北京哪家做网站和网络推广好的个人博客
【三维重建-PatchMatchNet复现笔记】
- 1 突出贡献
- 2 数据集描述
- 3 训练PatchMatchNet
- 3.1 输入参数
- 3.2 制定数据集加载方式
1 突出贡献
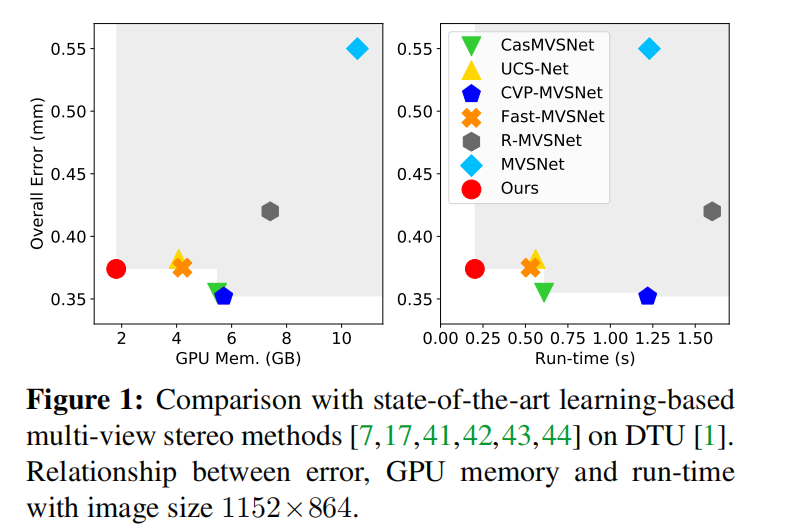
在计算机GPU和运行时间受限的情况下,PatchMatchNet测试DTU数据集能以较低GPU内存和较低运行时间,整体误差位列中等,成为2020年多视图三维重建(MVS,Multi-view Stereo)的折中方案.
特点:
高速,低内存,可以处理更高分辨率的图像,它的效率比所有现有的性能最好的模型都要高得多: 比最先进的方法至少快2.5倍,内存使用量减少一倍。
首次在端到端可训练架构中引入了迭代的多尺度Patchmatch,并用一种新颖的、可学习的自适应传播和每次迭代的评估方案改进了传统Patchmatch核心算法。
主要贡献
基于学习的方法比传统的方法有优势,但是受限于内存和运行时间,于是将补丁匹配的想法引入到端到端可训练的深度学习中,用可学习的自适应模块增强了补丁匹配的传统传播和代价评估步骤,减少了内存消耗和运行时间。
2 数据集描述
(1)在学习PatchMatchNet之前,先了解DTU数据集的特点有助于理解算法的实现步骤,DTU数据集是一种在特定条件下拍摄的多视图数据集。其包含128种物体的多视图,分别使用64个固定的相机(表明有64个相机内、外参数)拍摄具有一定重合区域的图片。相机参数如下形式:
extrinsic(外参:旋转矩阵R、T)
0.126794 -0.880314 0.457133 -272.105
0.419456 0.465205 0.779513 -485.147
-0.898877 0.09291 0.428238 629.679
0.0 0.0 0.0 1.0intrinsic(内参:针孔相机的["fx", "fy", "cx", "cy"])
2892.33 0 823.206
0 2883.18 619.07
0 0 1425 2.5(深度的最小、最大范围值)原代码的深度顺序是先小后大
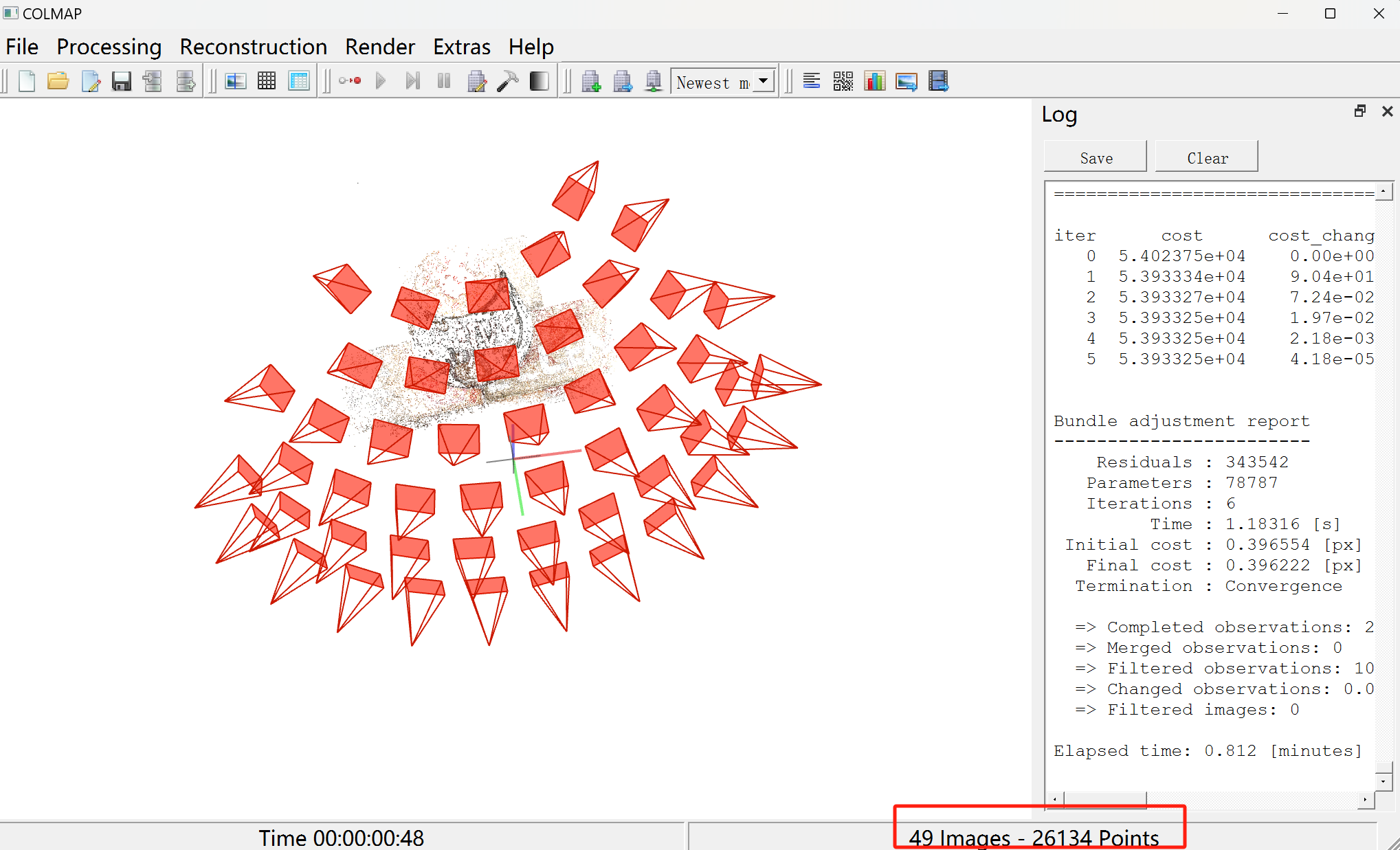
(2)使用COLMAP软件(使用方法自查)观察物体scan1的拍摄形式如下图所示 ,其中包含49张帽子图片,故在49个摄像位置进行拍摄,抓取特征点并匹配,重建产生26134个点的稀疏点云:
(3)训练的数据目录结构如下形式:
训练数据根目录+---Cameras_1(相机参数)| +---00000000_cam.txt| +---00000001_cam.txt| +---00000002_cam.txt| ......64个相机参数txt文件| +---pair.txt(视图之间重合区域匹配文件(1个))| \---train(内含64个相机参数txt文件)| +---00000000_cam.txt| +---00000001_cam.txt| +---00000002_cam.txt| ......+---Depths_raw(深度图)| +---scan1| +---depth_map_0000.pfm(pfm格式的深度图:宽160*高128)| +---depth_map_0001.pfm| +---depth_map_0002.pfm| +---depth_map_0003.pfm| ......| +---depth_visual_0044.png(png格式的可视化黑白深度图:宽160*高128)| +---depth_visual_0045.png| +---depth_visual_0046.png| +---depth_visual_0047.png| +---depth_visual_0048.png| ......| +---scan2| +---scan3| +---scan4| +---scan5| +---scan6| +---scan7| \---scan8\---Rectified+---scan1_train+---rect_001_0_r5000.png+---rect_001_1_r5000.png+---rect_001_2_r5000.png....+---scan2_train+---scan3_train+---scan4_train+---scan5_train+---scan6_train+---scan7_train\---scan8_train
这里举例了8个物体的的数据内容,一个G大小供下载测试,下载链接,其中包含两个测试数据,测试数据目录结构如下:
测试数据根目录
+---scan1
| +---cams(64个相机内外参,深度范围)
| +---cams_1(64个相机内外参,深度范围)
| +---images(49张多视角拍摄图片:宽1600*高1200)
| \---pair.txt(视图之间重合区域匹配文件(1个))
\---scan4+---cams+---cams_1\---images
测试数据与训练数据不同之处有二:
1、图片的尺寸变大了;2、不需要深度图,深度图需要使用训练好的模型计算得到,最终产生点云.ply文件.
