作。在二维数组中,使用逗号分隔的切片操作是针对行和列进行切片的。第一个
:表示对行进行切片,第二个:4表示对列进行切片。因此,
data[:,:4]返回的是二维数组data的所有行和前四列的子数组,即一个二维的切片。
- 使用 NumPy 的
让我们通过绘制每个特征与价格的关系来查看数据集及其特征。
fig,ax=plt.subplots(1, 4, figsize=(12, 3), sharey=True)
for i in range(len(ax)):ax[i].scatter(X_train[:,i],y_train)ax[i].set_xlabel(X_features[i])
ax[0].set_ylabel("Price (1000's)")
plt.show()
-
解释一下:
sharey=Truesharey=True指定了子图共享y轴。这意味着子图将共享相同的 y 轴范围,使得它们在垂直方向上对齐,并且更容易进行比较。 -
ax是什么在Matplotlib中,
ax通常是指代图形中的坐标轴对象。在这个例子中,ax是一个包含四个子图坐标轴对象的数组。每个子图都可以在对应的坐标轴对象上进行绘图。 -
解释一下:
ax[i].scatter(X_train[:,i],y_train)ax[i].scatter(X_train[:,i],y_train):这在第 i 个子图(ax[i])上绘制了一个散点图,其中X_train[:,i]表示训练数据中所有行的第 i 个特征的值,而y_train表示目标变量(通常是价格)。它显示了每个特征与目标变量之间的个别关系。
-
解释一下:
ax[i].set_xlabel(X_features[i])ax[i].set_xlabel(X_features[i]):这将第 i 个子图的 x 轴标签设置为第 i 个特征的名称(X_features[i])。这有助于识别哪个特征正在被绘制。 -
解释一下:
ax[0].set_ylabel("Price (1000's)")这将第一个子图(因为 Python 的索引从0开始)的 y 轴标签设置为“价格(以千为单位)”。这表明目标变量表示价格,可能以千为单位。PS:因为
sharey=True,所以只用设置一个子图的 y 轴标签
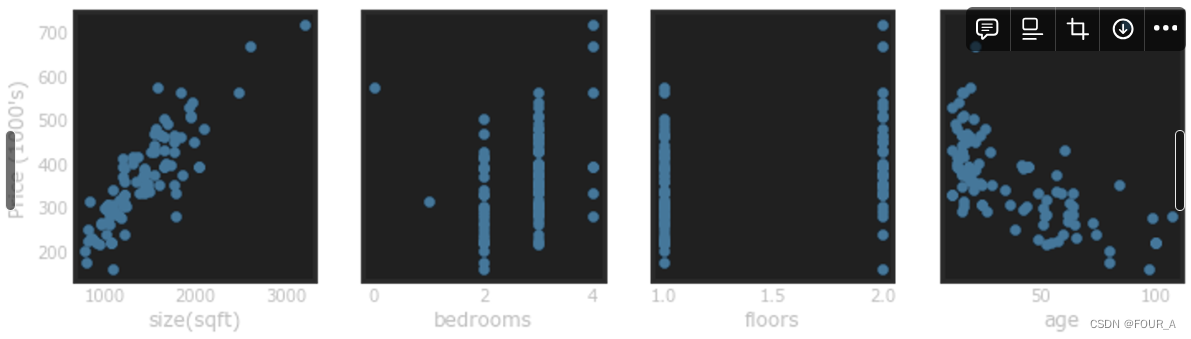
绘制每个特征与目标变量价格的图表,可以提供一些关于哪些特征对价格影响最大的线索。从上面的结果可以看出,房屋尺寸增加也会增加价格。卧室数量和楼层数似乎对价格影响不大。新房比旧房价格更高。
多变量梯度下降
以下是你在上一个实验室中开发的多变量梯度下降的方程式:
重复执行直到收敛: { w j : = w j − α ∂ J ( w , b ) ∂ w j 对于 j = 0..n-1 b : = b − α ∂ J ( w , b ) ∂ b } \begin{align*} \text{重复执行直到收敛:} \; \lbrace \newline\; & w_j := w_j - \alpha \frac{\partial J(\mathbf{w},b)}{\partial w_j} \tag{1} \; & \text{对于 j = 0..n-1}\newline & b\ \ := b - \alpha \frac{\partial J(\mathbf{w},b)}{\partial b} \newline \rbrace \end{align*} 重复执行直到收敛:{}wj:=wj−α∂wj∂J(w,b)b :=b−α∂b∂J(w,b)对于 j = 0..n-1(1)
