做摄影的网站知乎新闻发布会
EasyMR 作为袋鼠云基于云原生技术和 Hadoop、Hive、Spark、Flink、Hbase、Presto 等开源大数据组件构建的弹性计算引擎。此前,我们已就其展开了多方位、多角度的详尽介绍。而此次,我们成功接入了大数据组件的升级和回滚功能,能够借助 EasyMR 来掌控大数据组件的升级与回滚流程。
在本文中,我们就将为大家详细介绍在 EasyMR 中如何接管大数据组件的升级和回滚流程。
传统大数据组件升级
大数据技术当下是全球各行业的核心技术之一,其核心要义在于把数据拆解为更小的数据块,然后在分布式的环境中加以处理。Hadoop 和 Spark 作为当前最流行的大数据处理框架,它们通过不同的方法来实现这一目标。
而在传统的大数据组件升级流程中,通常会遵循以下几个步骤:
● 环境准备
· 确保当前环境满足新版本 Spark 和 Hive 的依赖要求
· 备份当前的配置文件和重要数据
● 下载软件
· 从官方网站下载新版本的 Spark 和 Hive 安装包
● 停止服务
· 在升级前,停止所有正在运行的 Hadoop、Hive 和 Spark 服务
● 替换安装包
· 将下载的新版本 Spark 和 Hive 安装包替换旧版本的安装包
● 配置 Hive
· 解压 Hive 安装包并重命名目录