作者将所有scan数据划分训练、验证、测试集,并放在lists文件夹中的不同的txt文件中,目录如下:
lists├─dtu│ all.txt│ test.txt│ train.txt│ val.txt
3 训练PatchMatchNet
3.1 输入参数
举例几个重要参数
"--trainpath",default="D:/AlgorithmFile/3DCoronaryTreeReconstruction/PatchmatchNet/sourceCode/PatchmatchNet-main/data/mini_dtu/train/", help="训练集的路径"(自定义)
"--epochs", type=int, default=16, help="训练轮数"(自定义)
"--batch_size", type=int, default=1, help="训练一批次的大小"(自定义)
"--loadckpt", default=None, help="加载一个特定的断点文件"(默认无)
"--parallel", action="store_true", default=False, help="如果设置,使用并行,这可以防止导出TorchScript模型."
"--patchmatch_iteration", nargs="+", type=int, default=[1, 2, 2], help="patchmatch模块在stages 1,2,3的自迭代次数"
"--patchmatch_num_sample", nargs="+", type=int, default=[8, 8, 16],help="在stages 1,2,3局部扰动的产生的样本数量"
"--patchmatch_interval_scale", nargs="+", type=float, default=[0.005, 0.0125, 0.025], help="在逆深度范围内生成局部扰动样本的归一化区间"
"--patchmatch_range", nargs="+", type=int, default=[6, 4, 2],help="补丁匹配在阶段1,2,3上传播的采样点的固定偏移")
"--propagate_neighbors", nargs="+", type=int, default=[0, 8, 16],help="自适应传播在阶段1,2,3上的邻居数目"
"--evaluate_neighbors", nargs="+", type=int, default=[9, 9, 9],help="第1、2、3阶段自适应评价的自适应匹配代价聚合的邻居个数"
3.2 制定数据集加载方式
# dataset, dataloader
train_dataset = MVSDataset(args.trainpath, args.trainlist, "train", 5, robust_train=True)
test_dataset = MVSDataset(args.valpath, args.vallist, "val", 5, robust_train=False)TrainImgLoader = DataLoader(train_dataset, args.batch_size, shuffle=True, num_workers=8, drop_last=True)
TestImgLoader = DataLoader(test_dataset, args.batch_size, shuffle=False, num_workers=4, drop_last=False)
输入:训练集的路径,训练集的train.txt列表,训练模式,待计算的5张邻域图像数(最多10张图),鲁棒性训练(在10张图中随机选择5张无序的)
MVSDataset函数的功能:
1、设定阶段数为4
2、读取训练集的列表
3、设置一个空列表metas存放【不同scan,不同光照下的light_idx索引(同一角度共有7种光照不同的图),不同的参考图ref,对应的10张邻域图src集合】
4、获取数据的方法:首先,读取一个metas元素,如果是鲁棒训练,则参考图ref+随机从10张邻域图中选择5张,否则参考图ref+顺序选前5张邻域图。
接着,
(1)从Rectified文件夹中读取校正的(宽640x高512)参考图ref和所有src(共6张彩色图,注意参考图的ID是从0-49,对应原图的ID:1-49,故读取原图是ID+1)
(2)从Depths_raw文件夹中读取深度可视化png图(宽160x高128)参考图ref和所有src(共6张彩色图),从Depths_raw文件夹中读取深度pfm图(宽160x高128)参考图ref和所有src(共6张彩色图),这两个图的ID跟参考图ID一样从0-48,故不需要加1。
(3) 从Cameras_1文件夹中读取6张不同视角下的相机内外参数和深度范围。
(4)读取的相机内参对应的是较小的图片,而现在需要更大尺寸的图片对应的内参,故需要升高相机内参,这里放大了原来的4倍。
#共六组内外参
intrinsic[:2, :] *= 4.0
intrinsics.append(intrinsic)
extrinsics.append(extrinsic)