宁波商城网站开发设计制作网页代码大全
Kafka生产消费流程
1.Kafka一条消息发送和消费的流程图(非集群)
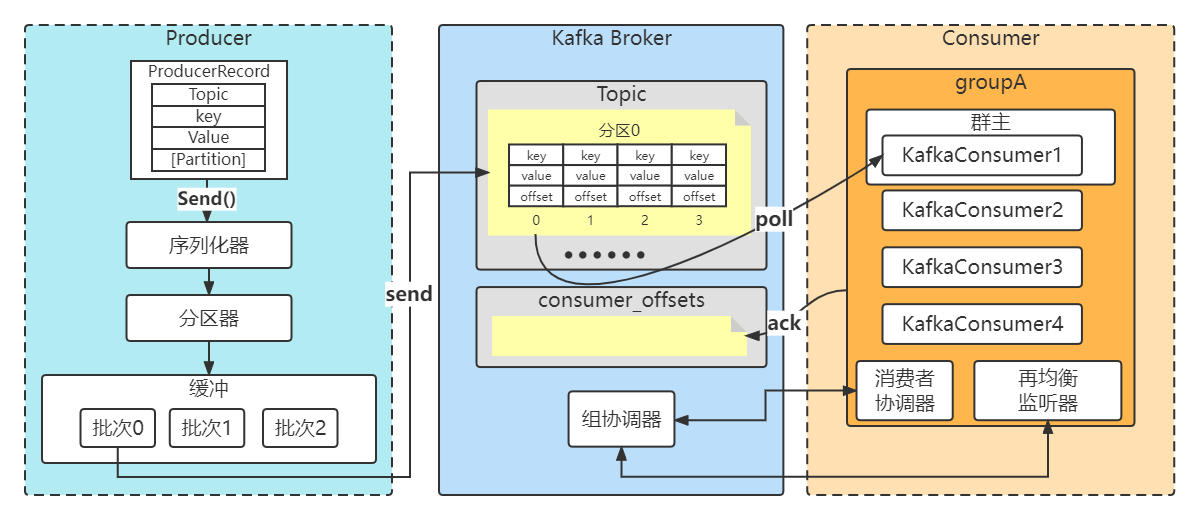
2.三种发送方式
- 准备工作
创建maven工程,引入依赖
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.3.1</version></dependency>
- 消费者
/*** 类说明:消费者入门*/
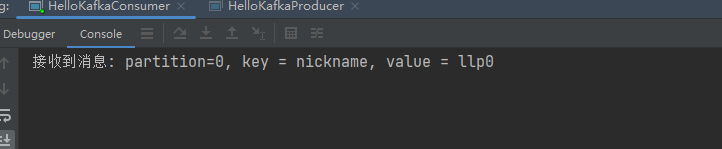
public class HelloKafkaConsumer {public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器的地址properties.put("bootstrap.servers","192.168.140.103:9092");// 设置String的反序列化properties.put("key.deserializer", StringDeserializer.class);properties.put("value.deserializer", StringDeserializer.class);// 设置消费者组idproperties.put(ConsumerConfig.GROUP_ID_CONFIG,"llp_consumerA");// 构建kafka消费者对象KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(properties);try {//指定消费者订阅的主题consumer.subscribe(Collections.singletonList("llp-topic"));// 调用消费者拉取消息while(true){// 设置1秒的超时时间ConsumerRecords<String, String> records= consumer.poll(Duration.ofSeconds(1));for(ConsumerRecord<String, String> record:records){String key = record.key();String value = record.value();//分区int partition = record.partition();System.out.println("接收到消息: partition="+partition+", key = " + key + ", value = " + value);}}} finally {// 释放连接consumer.close();}}
}
1.1 发送并忘记
忽略send方法的返回值,不做任何处理。大多数情况下,消息会正常到达,而且生产者会自动重试,但有时会丢失消息。
消费者
/*** 类说明:kafak生产者*/
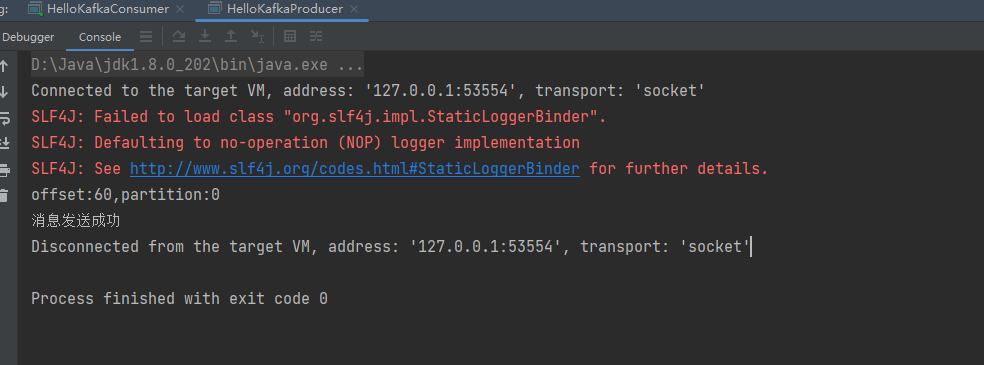
public class HelloKafkaProducer {public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器的地址,9092kafka默认端口properties.put("bootstrap.servers","192.168.140.103:9092");//补充一下: 配置多台的服务 用,分割, 其中一个宕机,生产者 依然可以连上(集群)// 设置String的序列化 (对象-》二进制字节数组 : 能够在网络上传输 )properties.put("key.serializer", StringSerializer.class);properties.put("value.serializer", StringSerializer.class);// 构建kafka生产者对象KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);try {ProducerRecord<String,String> record;try {// 构建消息record = new ProducerRecord<String,String>("llp-topic", "nickname","llp0");// 发送消息producer.send(record);System.out.println("消息发送成功");} catch (Exception e) {e.printStackTrace();}} finally {// 释放连接producer.close();}}}