其中, n n n 是特征数量,参数 w j w_j wj 、 b b b 同时更新,并且
∂ J ( w , b ) ∂ w j = 1 m ∑ i = 0 m − 1 ( f w , b ( x ( i ) ) − y ( i ) ) x j ( i ) ∂ J ( w , b ) ∂ b = 1 m ∑ i = 0 m − 1 ( f w , b ( x ( i ) ) − y ( i ) ) \begin{align} \frac{\partial J(\mathbf{w},b)}{\partial w_j} &= \frac{1}{m} \sum\limits_{i = 0}^{m-1} (f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)})x_{j}^{(i)} \tag{2} \\ \frac{\partial J(\mathbf{w},b)}{\partial b} &= \frac{1}{m} \sum\limits_{i = 0}^{m-1} (f_{\mathbf{w},b}(\mathbf{x}^{(i)}) - y^{(i)}) \tag{3} \end{align} ∂wj∂J(w,b)∂b∂J(w,b)=m1i=0∑m−1(fw,b(x(i))−y(i))xj(i)=m1i=0∑m−1(fw,b(x(i))−y(i))(2)(3)
- m m m 是数据集中的训练样本数量
- f w , b ( x ( i ) ) f_{\mathbf{w},b}(\mathbf{x}^{(i)}) fw,b(x(i))是模型的预测值,而 y ( i ) y^{(i)} y(i) 是目标值
学习率
在讲座中讨论了一些与设置学习率 α \alpha α 相关的问题。学习率控制了参数更新的大小。参见上面的方程 ( 1 ) (1) (1)。学习率是所有参数共享的。
让我们运行梯度下降算法,并尝试在我们的数据集上尝试几种 α \alpha α 的设置。
α = 9.9 e − 7 \alpha = 9.9e-7 α=9.9e−7
#set alpha to 9.9e-7
_, _, hist = run_gradient_descent(X_train, y_train, 10, alpha = 9.9e-7)
-
run_gradient_descent的实现:def run_gradient_descent(X,y,iterations=1000, alpha = 1e-6):m,n = X.shape # m 是训练集的个数,n 是特征值的个数(w 的个数)# initialize parametersinitial_w = np.zeros(n)initial_b = 0# run gradient descentw_out, b_out, hist_out = gradient_descent_houses(X ,y, initial_w, initial_b,compute_cost, compute_gradient_matrix, alpha, iterations)print(f"w,b found by gradient descent: w: {w_out}, b: {b_out:0.2f}")return(w_out, b_out, hist_out)
