nas可以做网站服务器软文营销网站
PEFT (Parameter-Efficient Fine-Tuning) 参数高效微调是一种针对大模型微调的技术,旨在减少微调过程中需要调整的参数量,同时保持或提高模型的性能。
以LORA、Adapter Tuning 和 Prompt Tuning 为主的PEFT方法总结如下

LORA
- 论文题目:LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
- 论文链接:https://arxiv.org/pdf/2106.09685
- 发表时间:2021.10.16

含义
一种用于微调大型预训练语言模型(如GPT-3或BERT)的方法。核心思想是在模型的关键层中添加小型、低秩的矩阵来调整模型的行为,而不是直接改变整个模型的结构。
原理
低秩矩阵分解: LoRA通过将权重矩阵分解为两个较低秩的矩阵来减少参数量。具体来说,对于模型中的某个权重矩阵 W,LoRA将其表示为两个较小的矩阵 A 和 B,使得 W≈A×B。这样可以有效地减少需要更新的参数数量。
保持预训练权重不变: LoRA保留了预训练模型的原始权重,并在此基础上进行调整。通过添加低秩更新矩阵 ΔW=A×B 到原始权重矩阵 W,来得到新的权重矩阵 W′=W+ΔW。这种方法允许模型在保留预训练知识的同时,适应新的任务。
Adapter Tuning
- 论文题目:Parameter-Efficient Transfer Learning for NLP
- 论文链接:https://arxiv.org/pdf/1902.00751
- 发表时间:2019.6.13

含义
通过在预训练模型的基础上添加适配器层(adapters),来实现特定任务的微调。这种方法旨在保留预训练模型的原始权重,仅在需要适应新任务的地方进行小规模的参数调整。
原理
插入适配器层: 在预训练模型的特定位置(通常是在每个 Transformer 层的内部或后面)插入适配器层。
适配器层结构: 这些适配器层是一些小规模的神经网络,通常由一个下采样层(减少维度)、一个激活函数(如 ReLU)和一个上采样层(恢复维度)组成。
冻结预训练权重: 在微调过程中,预训练模型的原始权重保持不变,仅训练适配器层的权重。
高效微调: 由于适配器层的参数数量相对较少,微调过程变得更加高效。适配器层可以针对不同任务进行训练,而不影响预训练模型的核心结构。
Prompt Tuning
- 论文题目:The Power of Scale for Parameter-Efficient Prompt Tuning
- 论文链接:https://arxiv.org/pdf/2104.08691
- 发表时间:2021.9.2
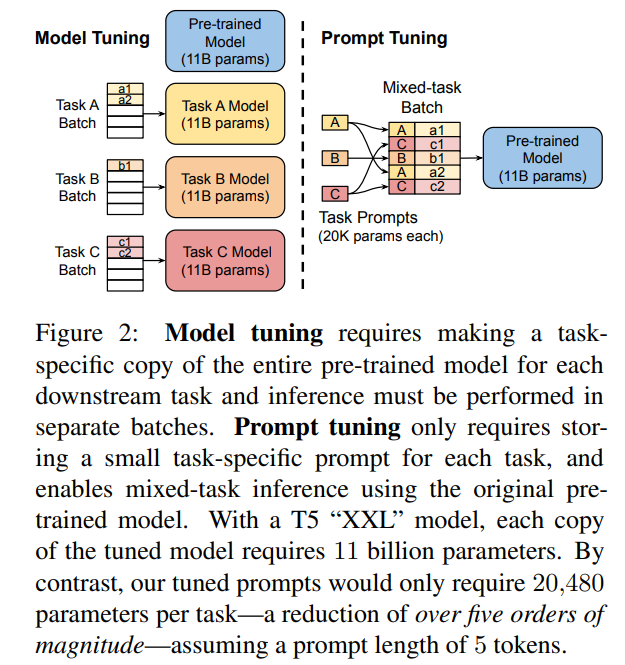
含义
在预训练语言模型的输入中添加可学习的嵌入向量作为提示。其核心思想是通过引入任务特定的提示(prompts),而非对整个模型进行全参数更新,从而实现对模型的高效微调