· 修改 hive-site.xml 配置文件,将旧版本的配置文件复制到新版本中,并根据新版本的要求进行必要的修改和更新
· 将 MySQL 的 JDBC 驱动放到 Hive 的 lib 目录下
● 配置 Spark
· 解压 Spark 安装包
· 配置 spark-env.sh 和 spark-defaults.conf 文件,将旧版本的配置文件复制到新版本中,并根据新版本的要求进行必要的修改和更新
· 将 Spark 的 jar 包上传到 HDFS 的特定目录下
● Hive 元数据升级
· 如果 Hive 版本有变更,可能需要使用 schematool 工具来升级 Hive 的元数据存储
● 启动服务
· 启动 Hadoop 集群和 MySQL 服务
· 启动 Hive 服务,包括 Metastore 和 HiveServer2
● 重新配置集成
· 根据新版本的要求重新配置 Spark 与 Hive 的集成,包括更新 hive-site.xml 和 spark-defaults.conf 文件
● 测试验证
· 启动 Hadoop、Hive 和 Spark 服务,执行测试查询以验证升级是否成功
在上述流程中,我们能够明显看出升级流程的繁琐。同时,大数据组件部署之间存在一定差异,例如:hbase 与其他组件不同,需要备份 zookeeper。这意味着在部署时,我们首先要将各个组件间升级的差异点和升级方案进行总结。
