深圳网站设计网站制作网站优化排名易下拉软件
1.GPT简介
GPT(Generative Pre-trained Transformer)模型是一种基于Transformer架构的生成式预训练模型,由OpenAI开发。它采用了无监督学习的方式进行预训练,然后通过微调适应特定的任务。GPT模型的结构由多层Transformer解码器组成,每个解码器由多头自注意力机制和前馈神经网络组成。自注意力机制能够对输入的序列进行编码,并捕捉序列中的上文关系,而前馈神经网络则负责对编码后的向量进行进一步的非线性转换。通过堆叠多个解码器,GPT模型能够学习到更加丰富的语义表示。
在预训练阶段,GPT模型采用了大规模的无标签文本数据,并根据上文来预测下一个词。这个预测任务使模型能够学习到语言的统计规律和语义信息。预训练采用了Transformer的自回归结构,即每个位置的词只能依赖于前面的词。这种方式使得模型具有了生成文本的能力。
2018年6月 GPT-1:约5GB文本,1.17亿参数量2019年2月 GPT-2:约40GB文本,15亿参数量2020年5月 GPT-3:约45TB文本,1750亿参数量
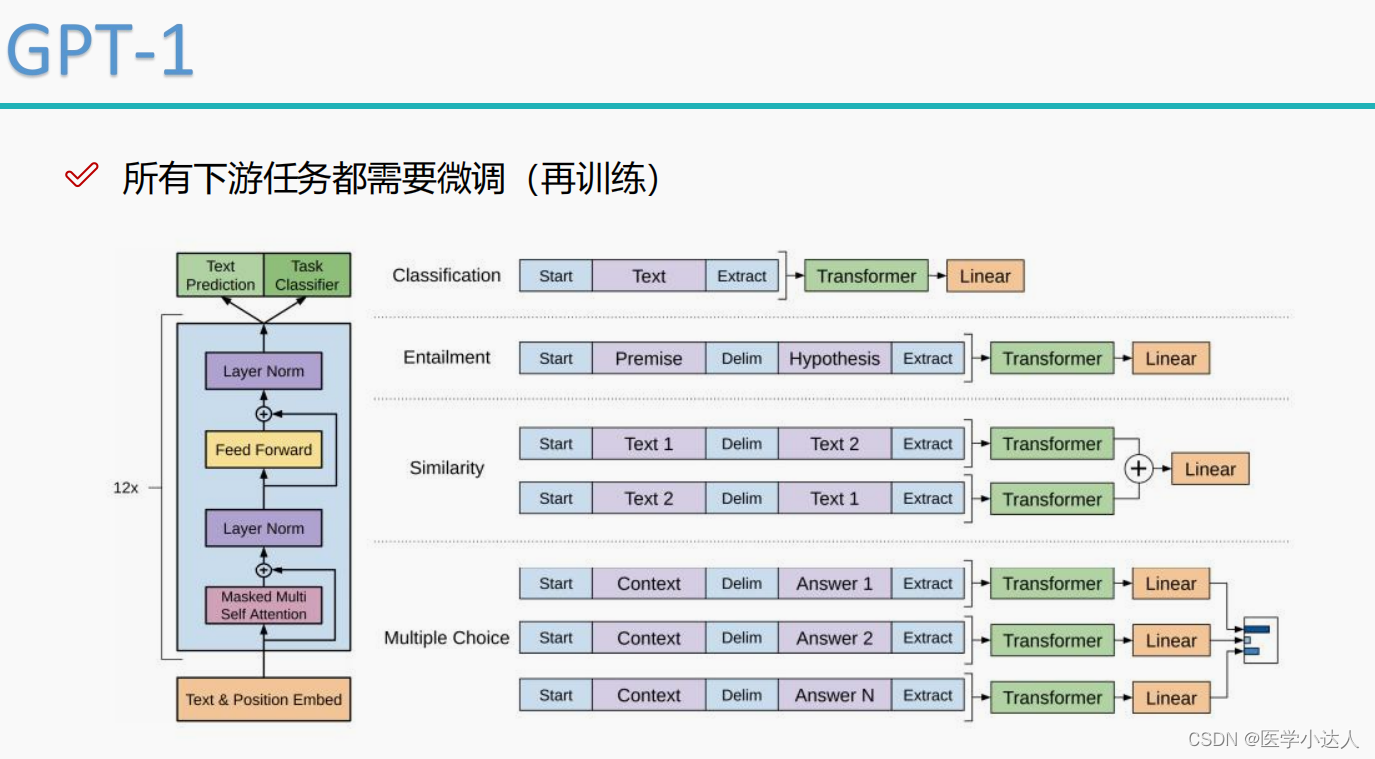
GPT又有哪些应用呢?