测试结果
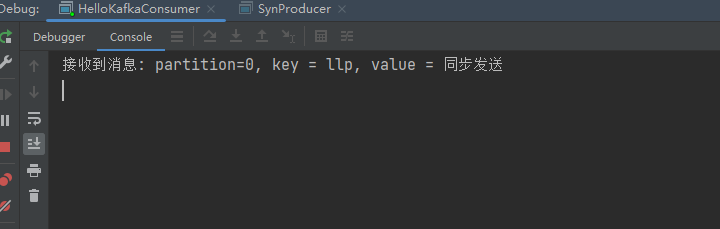
1.2同步发送
/*** 类说明:发送消息--同步模式*/
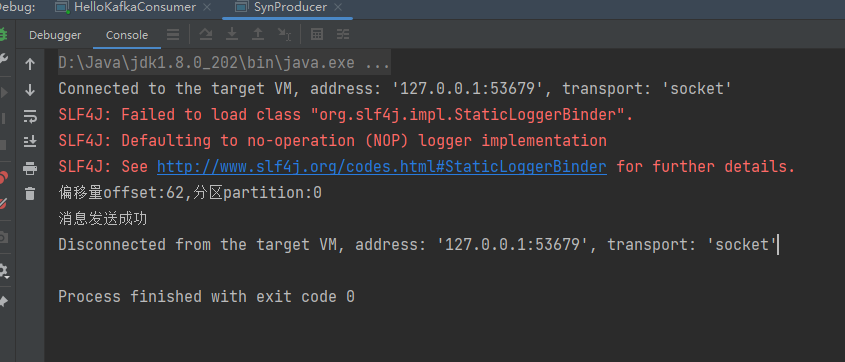
public class SynProducer {public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器的地址properties.put("bootstrap.servers","192.168.140.103:9092");// 设置String的序列化properties.put("key.serializer", StringSerializer.class);properties.put("value.serializer", StringSerializer.class);// 构建kafka生产者对象KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);try {ProducerRecord<String,String> record;try {// 构建消息record = new ProducerRecord<String,String>("llp-topic", "llp","同步发送");// 发送消息Future<RecordMetadata> future =producer.send(record);RecordMetadata recordMetadata = future.get();if(null!=recordMetadata){System.out.println("偏移量offset:"+recordMetadata.offset()+","+"分区partition:"+recordMetadata.partition());}System.out.println("消息发送成功");} catch (Exception e) {e.printStackTrace();}} finally {// 释放连接producer.close();}}}
测试结果
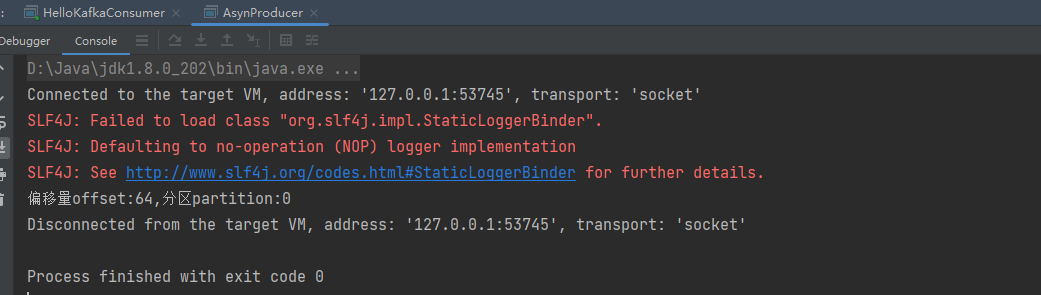
1.3 异步发送
/*** 类说明:发送消息--异步模式*/
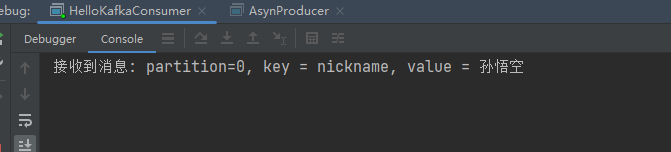
public class AsynProducer {public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器的地址properties.put("bootstrap.servers","192.168.140.103:9092");// 设置String的序列化properties.put("key.serializer", StringSerializer.class);properties.put("value.serializer", StringSerializer.class);// 构建kafka生产者对象KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);try {ProducerRecord<String,String> record;try {// 构建消息record = new ProducerRecord<String,String>("llp-topic", "nickname","孙悟空");// 发送消息producer.send(record, new Callback() {public void onCompletion(RecordMetadata recordMetadata, Exception e) {if (e == null){// 没有异常,输出信息到控制台System.out.println("偏移量offset:"+recordMetadata.offset()+"," +"分区partition:"+recordMetadata.partition());} else {// 出现异常打印e.printStackTrace();}}});} catch (Exception e) {e.printStackTrace();}} finally {// 释放连接producer.close();}}