鉴于 Hadoop 本身的复杂性,运维人员在进行升级操作时,需要确认升级方案有无遗漏之处,一旦出现步骤遗漏,便会致使升级失败,严重情况下还可能造成数据丢失。
EasyMR 接管大数据组件升级
考虑到上述传统 Hadoop 升级所产生的复杂状况,我们决定把这种复杂性交由平台来处理,由平台接管升级过程中不同组件的差异性操作以及配置文件备份等相关操作,将简单的操作逻辑呈现给用户。
接下来,我们将从 Hive、HBase 和 Spark 组件的升级方面,来介绍 EasyMR 是如何接管大数据组件的升级流程的。
Hadoop 部署
在主机模式下部署 Hadoop 时,我们需要下载 Hadoop 的安装包,并依照步骤逐步进行操作。然而,在 EasyMR 上,我们仅需按照打包文档把打包好的产品包上传至 EasyMR 平台,即可实现一键部署。
选择需要部署的 Hadoop 服务。

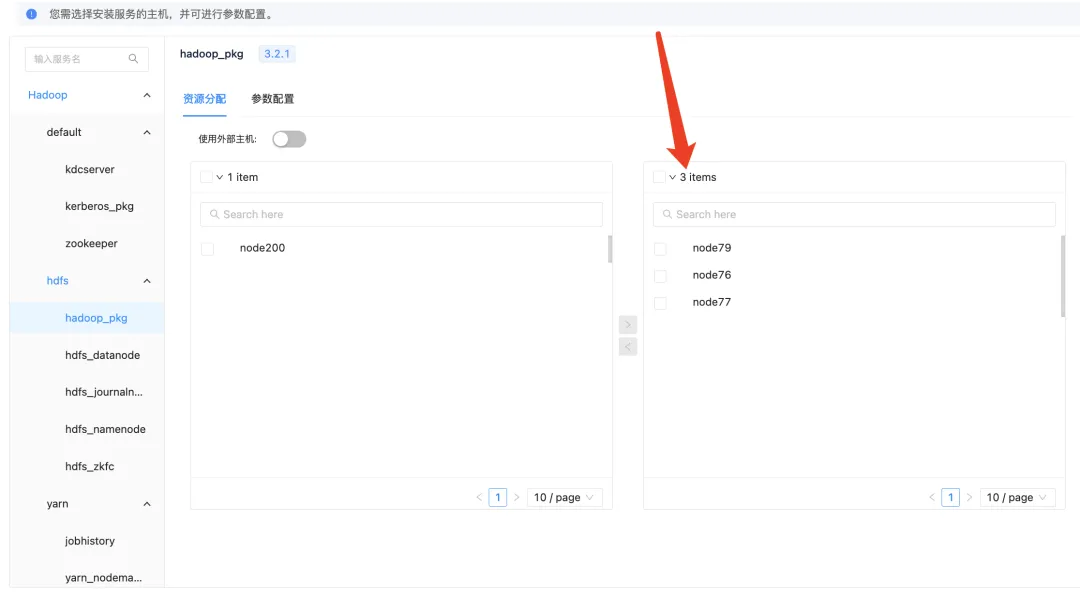
先分配服务需要部署的节点,随后执行部署,等待一段时间,若没有问题,便完成了 Hadoop 组件的部署工作。
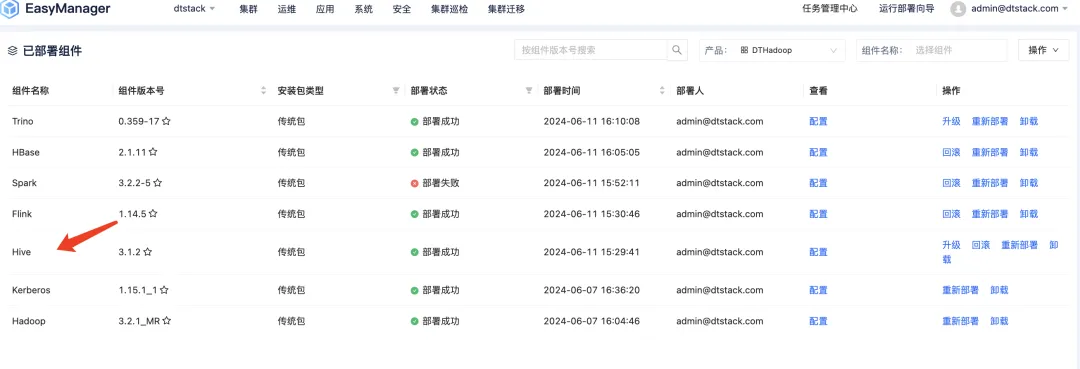
Hadoop 的升级也仅需按照上述流程操作即可,EasyMR 会首先自动停止并卸载旧服务,并且备份旧的配置文件。在上述流程顺利通过后,再进行新版本的部署。