1.1 文本生成:GPT可以通过学习大量文本数据,从而生成新的文本。例如,可以用GPT来生成文章、故事、甚至是诗歌等。
1.2 对话系统:GPT还可以用来构建对话系统,例如智能客服、聊天机器人等。用户可以通过与GPT表达自己的意图和需求,GPT可以自动生成回复。
1.3 机器翻译:GPT也可以用来进行机器翻译。通过学习不同语言的大量文本数据,GPT可以将一种语言的文本转换成另一种语言的文本。
1.4 情感分析:GPT可以用来进行情感分析,例如对一段文本进行情感分类,判断其是正面、负面还是中性的。
1.5 问答系统:GPT还可以用来构建问答系统,例如知识问答、智能客服等。用户可以通过向GPT提出问题,GPT可以自动生成回答。
2.GPT代码实战
2.1定义缩放点积注意力类
import numpy as np # 导入 numpy 库
import torch # 导入 torch 库
import torch.nn as nn # 导入 torch.nn 库
d_k = 64 # K(=Q) 维度
d_v = 64 # V 维度
# 定义缩放点积注意力类
class ScaledDotProductAttention(nn.Module):def __init__(self):super(ScaledDotProductAttention, self).__init__() def forward(self, Q, K, V, attn_mask):#------------------------- 维度信息 -------------------------------- # Q K V [batch_size, n_heads, len_q/k/v, dim_q=k/v] (dim_q=dim_k)# attn_mask [batch_size, n_heads, len_q, len_k]#----------------------------------------------------------------# 计算注意力分数(原始权重)[batch_size,n_heads,len_q,len_k]scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) #------------------------- 维度信息 -------------------------------- # scores [batch_size, n_heads, len_q, len_k]#----------------------------------------------------------------- # 使用注意力掩码,将 attn_mask 中值为 1 的位置的权重替换为极小值#------------------------- 维度信息 -------------------------------- # attn_mask [batch_size, n_heads, len_q, len_k], 形状和 scores 相同#----------------------------------------------------------------- scores.masked_fill_(attn_mask, -1e9) # 对注意力分数进行 softmax 归一化weights = nn.Softmax(dim=-1)(scores) #------------------------- 维度信息 -------------------------------- # weights [batch_size, n_heads, len_q, len_k], 形状和 scores 相同#----------------------------------------------------------------- # 计算上下文向量(也就是注意力的输出), 是上下文信息的紧凑表示context = torch.matmul(weights, V) #------------------------- 维度信息 -------------------------------- # context [batch_size, n_heads, len_q, dim_v]#----------------------------------------------------------------- return context, weights # 返回上下文向量和注意力分数2.2定义多头自注意力类
# 定义多头自注意力类
d_embedding = 512 # Embedding 的维度
n_heads = 8 # Multi-Head Attention 中头的个数
batch_size = 3 # 每一批的数据大小
class MultiHeadAttention(nn.Module):def __init__(self):super(MultiHeadAttention, self).__init__()self.W_Q = nn.Linear(d_embedding, d_k * n_heads) # Q的线性变换层self.W_K = nn.Linear(d_embedding, d_k * n_heads) # K的线性变换层self.W_V = nn.Linear(d_embedding, d_v * n_heads) # V的线性变换层self.linear = nn.Linear(n_heads * d_v, d_embedding)self.layer_norm = nn.LayerNorm(d_embedding)def forward(self, Q, K, V, attn_mask): #------------------------- 维度信息 -------------------------------- # Q K V [batch_size, len_q/k/v, embedding_dim] #----------------------------------------------------------------- residual, batch_size = Q, Q.size(0) # 保留残差连接# 将输入进行线性变换和重塑,以便后续处理q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2)v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2)#------------------------- 维度信息 -------------------------------- # q_s k_s v_s: [batch_size, n_heads, len_q/k/v, d_q=k/v]#----------------------------------------------------------------- # 将注意力掩码复制到多头 attn_mask: [batch_size, n_heads, len_q, len_k]attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)#------------------------- 