}
测试结果
3. 消费者群组
Kafka里消费者从属于消费者群组,一个群组里的消费者订阅的都是同一个主题,每个消费者接收主题一部分分区的消息。
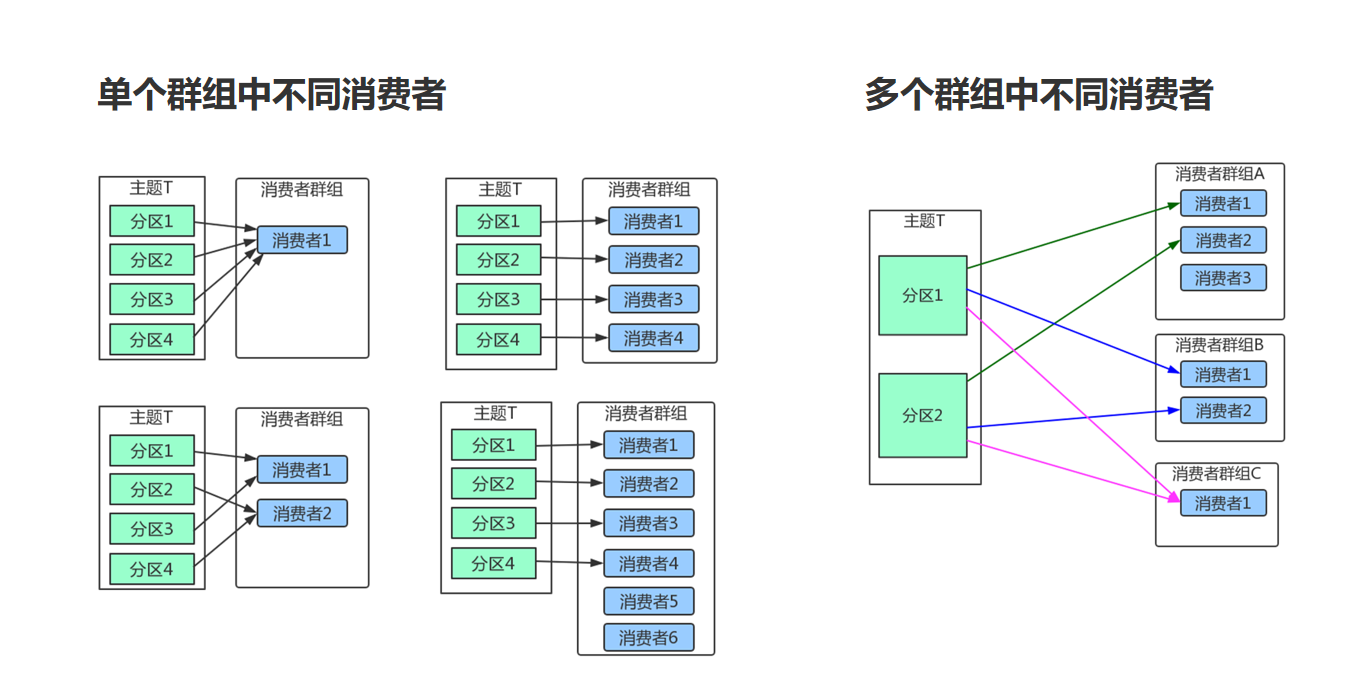
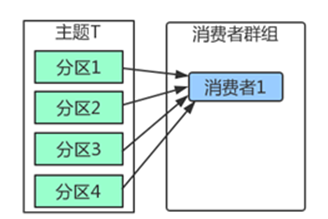
如上图,主题T有4个分区,群组中只有一个消费者,则该消费者将收到主题T1全部4个分区的消息。
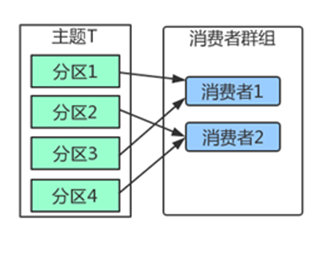
如上图,在群组中增加一个消费者2,那么每个消费者将分别从两个分区接收消息,上图中就表现为消费者1接收分区1和分区3的消息,消费者2接收分区2和分区4的消息。
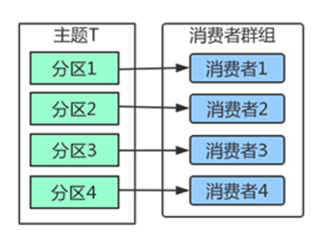
如上图,在群组中有4个消费者,那么每个消费者将分别从1个分区接收消息。
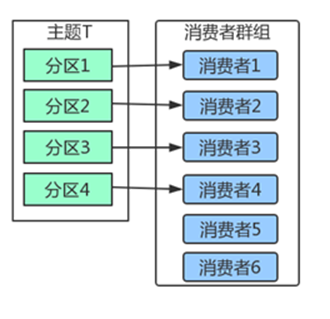
但是,当我们增加更多的消费者,超过了主题的分区数量,就会有一部分的消费者被闲置,不会接收到任何消息。
往消费者群组里增加消费者是进行横向伸缩能力的主要方式。所以我们有必要为主题设定合适规模的分区,在负载均衡的时候可以加入更多的消费者。但是要记住,一个群组里消费者数量超过了主题的分区数量,多出来的消费者是没有用处的。
4.序列化
创建生产者对象必须指定序列化器,默认的序列化器并不能满足我们所有的场景。我们完全可以自定义序列化器。只要实现org.apache.kafka.common.serialization.Serializer接口即可。
- 举个例子,比如我现在需要传输一个user类的实体对象
user实体类
/*** 类说明:实体类*/
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User {private int id;private String name;public User(int id) {this.id = id;}
}
自定义序列化器,在生产者端进行指定
/*** 类说明:自定义序列化器*/
public class UserSerializer implements Serializer<User> {public void configure(Map<String, ?> configs, boolean isKey) {//do nothing}public byte[] serialize(String topic, User data) {try {byte[] name;int nameSize;if(data==null){return null;}if(data.getName()!=null){name = data.getName().getBytes("UTF-8");//字符串的长度nameSize = name.length;}else{name = new byte[0];nameSize = 0;}/*id的长度4个字节,字符串的长度描述4个字节,字符串本身的长度nameSize个字节*/ByteBuffer buffer = ByteBuffer.allocate(4+4+nameSize);buffer.putInt(data.getId());//4buffer.putInt(nameSize);//4buffer.put(name);//nameSizereturn buffer.array();} catch (Exception e) {throw new SerializationException("Error serialize User:"+e);}}public void close() {//do nothing}
}
反序列化器,在消费者端指定
/*** 类说明:自定义反序列化器*/