此时学习率太高了。解决方案没有收敛。成本增加而不是减少。让我们绘制结果:
plot_cost_i_w(X_train, y_train, hist)
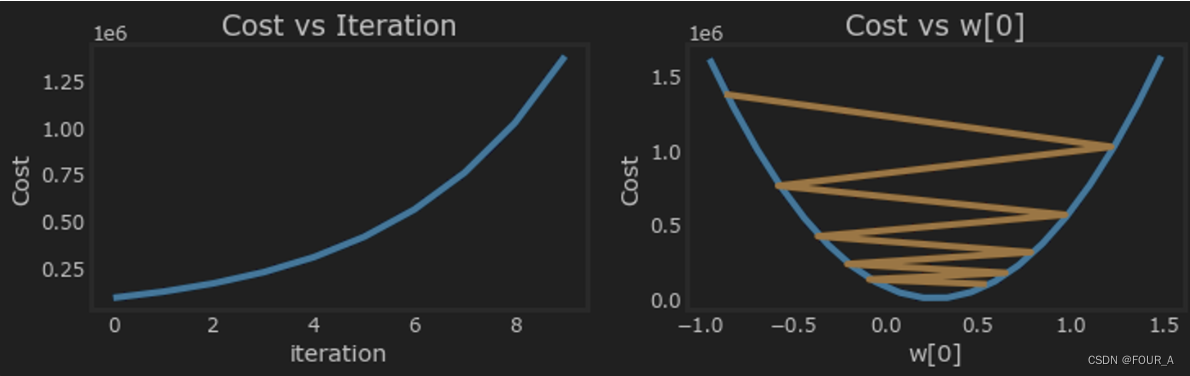
右边的图显示了其中一个参数的值。在每次迭代中,它都会超过最优值,结果导致成本增加而不是接近最小值。请注意,这不是一个完全准确的图像,因为每次迭代都会修改4个参数,而不仅仅是一个参数。此图仅显示了其中一个参数的值,而其他参数保持在良好的值。在这个和后面的图中,你可能会注意到蓝线和橙线略微偏离。
α = 1 e − 7 \alpha = 1e-7 α=1e−7
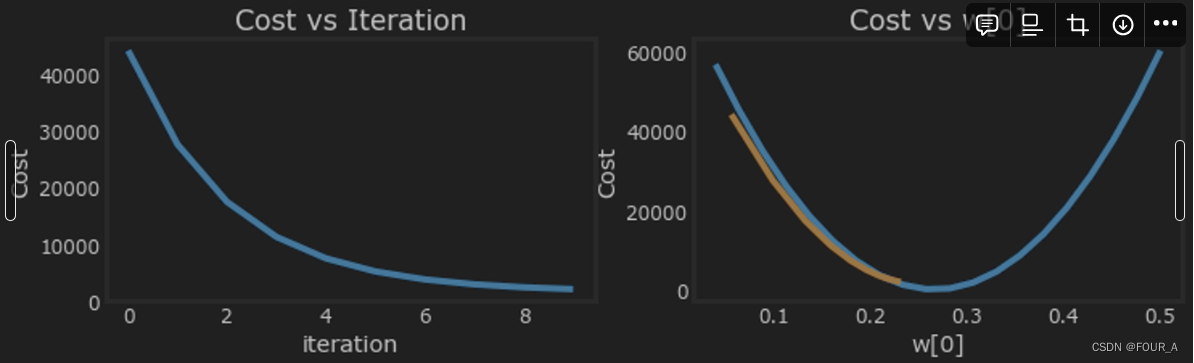
特征缩放
-
为什么要进行特征缩放
进行特征缩放的主要原因是确保不同特征具有相似的范围和尺度。这在机器学习中是很重要的,因为许多机器学习算法都假设输入特征具有相似的尺度。特征缩放有几个重要的原因:
- 加速收敛速度:在梯度下降等优化算法中,特征缩放可以使目标函数更快地收敛。如果特征具有不同的范围和尺度,那么梯度下降算法可能会在某些方向上进行更大的更新,而在其他方向上进行更小的更新,导致收敛速度变慢。
- 避免算法偏向:如果某些特征具有较大的范围,那么它们对目标函数的影响可能会比其他特征更大。这可能会导致算法更倾向于关注那些范围较大的特征,而忽略其他特征。通过进行特征缩放,可以确保所有特征对目标函数的影响是相似的,避免算法偏向。
- 提高模型性能:在某些情况下,特征缩放可以提高模型的性能。例如,在基于距离的模型(如 K 近邻算法)中,特征的尺度可以影响距离的计算。如果某些特征具有较大的尺度,那么它们可能会对距离的计算产生更大的影响,从而导致模型性能下降。通过特征缩放,可以确保所有特征对距离的计算影响相似,提高模型的性能。
三种不同的技术:
- 特征缩放,基本上是将每个特征除以用户选择的值,以使其范围介于 -1 和 1 之间。
- 均值归一化: x i : = x i − μ i m a x − m i n x_i := \dfrac{x_i - \mu_i}{max - min} xi:=max−minxi−μi
- Z 分数归一化
Z 分数归一化
经过 Z 分数归一化后,所有特征的均值将为 0,标准差为 1。
要实现 Z 分数归一化,调整输入值如下所示的公式:
x j ( i ) = x j ( i ) − μ j σ j (4) x^{(i)}_j = \dfrac{x^{(i)}_j - \mu_j}{\sigma_j} \tag{4} xj(i)=σjxj(i)−μj(4)
其中, j j j 是矩阵 X X X 中的一个特征或列
µ j µ_j µj 是特征 ( j ) (j) (j)所有值的均值
∗ σ j *\sigma_j ∗σj 是特征 ( j ) (j) (j)的**标准差。***
μ j = 1 m ∑ i = 0 m − 1 x j ( i ) σ j 2 = 1 m ∑ i = 0 m − 1 ( x j ( i ) − μ j ) 2 \begin{align} \mu_j &= \frac{1}{m} \sum_{i=0}^{m-1} x^{(i)}_j \tag{5}\\ \sigma^2_j &= \frac{1}{m} \sum_{i=0}^{m-1} (x^{(i)}_j - \mu_j)^2 \tag{6} \end{align} μjσj2=m1i=0∑m−1xj(i)=m1i=0∑m−1(xj(i)−μj)2(5)(6)