维度信息 -------------------------------- # attn_mask [batch_size, n_heads, len_q, len_k]#----------------------------------------------------------------- # 使用缩放点积注意力计算上下文和注意力权重context, weights = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)#------------------------- 维度信息 -------------------------------- # context [batch_size, n_heads, len_q, dim_v]# weights [batch_size, n_heads, len_q, len_k]#----------------------------------------------------------------- # 通过调整维度将多个头的上下文向量连接在一起context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v) #------------------------- 维度信息 -------------------------------- # context [batch_size, len_q, n_heads * dim_v]#----------------------------------------------------------------- # 用一个线性层把连接后的多头自注意力结果转换,原始地嵌入维度output = self.linear(context) #------------------------- 维度信息 -------------------------------- # output [batch_size, len_q, embedding_dim]#----------------------------------------------------------------- # 与输入 (Q) 进行残差链接,并进行层归一化后输出output = self.layer_norm(output + residual)#------------------------- 维度信息 -------------------------------- # output [batch_size, len_q, embedding_dim]#----------------------------------------------------------------- return output, weights # 返回层归一化的输出和注意力权重2.3定义逐位置前馈网络类
# 定义逐位置前馈网络类
class PoswiseFeedForwardNet(nn.Module):def __init__(self, d_ff=2048):super(PoswiseFeedForwardNet, self).__init__()# 定义一维卷积层 1,用于将输入映射到更高维度self.conv1 = nn.Conv1d(in_channels=d_embedding, out_channels=d_ff, kernel_size=1)# 定义一维卷积层 2,用于将输入映射回原始维度self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_embedding, kernel_size=1)# 定义层归一化self.layer_norm = nn.LayerNorm(d_embedding)def forward(self, inputs): #------------------------- 维度信息 -------------------------------- # inputs [batch_size, len_q, embedding_dim]#---------------------------------------------------------------- residual = inputs # 保留残差连接 # 在卷积层 1 后使用 ReLU 激活函数 output = nn.ReLU()(self.conv1(inputs.transpose(1, 2))) #------------------------- 维度信息 -------------------------------- # output [batch_size, d_ff, len_q]#----------------------------------------------------------------# 使用卷积层 2 进行降维 output = self.conv2(output).transpose(1, 2) #------------------------- 维度信息 -------------------------------- # output [batch_size, len_q, embedding_dim]#----------------------------------------------------------------# 与输入进行残差链接,并进行层归一化output = self.layer_norm(output + residual) #------------------------- 维度信息 -------------------------------- # output [batch_size, len_q, embedding_dim]#----------------------------------------------------------------return output # 返回加入残差连接后层归一化的结果2.4生成正弦位置编码表的函数,用于在 Transformer 中引入位置信息
# 生成正弦位置编码表的函数,用于在 Transformer 中引入位置信息
def get_sin_enc_table(n_position, embedding_dim):#------------------------- 维度信息 --------------------------------# n_position: 输入序列的最大长度# embedding_dim: 词嵌入向量的维度#----------------------------------------------------------------- # 根据位置和维度信息,初始化正弦位置编码表sinusoid_table = np.zeros((n_position, embedding_dim)) # 遍历所有位置和维度,计算角度值for pos_i in range(n_position):for hid_j in range(embedding_dim):angle = pos_i / np.power(10000, 2 * (hid_j // 2) / embedding_dim)sinusoid_table[pos_i, hid_j] = angle # 计算正弦和余弦值sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i 偶数维sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1 奇数维 #------------------------- 维度信息 --------------------------------# sinusoid_table 的维度是 [n_position, embedding_dim]#---------------------------------------------------------------- return torch.FloatTensor(sinusoid_table) # 返回正弦位置编码表2.5定义填充注意力掩码函数