原理
设计提示词: 输入提示(prompt)通常包含任务描述、示例或特定的输入格式。例如,对于情感分类任务,可以设计一个提示词:“这段文字的情感是:”。
优化提示词: Prompt Tuning 的优化对象是输入提示的词嵌入(embedding)。通过梯度下降等优化算法,调整提示词的词嵌入,使得模型在特定任务上的表现达到最优。
冻结预训练模型: 在 Prompt Tuning 中,预训练模型的权重保持不变,仅优化提示词的嵌入。
Prefix-Tuning
- 论文题目:Prefix-Tuning: Optimizing Continuous Prompts for Generation
- 论文链接:https://arxiv.org/pdf/2101.00190
- 发表时间:2021.1.1
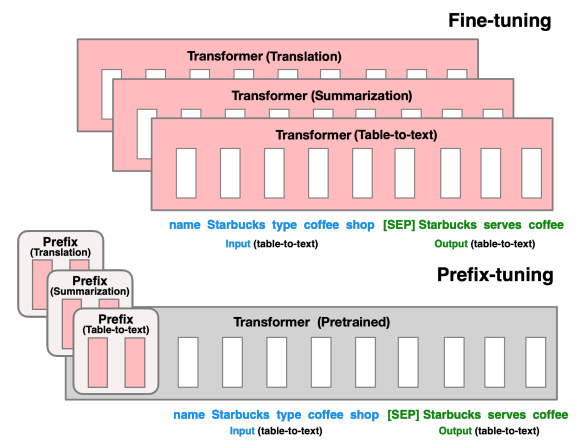
含义
通过固定预训练模型的参数,仅在输入序列的前面添加一个可训练的前缀(prefix),从而在不改变模型参数的情况下实现特定任务的适应
原理
固定模型参数: 不对预训练语言模型(如 GPT-3、BERT 等)的参数进行微调
添加可训练前缀: 在输入序列的前面添加一个可训练的前缀向量。这个前缀向量的长度和维度可以根据具体任务进行调整
任务适应: 在实际应用中,前缀向量与输入序列一起输入到预训练模型中。由于前缀向量是可训练的,模型可以通过调整前缀向量来适应特定的任务,而无需改变模型本身的参数。
P-Tuning
-
论文题目:GPT Understands, Too
-
论文链接:https://arxiv.org/pdf/2103.10385v1
-
发表时间:2021.3.18
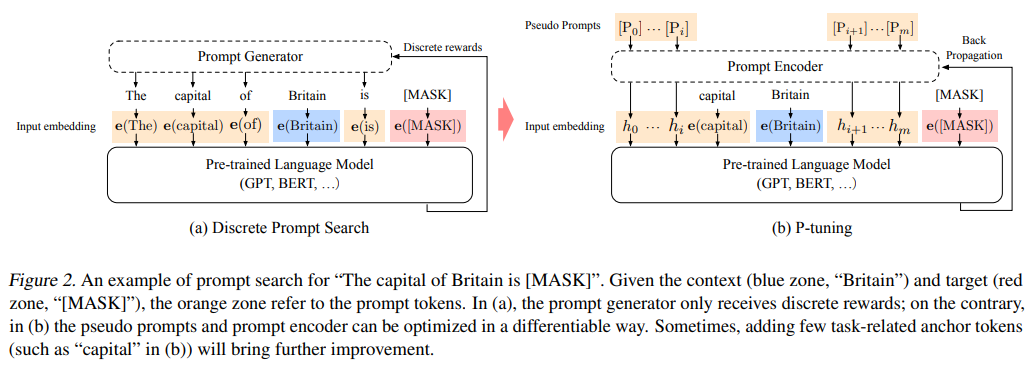
含义
在模型输入中插入一些可训练的提示(prompts),这些提示是嵌入向量(embedding vectors),在训练过程中被优化
原理
固定模型参数: 和 Prefix-Tuning 类似,不改模型参数
插入可训练提示: 在输入序列的适当位置插入一些可训练的提示向量。
任务适应: 在训练过程中,这些提示向量与输入序列一起输入到预训练模型中
P-Tuning V2
- 论文题目:P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
- 论文链接:https://arxiv.org/pdf/2110.07602v2
- 发表时间:2021.10.18
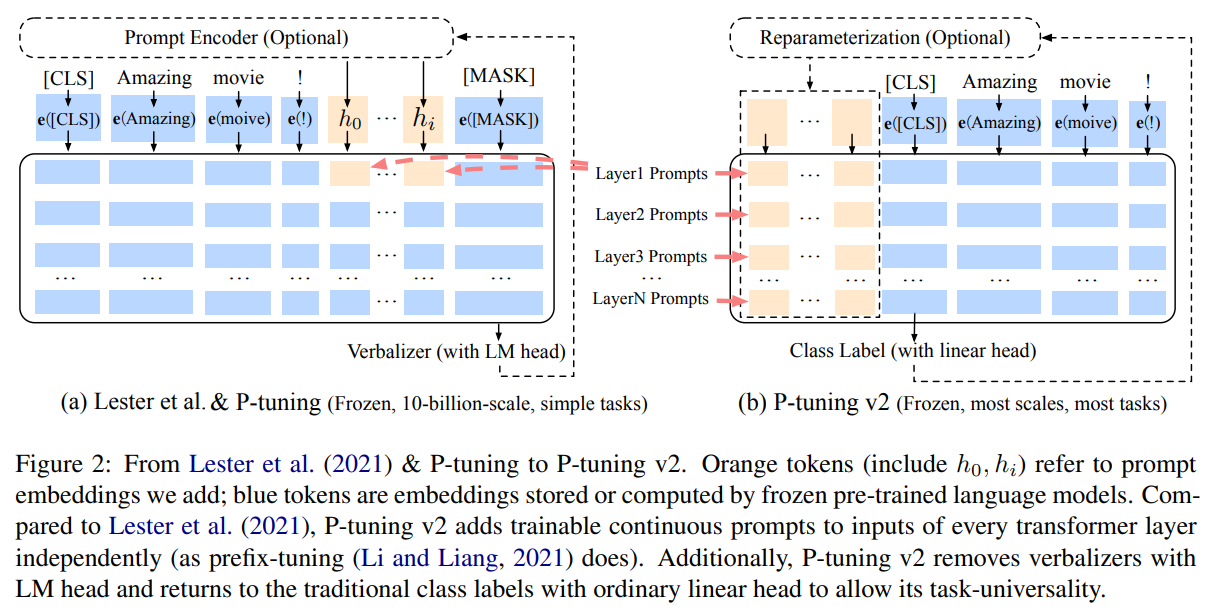
含义
保留了 P-Tuning 的核心思想,即通过优化输入提示向量来引导预训练模型处理特定任务
原理
相比较于P-Tuning:
动态提示优化: 采用动态提示优化方法
多层提示插入: P-Tuning V2 不仅在输入序列的前面插入提示向量,还在模型的不同层次(如中间层)插入提示向量