实现注意: 当对特征进行归一化时,重要的是存储用于归一化的值 - 均值和标准差用于计算。在从模型中学习参数后,我们通常希望预测之前未见过的房屋价格。给定一个新的 x 值(客厅面积和卧室数量),我们必须首先使用之前从训练集中计算得到的均值和标准差来归一化 x。
实现
def zscore_normalize_features(X):# 计算每个特征的均值mu = np.mean(X, axis=0) # mu will have shape (n,)# 计算每个特征的标准差sigma = np.std(X, axis=0) # sigma will have shape (n,)# 进行归一化操作X_norm = (X - mu) / sigma return (X_norm, mu, sigma)#check our work
#from sklearn.preprocessing import scale
#scale(X_orig, axis=0, with_mean=True, with_std=True, copy=True)
-
解释一下:
scale(X_orig, axis=0, with_mean=True, with_std=True, copy=True)这段代码使用了 scikit-learn 中的
scale函数,该函数用于对输入数据进行标准化处理。下面是对该函数的参数进行解释:X_orig:要进行标准化处理的输入数据。通常是一个二维数组,其中每一行代表一个样本,每一列代表一个特征。axis:标准化处理的轴向。默认值为 0,表示对每一列进行标准化处理,即计算每个特征的均值和标准差,并将数据标准化为均值为 0、标准差为 1 的分布。如果设置为 1,表示对每一行进行标准化处理。with_mean:是否对数据进行均值归一化。默认值为 True,表示将数据减去均值,使得均值为 0。with_std:是否对数据进行标准差归一化。默认值为 True,表示将数据除以标准差,使得标准差为 1。copy:是否复制输入数据。默认值为 True,表示将原始数据进行复制,不修改原始数据。如果设置为 False,表示在原始数据上直接进行修改。
综合起来,这段代码的作用是对输入数据进行标准化处理,使得每个特征的均值为 0,标准差为 1,以及可选择是否对数据进行均值归一化和标准差归一化。
下面的图显示了逐步的转换过程。
mu = np.mean(X_train,axis=0)
sigma = np.std(X_train,axis=0)
X_mean = (X_train - mu)
X_norm = (X_train - mu)/sigma fig,ax=plt.subplots(1, 3, figsize=(12, 3))
ax[0].scatter(X_train[:,0], X_train[:,3])
ax[0].set_xlabel(X_features[0]); ax[0].set_ylabel(X_features[3]);
ax[0].set_title("unnormalized")
ax[0].axis('equal')ax[1].scatter(X_mean[:,0], X_mean[:,3])
ax[1].set_xlabel(X_features[0]); ax[0].set_ylabel(X_features[3]);
ax[1].set_title(r"X - $\mu$")