# 定义填充注意力掩码函数
def get_attn_pad_mask(seq_q, seq_k):#------------------------- 维度信息 --------------------------------# seq_q 的维度是 [batch_size, len_q]# seq_k 的维度是 [batch_size, len_k]#-----------------------------------------------------------------batch_size, len_q = seq_q.size()batch_size, len_k = seq_k.size()# 生成布尔类型张量pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # <PAD>token 的编码值为 0#------------------------- 维度信息 --------------------------------# pad_attn_mask 的维度是 [batch_size,1,len_k]#-----------------------------------------------------------------# 变形为与注意力分数相同形状的张量 pad_attn_mask = pad_attn_mask.expand(batch_size, len_q, len_k)#------------------------- 维度信息 --------------------------------# pad_attn_mask 的维度是 [batch_size,len_q,len_k]#-----------------------------------------------------------------return pad_attn_mask # 返回填充位置的注意力掩码2.6定义编码器层类
# 定义编码器层类
class EncoderLayer(nn.Module):def __init__(self):super(EncoderLayer, self).__init__() self.enc_self_attn = MultiHeadAttention() # 多头自注意力层 self.pos_ffn = PoswiseFeedForwardNet() # 位置前馈神经网络层def forward(self, enc_inputs, enc_self_attn_mask):#------------------------- 维度信息 --------------------------------# enc_inputs 的维度是 [batch_size, seq_len, embedding_dim]# enc_self_attn_mask 的维度是 [batch_size, seq_len, seq_len]#-----------------------------------------------------------------# 将相同的 Q,K,V 输入多头自注意力层 , 返回的 attn_weights 增加了头数 enc_outputs, attn_weights = self.enc_self_attn(enc_inputs, enc_inputs,enc_inputs, enc_self_attn_mask)#------------------------- 维度信息 --------------------------------# enc_outputs 的维度是 [batch_size, seq_len, embedding_dim] # attn_weights 的维度是 [batch_size, n_heads, seq_len, seq_len] # 将多头自注意力 outputs 输入位置前馈神经网络层enc_outputs = self.pos_ffn(enc_outputs) # 维度与 enc_inputs 相同#------------------------- 维度信息 --------------------------------# enc_outputs 的维度是 [batch_size, seq_len, embedding_dim] #-----------------------------------------------------------------return enc_outputs, attn_weights # 返回编码器输出和每层编码器注意力权重2.7定义编码器类
# 定义编码器类
n_layers = 6 # 设置 Encoder 的层数
class Encoder(nn.Module):def __init__(self, corpus):super(Encoder, self).__init__() self.src_emb = nn.Embedding(len(corpus.src_vocab), d_embedding) # 词嵌入层self.pos_emb = nn.Embedding.from_pretrained( \get_sin_enc_table(corpus.src_len+1, d_embedding), freeze=True) # 位置嵌入层self.layers = nn.ModuleList(EncoderLayer() for _ in range(n_layers))# 编码器层数def forward(self, enc_inputs): #------------------------- 维度信息 --------------------------------# enc_inputs 的维度是 [batch_size, source_len]#-----------------------------------------------------------------# 创建一个从 1 到 source_len 的位置索引序列pos_indices = torch.arange(1, enc_inputs.size(1) + 