BitFit
- 论文题目:BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models
- 论文链接:https://arxiv.org/abs/2106.10199
- 发表时间:2021.6.18
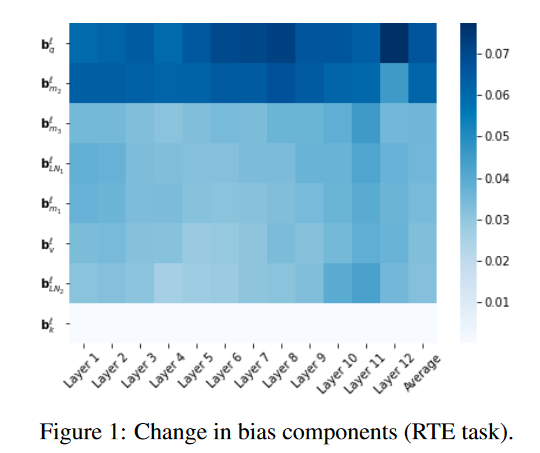
含义
通过仅微调模型的偏置参数来适应新的任务,从而减少了需要调整的参数量。
原理
-
原始 BERT 模型:包含多层 Transformer,每层有权重矩阵 W 和偏置 b。
-
BitFit 微调:保持所有权重矩阵 W 不变,只微调每层的偏置参数 b
DistilBERT
- 论文题目:DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
- 论文链接:https://arxiv.org/abs/1910.01108
- 发表时间:2020.3.1
含义
使用知识蒸馏技术将大模型压缩成更小的模型,从而减少微调所需的计算资源和时间。
原理
知识蒸馏是一种模型压缩技术,通过训练一个较小的学生模型(student model)来模仿较大教师模型(teacher model)的行为。具体步骤如下:
- 教师模型:使用预训练的 BERT 模型作为教师模型。
- 学生模型:构建一个较小的 BERT 模型,即 DistilBERT。
- 训练过程:在训练过程中,学生模型通过模仿教师模型的输出来学习。损失函数不仅包括学生模型和教师模型输出之间的差异,还包括学生模型和真实标签之间的差异。> PEFT (Parameter-Efficient Fine-Tuning) 参数高效微调是一种针对大模型微调的技术,旨在减少微调过程中需要调整的参数量,同时保持或提高模型的性能。
以LORA、Adapter Tuning 和 Prompt Tuning 为主的PEFT方法总结如下

LORA
- 论文题目:LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
- 论文链接:https://arxiv.org/pdf/2106.09685
- 发表时间:2021.10.16
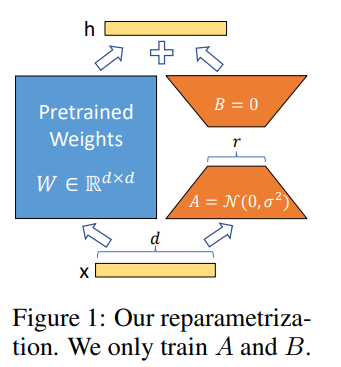
含义
一种用于微调大型预训练语言模型(如GPT-3或BERT)的方法。核心思想是在模型的关键层中添加小型、低秩的矩阵来调整模型的行为,而不是直接改变整个模型的结构。
原理
低秩矩阵分解: LoRA通过将权重矩阵分解为两个较低秩的矩阵来减少参数量。具体来说,对于模型中的某个权重矩阵 W,LoRA将其表示为两个较小的矩阵 A 和 B,使得 W≈A×B。这样可以有效地减少需要更新的参数数量。
保持预训练权重不变: LoRA保留了预训练模型的原始权重,并在此基础上进行调整。通过添加低秩更新矩阵 ΔW=A×B 到原始权重矩阵 W,来得到新的权重矩阵 W′=W+ΔW。这种方法允许模型在保留预训练知识的同时,适应新的任务。