ax[1].axis('equal')ax[2].scatter(X_norm[:,0], X_norm[:,3])
ax[2].set_xlabel(X_features[0]); ax[0].set_ylabel(X_features[3]);
ax[2].set_title(r"Z-score normalized")
ax[2].axis('equal')
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
fig.suptitle("distribution of features before, during, after normalization")
plt.show()
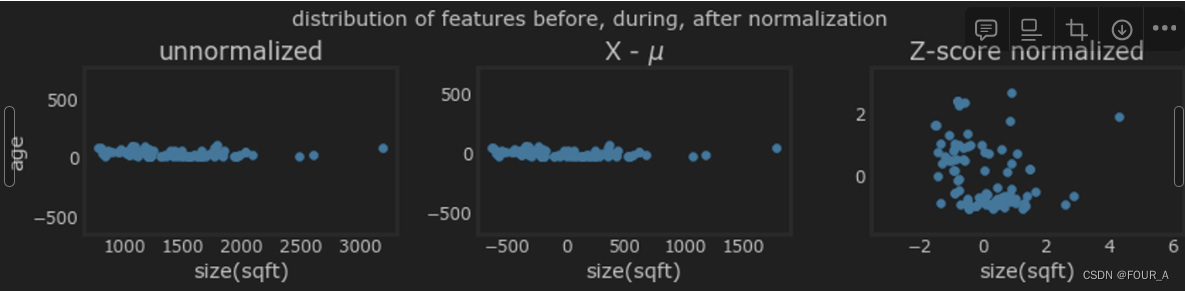
上面的图显示了训练集中两个参数之间的关系,“age” 和 “sqft”。这些图绘制的比例相等。
- 左侧:未归一化:‘size(sqft)’ 特征的值范围或方差远大于 ‘age’ 特征的值范围或方差。
- 中间:第一步去除了每个特征的平均值或均值。这使得特征围绕零中心。很难看出 ‘age’ 特征的差异,但 ‘size(sqft)’ 明显围绕零中心。
- 右侧:第二步除以方差。这使得两个特征都围绕零中心,并且具有相似的尺度。
让我们对数据进行归一化,并将其与原始数据进行比较。
# normalize the original features
X_norm, X_mu, X_sigma = zscore_normalize_features(X_train)
print(f"X_mu = {X_mu}, \nX_sigma = {X_sigma}")
print(f"Peak to Peak range by column in Raw X:{np.ptp(X_train,axis=0)}")
print(f"Peak to Peak range by column in Normalized X:{np.ptp(X_norm,axis=0)}")
通过归一化,每列的峰值范围从数千的因子减少到 2-3 的因子。
fig,ax=plt.subplots(1, 4, figsize=(12, 3))# 对第 i 列的特征进行归一化,并绘图
for i in range(len(ax)):norm_plot(ax[i],X_train[:,i],)ax[i].set_xlabel(X_features[i])ax[0].set_ylabel("count");
fig.suptitle("distribution of features before normalization")
plt.show()

请注意,上面归一化后的数据范围围绕零中心,大致在 +/- 1 范围内。最重要的是,每个特征的范围相似。
让我们使用归一化后的数据重新运行梯度下降算法。请注意学习率 α \alpha α 的值大大增加了。这将加速下降过程。
w_norm, b_norm, hist = run_gradient_descent(X_norm, y_train, 1000, 1.0e-1, )
通过归一化后的特征,我们可以在更快的时间内获得非常准确的结果!请注意,在这个相当短的运行过程结束时,每个参数的梯度都变得非常小。对于使用归一化特征的回归问题,学习率 0.1 是一个很好的起点。
让我们绘制我们的预测值与目标值的对比图。请注意,预测是使用归一化后的特征进行的,而绘图是使用原始特征值进行的。