1).unsqueeze(0).to(enc_inputs)#------------------------- 维度信息 --------------------------------# pos_indices 的维度是 [1, source_len]#----------------------------------------------------------------- # 对输入进行词嵌入和位置嵌入相加 [batch_size, source_len,embedding_dim]enc_outputs = self.src_emb(enc_inputs) + self.pos_emb(pos_indices)#------------------------- 维度信息 --------------------------------# enc_outputs 的维度是 [batch_size, seq_len, embedding_dim]#-----------------------------------------------------------------# 生成自注意力掩码enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) #------------------------- 维度信息 --------------------------------# enc_self_attn_mask 的维度是 [batch_size, len_q, len_k] #----------------------------------------------------------------- enc_self_attn_weights = [] # 初始化 enc_self_attn_weights# 通过编码器层 [batch_size, seq_len, embedding_dim]for layer in self.layers: enc_outputs, enc_self_attn_weight = layer(enc_outputs, enc_self_attn_mask)enc_self_attn_weights.append(enc_self_attn_weight)#------------------------- 维度信息 --------------------------------# enc_outputs 的维度是 [batch_size, seq_len, embedding_dim] 维度与 enc_inputs 相同# enc_self_attn_weights 是一个列表,每个元素的维度是 [batch_size, n_heads, seq_len, seq_len] #-----------------------------------------------------------------return enc_outputs, enc_self_attn_weights # 返回编码器输出和编码器注意力权重2.8生成后续注意力掩码的函数,用于在多头自注意力计算中忽略未来信息
# 生成后续注意力掩码的函数,用于在多头自注意力计算中忽略未来信息
def get_attn_subsequent_mask(seq):#------------------------- 维度信息 --------------------------------# seq 的维度是 [batch_size, seq_len(Q)=seq_len(K)]#-----------------------------------------------------------------# 获取输入序列的形状attn_shape = [seq.size(0), seq.size(1), seq.size(1)] #------------------------- 维度信息 --------------------------------# attn_shape 是一个一维张量 [batch_size, seq_len(Q), seq_len(K)]#-----------------------------------------------------------------# 使用 numpy 创建一个上三角矩阵(triu = triangle upper)subsequent_mask = np.triu(np.ones(attn_shape), k=1)#------------------------- 维度信息 --------------------------------# subsequent_mask 的维度是 [batch_size, seq_len(Q), seq_len(K)]#-----------------------------------------------------------------# 将 numpy 数组转换为 PyTorch 张量,并将数据类型设置为 byte(布尔值)subsequent_mask = torch.from_numpy(subsequent_mask).byte()#------------------------- 维度信息 --------------------------------# 返回的 subsequent_mask 的维度是 [batch_size, seq_len(Q), seq_len(K)]#-----------------------------------------------------------------return subsequent_mask # 返回后续位置的注意力掩码2.9定义解码器层类
# 定义解码器层类
class DecoderLayer(nn.Module):def __init__(self):super(DecoderLayer, self).__init__()self.self_attn = MultiHeadAttention() # 多头自注意力层self.feed_forward = PoswiseFeedForwardNet() # 逐位置前馈网络层self.norm1 = nn.LayerNorm(d_embedding) # 第一个层归一化self.norm2 = nn.LayerNorm(d_embedding) # 第二个层归一化def forward(self, dec_inputs, attn_mask=None):# 使用多头自注意力处理输入attn_output, _ = self.self_attn(dec_inputs, dec_inputs, dec_inputs, attn_mask)# 将注意力输出与输入相加并进行第一个层归一化norm1_outputs = self.norm1(dec_inputs + attn_output)# 将归一化后的输出输入到位置前馈神经网络ff_outputs = self.feed_forward(norm1_outputs)# 将前馈神经网络输出与第一次归一化后的输出相加并进行第二个层归一化dec_outputs = self.norm2(norm1_outputs + ff_outputs)return dec_outputs # 返回解码器层输出2.10定义解码器类