Adapter Tuning
- 论文题目:Parameter-Efficient Transfer Learning for NLP
- 论文链接:https://arxiv.org/pdf/1902.00751
- 发表时间:2019.6.13
含义
通过在预训练模型的基础上添加适配器层(adapters),来实现特定任务的微调。这种方法旨在保留预训练模型的原始权重,仅在需要适应新任务的地方进行小规模的参数调整。
原理
插入适配器层: 在预训练模型的特定位置(通常是在每个 Transformer 层的内部或后面)插入适配器层。
适配器层结构: 这些适配器层是一些小规模的神经网络,通常由一个下采样层(减少维度)、一个激活函数(如 ReLU)和一个上采样层(恢复维度)组成。
冻结预训练权重: 在微调过程中,预训练模型的原始权重保持不变,仅训练适配器层的权重。
高效微调: 由于适配器层的参数数量相对较少,微调过程变得更加高效。适配器层可以针对不同任务进行训练,而不影响预训练模型的核心结构。
Prompt Tuning
- 论文题目:The Power of Scale for Parameter-Efficient Prompt Tuning
- 论文链接:https://arxiv.org/pdf/2104.08691
- 发表时间:2021.9.2
含义
在预训练语言模型的输入中添加可学习的嵌入向量作为提示。其核心思想是通过引入任务特定的提示(prompts),而非对整个模型进行全参数更新,从而实现对模型的高效微调
原理
设计提示词: 输入提示(prompt)通常包含任务描述、示例或特定的输入格式。例如,对于情感分类任务,可以设计一个提示词:“这段文字的情感是:”。
优化提示词: Prompt Tuning 的优化对象是输入提示的词嵌入(embedding)。通过梯度下降等优化算法,调整提示词的词嵌入,使得模型在特定任务上的表现达到最优。
冻结预训练模型: 在 Prompt Tuning 中,预训练模型的权重保持不变,仅优化提示词的嵌入。
Prefix-Tuning
- 论文题目:Prefix-Tuning: Optimizing Continuous Prompts for Generation
- 论文链接:https://arxiv.org/pdf/2101.00190
- 发表时间:2021.1.1
含义
通过固定预训练模型的参数,仅在输入序列的前面添加一个可训练的前缀(prefix),从而在不改变模型参数的情况下实现特定任务的适应
原理
固定模型参数: 不对预训练语言模型(如 GPT-3、BERT 等)的参数进行微调
添加可训练前缀: 在输入序列的前面添加一个可训练的前缀向量。这个前缀向量的长度和维度可以根据具体任务进行调整
任务适应: 在实际应用中,前缀向量与输入序列一起输入到预训练模型中。由于前缀向量是可训练的,模型可以通过调整前缀向量来适应特定的任务,而无需改变模型本身的参数。