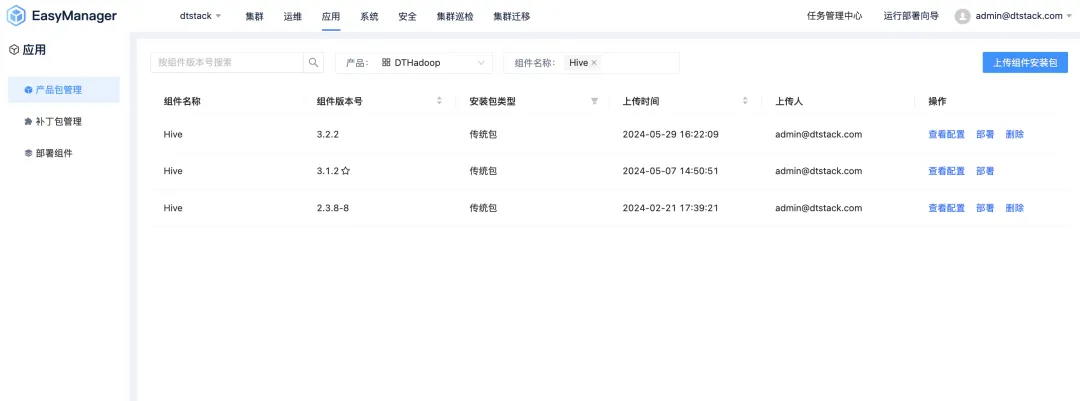
Hive 升级
上面我们已回顾了 Hadoop 组件的部署方式,接下来正式介绍 Hive 组件从 3.1.2 版本升级到 3.2.2 版本的具体步骤。
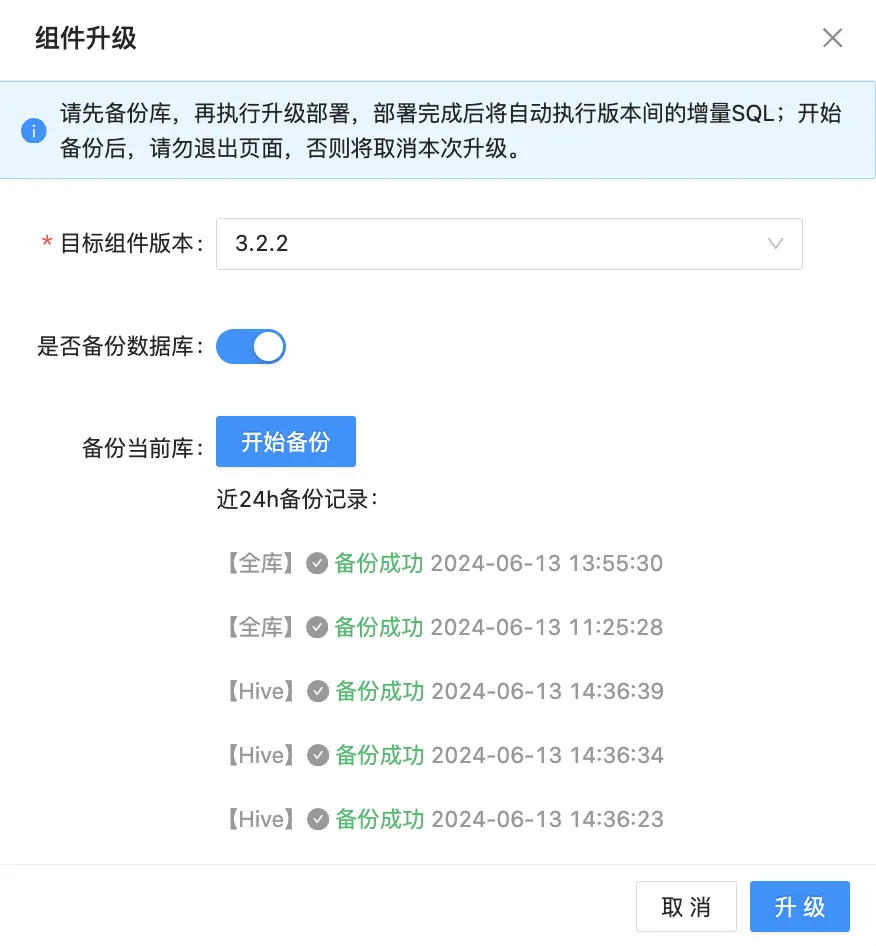
在 Hive 的升级过程中,需要先利用 mysqldump 工具对 MySQL 数据库进行备份,只有当备份成功后,方可进行后续的升级操作。
升级流程将按照 Hadoop 升级逻辑分配服务节点进行部署。

HBase 升级
HBase 升级和 Hive 升级存在差异。Hive 升级首先得备份数据库,HBase 却不用,只需操作人员在部署时确认 HBase 的兼容性问题就行。
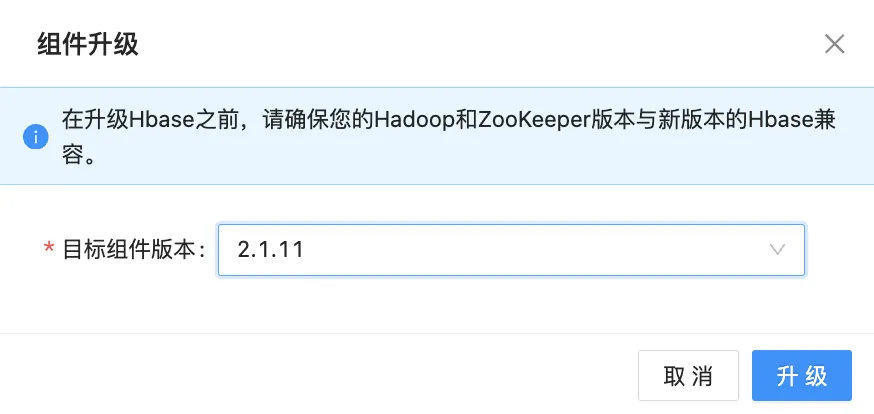
后续同样按照升级流程,勾选产品包部署服务,分配服务部署节点即可。
Spark 升级
Spark 升级时需要留意的是,有无正在运行的任务。在 Spark 升级前,会获取 yarn_resourcemanager 上运行中的任务状态,若存在,会给出提示。然后由操作人员依据当前状况决定是否强制升级。

平台管控备份流程