# 定义解码器类
n_layers = 6 # 设置 Decoder 的层数
class Decoder(nn.Module):def __init__(self, vocab_size, max_seq_len):super(Decoder, self).__init__()# 词嵌入层(参数为词典维度)self.src_emb = nn.Embedding(vocab_size, d_embedding) # 位置编码层(参数为序列长度)self.pos_emb = nn.Embedding(max_seq_len, d_embedding)# 初始化 N 个解码器层 self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)]) def forward(self, dec_inputs): # 创建位置信息positions = torch.arange(len(dec_inputs), device=dec_inputs.device).unsqueeze(-1)# 将词嵌入与位置编码相加inputs_embedding = self.src_emb(dec_inputs) + self.pos_emb(positions)# 生成自注意力掩码attn_mask = get_attn_subsequent_mask(inputs_embedding).to(device)# 初始化解码器输入,这是第一层解码器层的输入 dec_outputs = inputs_embedding for layer in self.layers:# 将输入数据传递给解码器层,并返回解码器层的输出,作为下一层的输入dec_outputs = layer(dec_outputs, attn_mask) return dec_outputs # 返回解码器输出2.11定义 GPT 模型
# 定义 GPT 模型
class GPT(nn.Module):def __init__(self, vocab_size, max_seq_len):super(GPT, self).__init__()self.decoder = Decoder(vocab_size, max_seq_len) # 解码器,用于学习文本生成能力self.projection = nn.Linear(d_embedding, vocab_size) # 全连接层,输出预测结果def forward(self, dec_inputs): dec_outputs = self.decoder(dec_inputs) # 将输入数据传递给解码器logits = self.projection(dec_outputs) # 传递给全连接层以生成预测return logits # 返回预测结果2.12构建语料库
# 构建语料库
from collections import Counter
class LanguageCorpus:def __init__(self, sentences):self.sentences = sentences# 计算语言的最大句子长度,并加 2 以容纳特殊符号 <sos> 和 <eos>self.seq_len = max([len(sentence.split()) for sentence in sentences]) + 2self.vocab = self.create_vocabulary() # 创建源语言和目标语言的词汇表self.idx2word = {v: k for k, v in self.vocab.items()} # 创建索引到单词的映射def create_vocabulary(self):vocab = {'<pad>': 0, '<sos>': 1, '<eos>': 2}counter = Counter()# 统计语料库的单词频率for sentence in self.sentences:words = sentence.split()counter.update(words)# 创建词汇表,并为每个单词分配一个唯一的索引for word in counter:if word not in vocab:vocab[word] = len(vocab)return vocabdef make_batch(self, batch_size, test_batch=False):input_batch, output_batch = [], [] # 初始化批数据sentence_indices = torch.randperm(len(self.sentences))[:batch_size] # 随机选择句子索引for index in sentence_indices:sentence = self.sentences[index]# 将句子转换为索引序列seq = [self.vocab['<sos>']] + [self.vocab[word] for word in sentence.split()] + [self.vocab['<eos>']]seq += [self.vocab['<pad>']] * (self.seq_len - len(seq)) # 对序列进行填充# 将处理好的序列添加到批次中input_batch.append(seq[:-1])output_batch.append(seq[1:])return torch.LongTensor(input_batch), torch.LongTensor(output_batch)2.13预料处理
with open("lang.txt", "r") as file: # 从文件中读入语料sentences = [line.strip() for line in file.readlines()]
corpus = LanguageCorpus(sentences) # 创建语料库
vocab_size = len(corpus.vocab) # 词汇表大小
max_seq_len = corpus.seq_len # 最大句子长度(用于设置位置编码)
print(f" 语料库词汇表大小 : {vocab_size}") # 打印词汇表大小
print(f" 最长句子长度 : {max_seq_len}") # 打印最大序列长2.14训练模型
import torch.optim as optim # 导入优化器
device = "cuda" if torch.cuda.is_available() else "cpu" # 设置设备
model = GPT(vocab_size, max_seq_len).to(device) # 创建 GPT 模型实例
criterion = nn.CrossEntropyLoss() # 损失函数
optimizer = optim.Adam(model.parameters(), lr=0.0001) # 优化器
epochs = 500 # 训练轮次