# 用归一化后的特征得到的预测值
m = X_norm.shape[0] # m 是数据量
yp = np.zeros(m) # yp 是预测的价格# 使用归一化后的特征 X_norm[i] 与归一化后的权重 w_norm 进行点乘,再加上归一化后的偏置 b_norm,得到预测的价格。
for i in range(m):yp[i] = np.dot(X_norm[i], w_norm) + b_norm# 将原始特征值与预测值绘制在同一图表中,用于对比
fig,ax=plt.subplots(1,4,figsize=(12, 3),sharey=True)
for i in range(len(ax)):ax[i].scatter(X_train[:,i],y_train, label = 'target')ax[i].set_xlabel(X_features[i])ax[i].scatter(X_train[:,i],yp,color=dlorange, label = 'predict')
ax[0].set_ylabel("Price"); ax[0].legend();
fig.suptitle("target versus prediction using z-score normalized model")
plt.show()
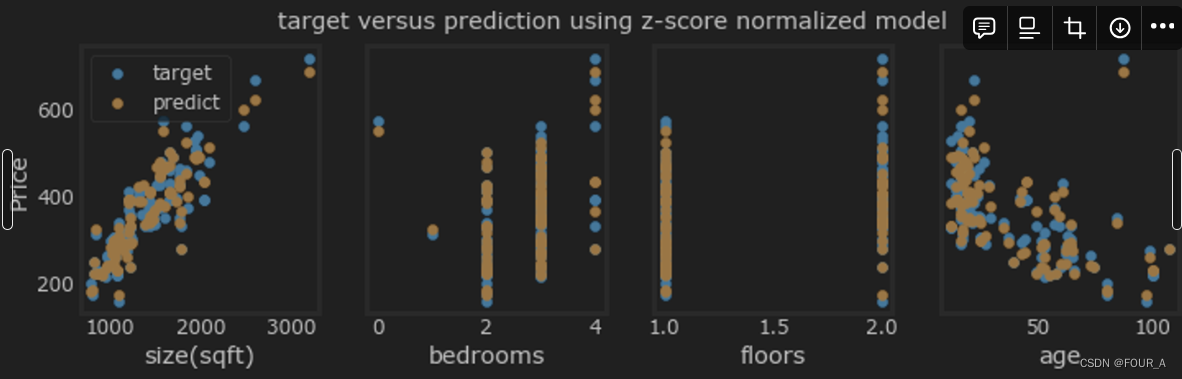
结果看起来不错。需要注意几点:
- 当使用多个特征时,我们不能再使用单个图表显示结果与特征的关系。
- 在生成图表时,使用了归一化后的特征。任何使用从归一化训练集学习到的参数进行的预测都必须使用归一化的特征。
**预测:**生成我们的模型的目的是使用它来预测不在数据集中的房屋价格。让我们预测一间具有 1200 平方英尺、3 间卧室、1 层、40 年历史的房屋的价格。请记住,在使用模型进行预测之前,必须使用训练数据归一化时得到的均值和标准差对数据进行归一化处理。
# 首先,归一化需要预测的样本
x_house = np.array([1200, 3, 1, 40])
x_house_norm = (x_house - X_mu) / X_sigma
print(x_house_norm)
x_house_predict = np.dot(x_house_norm, w_norm) + b_norm
print(f" predicted price of a house with 1200 sqft, 3 bedrooms, 1 floor, 40 years old = ${x_house_predict*1000:0.0f}")
代价轮廓
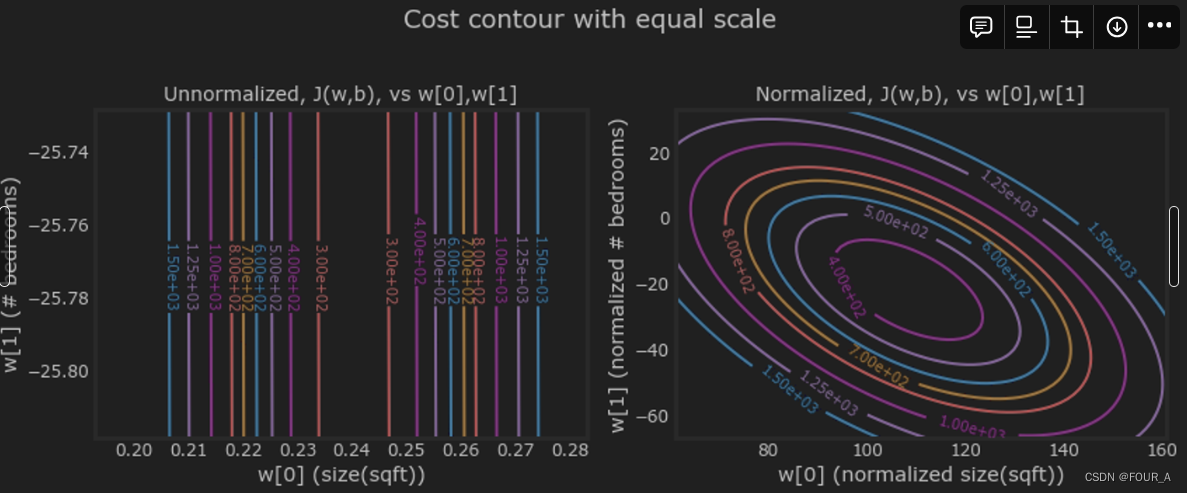
另一种观察特征缩放的方式是通过代价轮廓。当特征的尺度不匹配时,在轮廓图中绘制的代价与参数之间的关系是不对称的。
在下面的图中,参数的尺度是匹配的。左图是在归一化特征之前对房屋面积 w[0] 与卧室数量 w[1] 的代价轮廓图。由于不对称,完成轮廓的曲线并不可见。相比之下,当特征归一化时,代价轮廓更加对称。结果是在梯度下降过程中,参数的更新可以使每个参数取得相同的进展。
plt_equal_scale(X_train, X_norm, y_train)
小结
- 利用之前实验中开发的具有多个特征的线性回归例程
- 探索学习率 α \alpha α 对收敛性的影响
- 发现使用 Z 分数归一化进行特征缩放在加速收敛方面的价值