public class UserDeserializer implements Deserializer<User> {public void configure(Map<String, ?> configs, boolean isKey) {//do nothing}public User deserialize(String topic, byte[] data) {try {if(data==null){return null;}if(data.length<8){throw new SerializationException("Error data size.");}ByteBuffer buffer = ByteBuffer.wrap(data);int id;String name;int nameSize;id = buffer.getInt();nameSize = buffer.getInt();byte[] nameByte = new byte[nameSize];buffer.get(nameByte);name = new String(nameByte,"UTF-8");return new User(id,name);} catch (Exception e) {throw new SerializationException("Error Deserializer DemoUser."+e);}}public void close() {//do nothing}
}
生产者
/*** 类说明:发送消息--value使用自定义序列化*/
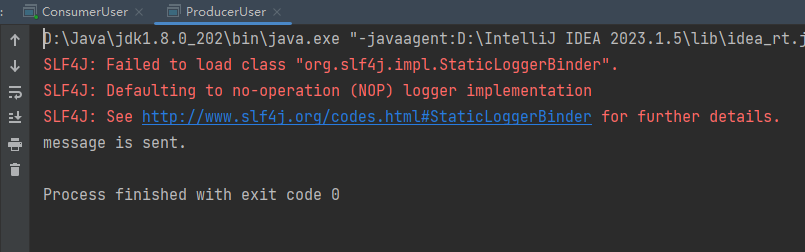
public class ProducerUser {public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器的地址properties.put("bootstrap.servers","127.0.0.1:9092");// 设置String的序列化properties.put("key.serializer", StringSerializer.class);// 设置value的自定义序列化properties.put("value.serializer", UserSerializer.class);// 构建kafka生产者对象KafkaProducer<String,User> producer = new KafkaProducer<String, User>(properties);try {ProducerRecord<String,User> record;try {// 构建消息record = new ProducerRecord<String,User>("llp-user", "teacher",new User(1,"孙悟空"));// 发送消息producer.send(record);System.out.println("message is sent.");} catch (Exception e) {e.printStackTrace();}} finally {// 释放连接producer.close();}}
}
消费者
/*** 类说明:*/
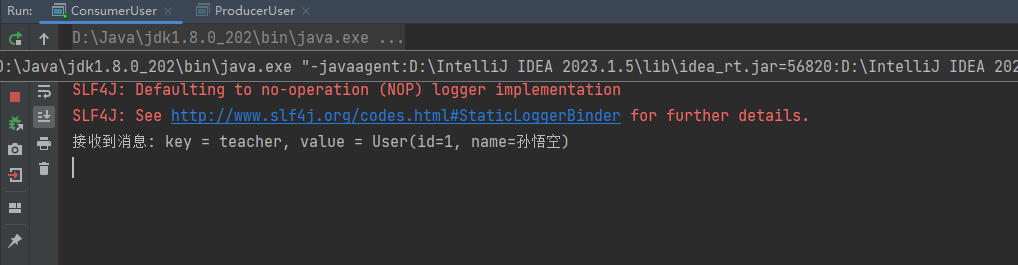
public class ConsumerUser {public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器的地址properties.put("bootstrap.servers","127.0.0.1:9092");// 设置String的反序列化properties.put("key.deserializer", StringDeserializer.class);// 设置自定义的反序列化properties.put("value.deserializer", UserDeserializer.class);properties.put(ConsumerConfig.GROUP_ID_CONFIG,"ConsumerOffsets");// 构建kafka消费者对象KafkaConsumer<String,User> consumer = new KafkaConsumer<String, User>(properties);try {consumer.subscribe(Collections.singletonList("llp-user"));// 调用消费者拉取消息while(true){// 每隔1秒拉取一次消息ConsumerRecords<String, User> records= consumer.poll(Duration.ofSeconds(1));for(ConsumerRecord<String, User> record:records){String key = record.key();User user = record.value();System.out.println("接收到消息: key = " + key + ", value = " + user.toString());}}} finally {// 释放连接consumer.close();}}
}
测试结果
自定义序列化容易导致程序的脆弱性。举例,在我们上面的实现里,我们有多种类型的消费者,每个消费者对实体字段都有各自的需求,比如,有的将字段变更为long型,有的会增加字段,这样会出现新旧消息的兼容性问题。特别是在系统升级的时候,经常会出现一部分系统升级,其余系统被迫跟着升级的情况。
解决这个问题,可以考虑使用自带格式描述以及语言无关的序列化框架。比如Protobuf,Kafka官方推荐的Apache Avro
5.分区
因为在Kafka中一个topic可以有多个partition,所以当一个生产发送消息,这条消息应该发送到哪个partition,这个过程就叫做分区。
当然,我们在新建消息的时候,我们可以指定partition,只要指定partition,那么分区器的策略则失效。

5.1 Kafka3种分区分配策略
在我们的代码中可以看到,生产者参数中是可以选择分区器的。
注意,在测试之前我修改了server.properties中每个主题默认的分区数
# 配置每个主题默认的分区数
num.partitions=4
1.DefaultPartitioner 默认分区策略
全路径类名:org.apache.kafka.clients.producer.internals.DefaultPartitioner
- 如果消息中指定了分区,则使用它
- 如果未指定分区但存在key,则根据序列化key使用murmur2哈希算法对分区数取模。
- 如果不存在分区或key,则会使用粘性分区策略
采用默认分区的方式,键的主要用途有两个:
一,用来决定消息被写往主题的哪个分区,拥有相同键的消息将被写往同一个分区。
二,还可以作为消息的附加消息。
2.RoundRobinPartitioner 分区策略
全路径类名:org.apache.kafka.clients.producer.internals.RoundRobinPartitioner
- 如果消息中指定了分区,则使用它
- 将消息平均的分配到每个分区中。
即key为null,那么这个时候一般也会采用RoundRobinPartitioner
3.UniformStickyPartitioner 纯粹的粘性分区策略
全路径类名:org.apache.kafka.clients.producer.internals.UniformStickyPartitioner
他跟DefaultPartitioner 分区策略的唯一区别就是。
DefaultPartitionerd 如果有key的话,那么它是按照key来决定分区的,这个时候并不会使用粘性分区
UniformStickyPartitioner 是不管你有没有key, 统一都用粘性分区来分配
另外关于粘性分区策略
在producer.properties中配置
# 配置生产者发送消息之前延迟多长时间在进行发送,默认0
#linger.ms=# 对发送到分区的多个记录进行批处理时的默认批处理大小(以字节为单位)默认16K
#batch.size=# 配置缓冲区的总大小,默认32M
#buffer.memory=
当linger.ms 和 batch.size有一个条件满足时,kafka客户端就会立即推送消息到kafka服务
https://bbs.huaweicloud.com/blogs/348729?utm_source=oschina&utm_medium=bbs-ex&utm_campaign=other&utm_content=content