上面介绍了用户层面能感知到的不同服务升级的差异,下面来讲一讲在程序后台我们开展的那些操作。
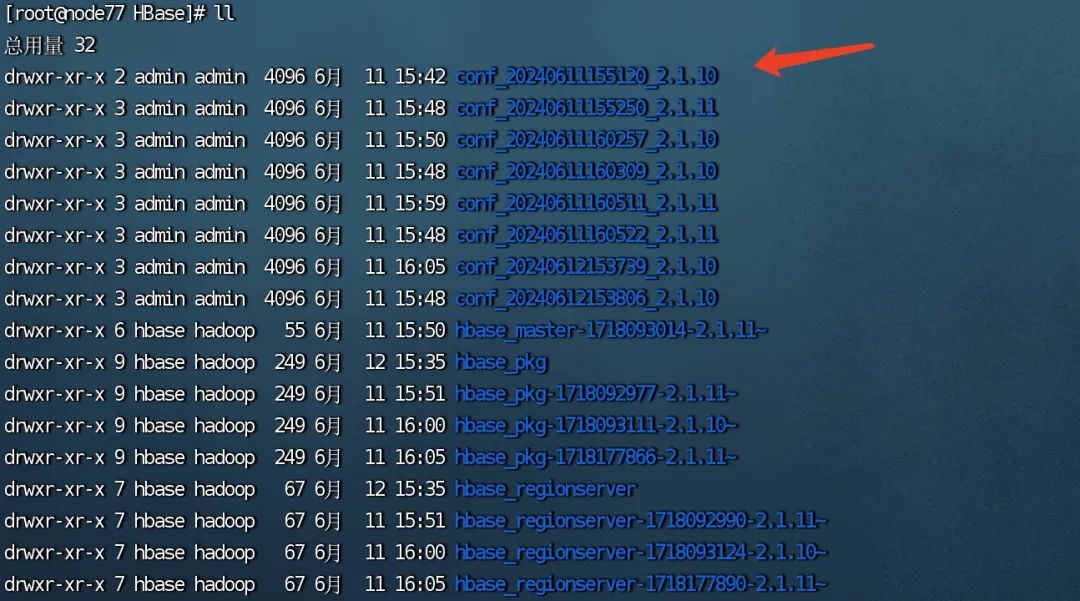
· 每次升级回滚,后台会自动将 conf 配置文件备份,防止配置丢失
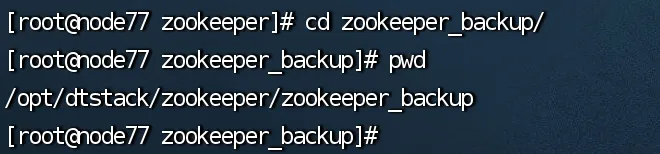
· 在 HBase 升级流程中,会先备份 zookeeper 的服务数据
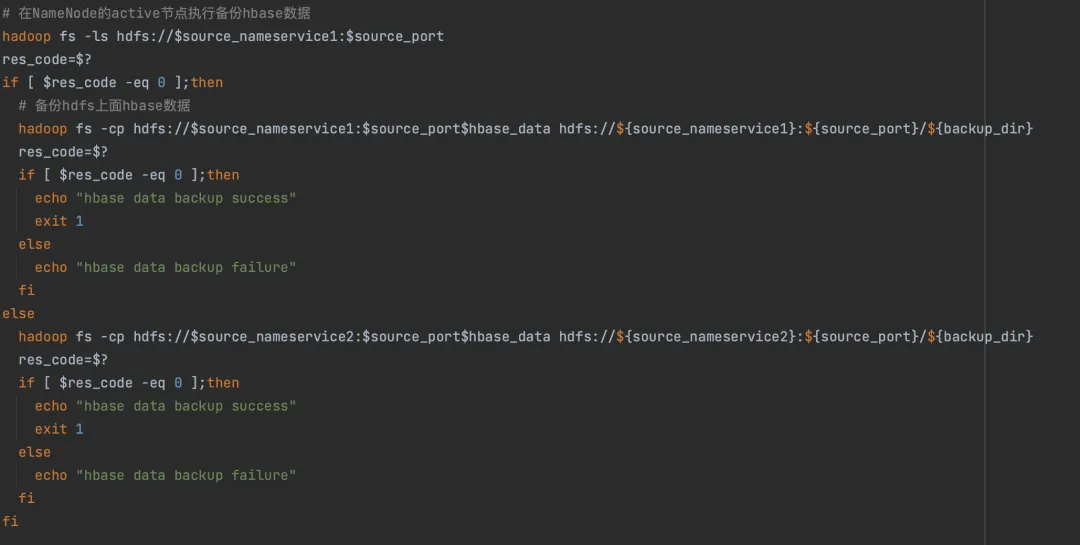
· 然后通过 grpc 服务调用 hbase_bak 备份脚本,对 Hadoop 的服务数据进行备份
经过上述操作,我们可以很轻松地在 EasyMR 上完成大数据组件的升级和回滚操作,其余服务也能通过类似步骤操作完成。
总结
在 AI 蓬勃发展的时代,数据已然成为 AI 应用中至关重要的一个环节。EasyMR 作为国产的大数据引擎,将会在大数据领域展开更为深入的探索,致力于简化大数据工具的操作难度,提高运维人员的工作效率。
《行业指标体系白皮书》下载地址:https://www.dtstack.com/resources/1057?src=szsm
《数栈产品白皮书》下载地址:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szcsdn