for epoch in range(epochs): # 训练 epochs 轮optimizer.zero_grad() # 梯度清零inputs, targets = corpus.make_batch(batch_size) # 创建训练数据inputs, targets = inputs.to(device), targets.to(device)outputs = model(inputs) # 获取模型输出 loss = criterion(outputs.view(-1, vocab_size), targets.view(-1)) # 计算损失if (epoch + 1) % 100 == 0: # 打印损失print(f"Epoch: {epoch + 1:04d} cost = {loss:.6f}")loss.backward() # 反向传播optimizer.step() # 更新参数2.15测试文本生成
# 测试文本生成
def generate_text(model, input_str, max_len=50):model.eval() # 将模型设置为评估(测试)模式,关闭 dropout 和 batch normalization 等训练相关的层# 将输入字符串中的每个 token 转换为其在词汇表中的索引input_tokens = [corpus.vocab[token] for token in input_str]# 创建一个新列表,将输入的 tokens 复制到输出 tokens 中 , 目前只有输入的词output_tokens = input_tokens.copy()with torch.no_grad(): # 禁用梯度计算,以节省内存并加速测试过程for _ in range(max_len): # 生成最多 max_len 个 tokens# 将输出的 token 转换为 PyTorch 张量,并增加一个代表批次的维度 [1, len(output_tokens)]inputs = torch.LongTensor(output_tokens).unsqueeze(0).to(device)outputs = model(inputs) # 输出 logits 形状为 [1, len(output_tokens), vocab_size]# 在最后一个维度上获取 logits 中的最大值,并返回其索引(即下一个 token)_, next_token = torch.max(outputs[:, -1, :], dim=-1) next_token = next_token.item() # 将张量转换为 Python 整数 if next_token == corpus.vocab["<eos>"]:break # 如果生成的 token 是 EOS(结束符),则停止生成过程 output_tokens.append(next_token) # 将生成的 tokens 添加到 output_tokens 列表# 将输出 tokens 转换回文本字符串output_str = " ".join([corpus.idx2word[token] for token in output_tokens])return output_str
input_str = ["Python"] # 输入一个词:Python
generated_text = generate_text(model, input_str) # 模型跟着这个词生成后续文本
print(" 生成的文本 :", generated_text) # 打印预测文本3.总结
注意:GPT只有解码器部分,但是我全都定义了,大家顺便复习一下,然后仔细看一下解码器的结构。
GPT模型的训练分为两个阶段:预训练和微调。在预训练阶段,GPT模型利用大规模文本数据进行自监督学习,通过掩盖输入文本的一部分内容,让模型预测被掩盖的部分。这个预测任务被称为“掩码语言模型”(Masked Language Modeling)。
在微调阶段,GPT模型通过在特定任务上进行有监督的微调来利用其在预训练阶段学到的语言知识。通过在少量标注数据上进行微调,GPT模型可以适应特定的任务,如文本生成、文本分类、机器翻译等。
然而,GPT模型也存在一些挑战和限制。例如,由于是基于自动回归的方式生成文本,它可能面临生成不准确、重复、和不连贯的问题。此外,GPT模型对训练数据的质量和多样性敏感,可能会受到输入偏见和不准确信息的影响。
注意“lang.txt”内容如下:
Python is a popular programming language.
I love to code in Python.
Data science is a hot topic in the tech industry.
Machine learning and deep learning are important parts of data science.
I am learning how to build neural networks.
Neural networks are modeled after the structure of the human brain.
Artificial intelligence has many applications in various industries.
Natural language processing is a branch of AI that deals with language understanding.
The rise of big data has led to an increased demand for data scientists.
I enjoy analyzing and visualizing data using Python libraries like Pandas and Matplotlib.
Data cleaning is an important part of data analysis.
I am fascinated by the power of deep learning algorithms.
Self-driving cars are an example of the practical applications of AI.
The tech industry is constantly evolving and changing.
I believe that AI will have a major impact on the future of work.
I am excited to see how AI will continue to develop and change the world.
The ethical implications of AI are a topic of much debate and discussion.
As with any powerful technology, there is a responsibility to use AI ethically and responsibly.
I think that the benefits of AI outweigh the risks, if used wisely.
Programming is a valuable skill in the digital age.