5.2自定义分区器
在kafka中,我们可以通过实现Partitioner接口来自定义分区规则
/*** 类说明:自定义分区器,以value值进行分区*/
public class SelfPartitioner implements Partitioner {public int partition(String topic, Object key, byte[] keyBytes,Object value, byte[] valueBytes, Cluster cluster) {List<PartitionInfo> partitionInfos = cluster.partitionsForTopic(topic);int num = partitionInfos.size();// 来自DefaultPartitioner的处理,在存在key值时是根据key值去计算分区的Utils.toPositive(Utils.murmur2(serializedKey)) % numPartitions;// 我们定义一个分区器,根据value值去做计算消息所属分区int parId = Utils.toPositive(Utils.murmur2(valueBytes)) % num;return parId;}public void close() {//do nothing}public void configure(Map<String, ?> configs) {//do nothing}}
生产者,指定自定义分区器
/*** 类说明:使用value值的分区器*/
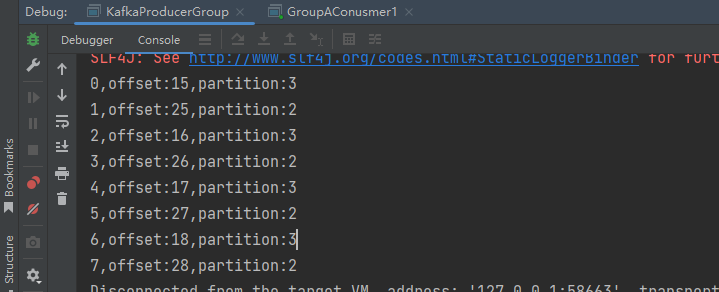
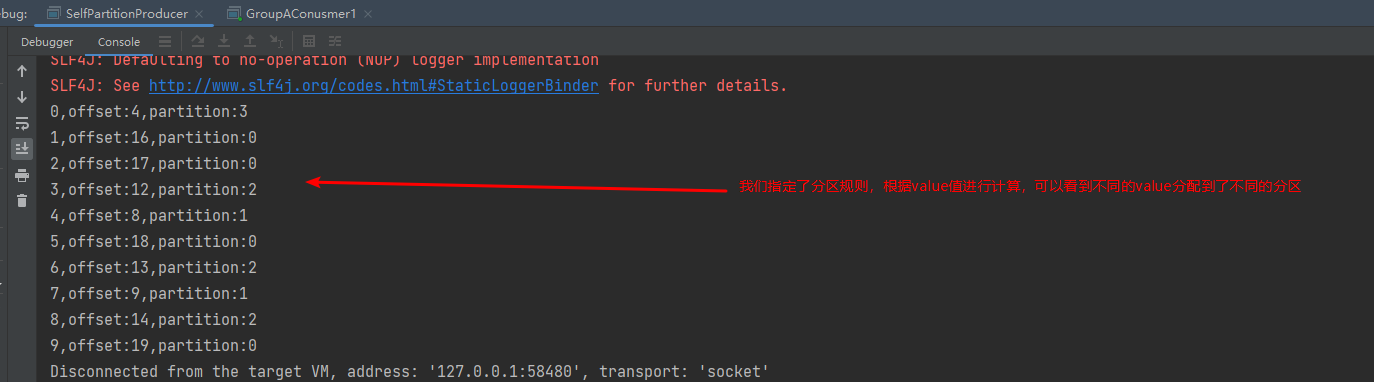
public class SelfPartitionProducer {private static KafkaProducer<String,String> producer = null;public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器的地址properties.put("bootstrap.servers","127.0.0.1:9092");// 设置String的序列化properties.put("key.serializer", StringSerializer.class);properties.put("value.serializer", StringSerializer.class);// 设置自定义分区器properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, SelfPartitioner.class);// 构建kafka生产者对象KafkaProducer<String,String> producer = new KafkaProducer<String, String>(properties);try {ProducerRecord<String,String> record;try {for (int i =0;i<10;i++){// 构建消息record = new ProducerRecord<String,String>("llp-topic1", "teacher","孙悟空"+i);// 发送消息Future<RecordMetadata> future =producer.send(record);RecordMetadata recordMetadata = future.get();if(null!=recordMetadata){System.out.println(i+","+"offset:"+recordMetadata.offset()+","+"partition:"+recordMetadata.partition());}}} catch (Exception e) {e.printStackTrace();}} finally {// 释放连接producer.close();}}}
消费者
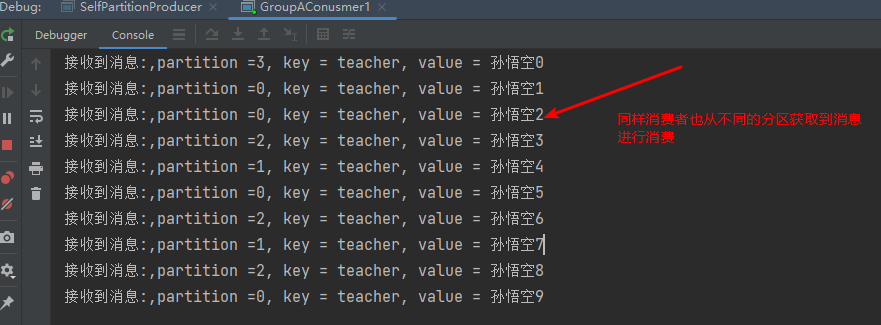