P-Tuning
-
论文题目:GPT Understands, Too
-
论文链接:https://arxiv.org/pdf/2103.10385v1
-
发表时间:2021.3.18
含义
在模型输入中插入一些可训练的提示(prompts),这些提示是嵌入向量(embedding vectors),在训练过程中被优化
原理
固定模型参数: 和 Prefix-Tuning 类似,不改模型参数
插入可训练提示: 在输入序列的适当位置插入一些可训练的提示向量。
任务适应: 在训练过程中,这些提示向量与输入序列一起输入到预训练模型中
P-Tuning V2
- 论文题目:P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
- 论文链接:https://arxiv.org/pdf/2110.07602v2
- 发表时间:2021.10.18
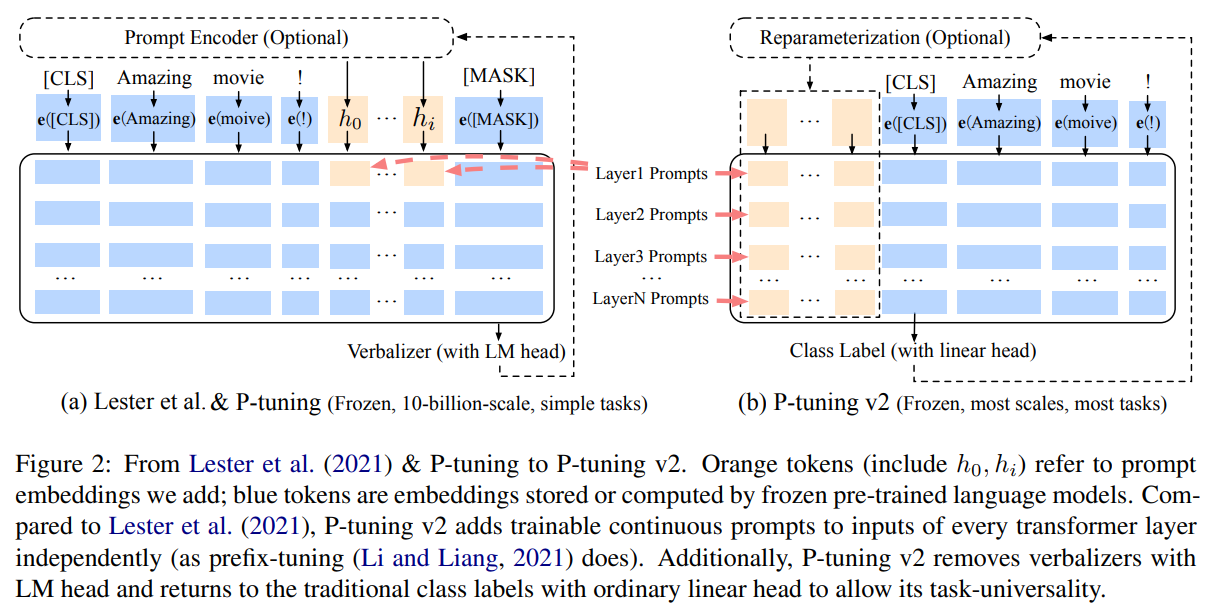
含义
保留了 P-Tuning 的核心思想,即通过优化输入提示向量来引导预训练模型处理特定任务
原理
相比较于P-Tuning:
动态提示优化: 采用动态提示优化方法
多层提示插入: P-Tuning V2 不仅在输入序列的前面插入提示向量,还在模型的不同层次(如中间层)插入提示向量
BitFit
- 论文题目:BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models
- 论文链接:https://arxiv.org/abs/2106.10199
- 发表时间:2021.6.18
含义
通过仅微调模型的偏置参数来适应新的任务,从而减少了需要调整的参数量。
原理
-
原始 BERT 模型:包含多层 Transformer,每层有权重矩阵 W 和偏置 b。
-
BitFit 微调:保持所有权重矩阵 W 不变,只微调每层的偏置参数 b
DistilBERT
- 论文题目:DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
- 论文链接:https://arxiv.org/abs/1910.01108
- 发表时间:2020.3.1
含义
使用知识蒸馏技术将大模型压缩成更小的模型,从而减少微调所需的计算资源和时间。
原理
知识蒸馏是一种模型压缩技术,通过训练一个较小的学生模型(student model)来模仿较大教师模型(teacher model)的行为。具体步骤如下:
- 教师模型:使用预训练的 BERT 模型作为教师模型。
- 学生模型:构建一个较小的 BERT 模型,即 DistilBERT。
- 训练过程:在训练过程中,学生模型通过模仿教师模型的输出来学习。损失函数不仅包括学生模型和教师模型输出之间的差异,还包括学生模型和真实标签之间的差异。