public class GroupAConusmer1 {public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器的地址properties.put("bootstrap.servers","127.0.0.1:9092");// 设置String的反序列化properties.put("key.deserializer", StringDeserializer.class);properties.put("value.deserializer", StringDeserializer.class);properties.put(ConsumerConfig.GROUP_ID_CONFIG,"groupA");// 构建kafka消费者对象KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(properties);try {consumer.subscribe(Collections.singletonList("llp-topic1"));// 调用消费者拉取消息while(true){// 每隔1秒拉取一次消息ConsumerRecords<String, String> records= consumer.poll(Duration.ofSeconds(1));for(ConsumerRecord<String, String> record:records){String key = record.key();String value = record.value();int partition = record.partition();System.out.println("接收到消息:"+",partition ="+partition +", key = " + key + ", value = " + value);}}} finally {// 释放连接consumer.close();}}}
测试结果
6.生产缓冲机制
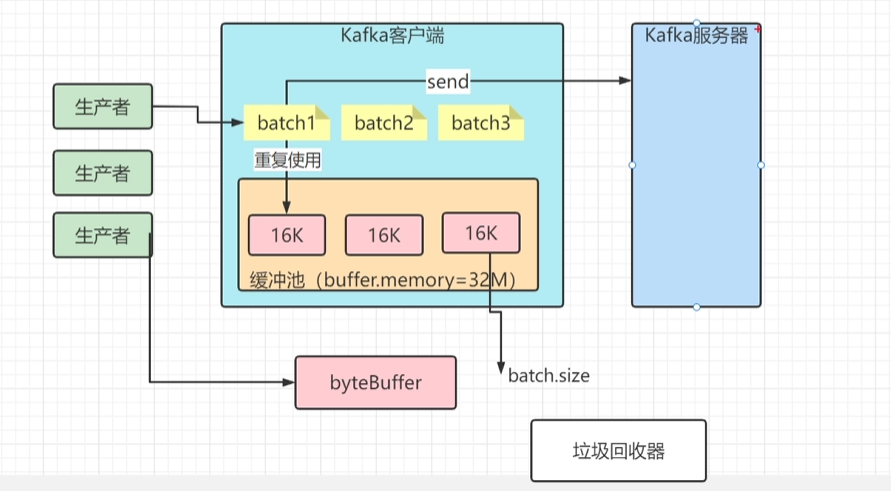
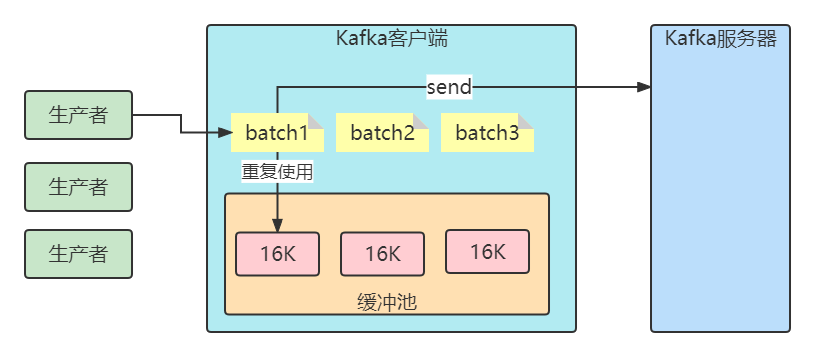
客户端发送消息给kafka服务器的时候、消息会先写入一个内存缓冲中,然后直到多条消息组成了一个Batch,才会一次网络通信把Batch发送过去。producer.properties主要有以下参数:
buffer.memory
设置生产者内存缓冲区的大小,生产者用它缓冲要发送到服务器的消息。如果数据产生速度大于向broker发送的速度,导致生产者空间不足,producer会阻塞或者抛出异常。缺省33554432 (32M)
buffer.memory: 所有缓存消息的总体大小超过这个数值后,就会触发把消息发往服务器。此时会忽略batch.size和linger.ms的限制。
buffer.memory的默认数值是32 MB,对于单个 Producer 来说,可以保证足够的性能。 需要注意的是,如果您在同一个JVM中启动多个 Producer,那么每个 Producer 都有可能占用 32 MB缓存空间,此时便有可能触发 OOM。
batch.size
当多个消息被发送同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。当批次内存被填满后,批次里的所有消息会被发送出去。但是生产者不一定都会等到批次被填满才发送,半满甚至只包含一个消息的批次也有可能被发送(linger.ms控制)。缺省16384(16k) ,如果一条消息超过了批次的大小,会写不进去。
linger.ms
指定了生产者在发送批次前等待更多消息加入批次的时间。它和batch.size以先到者为先。也就是说,一旦我们获得消息的数量够batch.size的数量了,他将会立即发送而不顾这项设置,然而如果我们获得消息字节数比batch.size设置要小的多,我们需要“linger”特定的时间以获取更多的消息。这个设置默认为0,即没有延迟。设定linger.ms=5,例如,将会减少请求数目,但是同时会增加5ms的延迟,但也会提升消息的吞吐量。
为何要设计缓冲机制
1、减少IO的开销(单个 ->批次)但是这种情况基本上也只是linger.ms配置>0的情况下才会有,因为默认inger.ms=0的,所以基本上有消息进来了就发送了,跟单条发送是差不多!!
2、减少Kafka中Java客户端的GC。
比如缓冲池大小是32MB。然后把32MB划分为N多个内存块,比如说一个内存块是16KB(batch.size),这样的话这个缓冲池里就会有很多的内存块。
你需要创建一个新的Batch,就从缓冲池里取一个16KB的内存块就可以了,然后这个Batch就不断的写入消息
下次别人再要构建一个Batch的时候,再次使用缓冲池里的内存块就好了。这样就可以利用有限的内存,对他不停的反复重复的利用。因为如果你的Batch使用完了以后是把内存块还回到缓冲池中去,那么就不涉及到垃圾回收了。
7.消费者偏移量提交
一般情况下,我们调用poll方法的时候,broker返回的是生产者写入Kafka同时kafka的消费者提交偏移量,这样可以确保消费者消息消费不丢失也不重复,所以一般情况下Kafka提供的原生的消费者是安全的,但是事情会这么完美吗?
自动提交
最简单的提交方式是让消费者自动提交偏移量。 如果enable.auto.commit被设为 true,消费者会自动把从poll()方法接收到的最大偏移量提交上去。提交时间间隔由auto.commit.interval.ms控制,默认值是5s。
自动提交是在轮询里进行的,消费者每次在进行轮询时会检査是否该提交偏移量了,如果是,那么就会提交从上一次轮询返回的偏移量。
不过,在使用这种简便的方式之前,需要知道它将会带来怎样的结果。
假设我们仍然使用默认的5s提交时间间隔, 在最近一次提交之后的3s发生了再均衡,再均衡之后,消费者从最后一次提交的偏移量位置开始读取消息。这个时候偏移量已经落后了3s,所以在这3s内到达的消息会被重复处理。可以通过修改提交时间间隔来更频繁地提交偏移量, 减小可能出现重复消息的时间窗, 不过这种情况是无法完全避免的。
在使用自动提交时,每次调用轮询方法都会把上一次调用返回的最大偏移量提交上去,它并不知道具体哪些消息已经被处理了,所以在再次调用之前最好确保所有当前调用返回的消息都已经处理完毕(enable.auto.comnit被设为 true时,在调用 close()方法之前也会进行自动提交)。一般情况下不会有什么问题,不过在处理异常或提前退出轮询时要格外小心。
/*** 类说明:消费者 手动提交: 自定义的方式*/
public class ConsumerSpecial {public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器的地址properties.put("bootstrap.servers","127.0.0.1:9092");// 设置String的反序列化properties.put("key.deserializer", StringDeserializer.class);properties.put("value.deserializer", StringDeserializer.class);properties.put(ConsumerConfig.GROUP_ID_CONFIG,"ConsumerOffsets");/*取消自动提交*/properties.put("enable.auto.commit",false);// 构建kafka消费者对象KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(properties);//当前偏移量Map<TopicPartition, OffsetAndMetadata> currOffsets = new HashMap<TopicPartition, OffsetAndMetadata>();int count = 0;try {consumer.subscribe(Collections.singletonList("llp-topic1"));// 调用消费者拉取消息while(true){// 每隔1秒拉取一次消息ConsumerRecords<String, String> records= consumer.poll(Duration.ofSeconds(1));for(ConsumerRecord<String, String> record:records){String key = record.key();String value = record.value();System.out.println("接收到消息: key = " + key + ", value = " + value);currOffsets.put(new TopicPartition(record.topic(),record.partition()),new OffsetAndMetadata(record.offset()+1,"no meta"));count++;if(count%10==0){//每10条提交一次(特定的偏移量),下一次10条数据会接着在上一次提交的偏移量后进行消费consumer.commitAsync(currOffsets,null);}}}}catch (CommitFailedException e) {System.out.println("Commit failed:");e.printStackTrace();}finally {try {consumer.commitSync(currOffsets);//同步提交(这里也可以)} finally {consumer.close();}}}}
消费者的配置参数
auto.offset.reset
earliest
当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
latest
当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
只要group.Id不变,不管auto.offset.reset 设置成什么值,都从上一次的消费结束的地方开始消费。
/*** 类说明:消费者入门:自动提交的消费模式*/
public class GroupBConusmer1 {public static void main(String[] args) {// 设置属性Properties properties = new Properties();// 指定连接的kafka服务器的地址properties.put("bootstrap.servers","127.0.0.1:9092");// 设置String的反序列化properties.put("key.deserializer", StringDeserializer.class);properties.put("value.deserializer", StringDeserializer.class);properties.put(ConsumerConfig.GROUP_ID_CONFIG,"groupB");properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest"); //最早:从头开始消费//properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"latest"); // 已提交的offset开始消费// 构建kafka消费者对象KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(properties);try {consumer.subscribe(Collections.singletonList("llp-topic1"));// 调用消费者拉取消息while(true){// 每隔1秒拉取一次消息ConsumerRecords<String, String> records= consumer.poll(Duration.ofSeconds(1));for(ConsumerRecord<String, String> record:records){String key = record.key();String value = record.value();int partition = record.partition();System.out.println("接收到消息:"+",partition ="+partition +", key = " + key + ", value = " + value);}}} finally {// 释放连接consumer.close();}}}