阿里万网怎么做网站近期10大新闻事件
Go 语言中,for-range 可以用来遍历string、数组(array)、切片(slice)、map和channel,实际使用过程踩了一些坑,所以,还是总结记录下for-range的原理。
首先,go是值传递语言。变量是指针类型,复制指针传递,变量是结构体类型,复制结构体传递,变量作为函数入参也是如此。再看下string、array、slice、map和channel的底层数据结构:
| 数据类型 | 底层结构 |
| string | 结构体:一个变量 len 、一个指针指向存储数据的字符数组 |
| array(数组) | 数组:底层分配的连续内存 |
| slice(切片) | 结构体:一个变量 len、一个变量 cap 、一个指针指向存储数据的数组。也称为动态数组 |
| map | 指向一个结构体的指针 |
| channel | 指向一个结构体的指针 |
一、for-range编译器源码
源码来自于 go GCC 版本的编译器的 statements.cc/For_range_statement::do_lowe:https://github.com/golang/gofrontend/blob/master/go/statements.cc,
编译器对 for range 表达式的解析注释如下:
// Arrange to do a loop appropriate for the type. We will produce
// for INIT ; COND ; POST {
// ITER_INIT
// INDEX = INDEX_TEMP
// VALUE = VALUE_TEMP // If there is a value
// original statements
// }可见range实际上是一个C风格的循环结构。每种类型的实现如下。
array
// The loop we generate:
// for_temp := range
// len_temp := len(for_temp)
// for index_temp = 0; index_temp < len_temp; index_temp++ {
// value_temp = for_temp[index_temp]
// index = index_temp
// value = value_temp
// original body
// }slice
// for_temp := range
// len_temp := len(for_temp)
// for index_temp = 0; index_temp < len_temp; index_temp++ {
// value_temp = for_temp[index_temp]
// index = index_temp
// value = value_temp
// original body
// }数组与数组指针的遍历过程与slice基本一致。
遍历slice前会先获得slice的长度len_temp作为循环次数,循环体中,每次循环会先获取元素值,如果for-range中接收index和value的话,则会对index和value进行一次赋值。循环开始前循环次数就已经确定了,所以循环过程中新添加的元素是没办法遍历到的。
map
// Lower a for range over a map.
// The loop we generate:
// var hiter map_iteration_struct
// for mapiterinit(type, range, &hiter); hiter.key != nil; mapiternext(&hiter) {
// index_temp = *hiter.key
// value_temp = *hiter.val
// index = index_temp
// value = value_temp
// original body
// }遍历map时没有指定循环次数,循环体与遍历slice类似。由于map底层实现与slice不同,map底层使用hash表实现,插入数据位置是随机的,所以遍历过程中新插入的数据不能保证遍历到。
channel
// Lower a for range over a channel.
// The loop we generate:
// for {
// index_temp, ok_temp = <-range
// if !ok_temp {
// break
// }
// index = index_temp
// original body
// }一直循环读数据,如果有数据则取出,如果没有则阻塞,如果channel被关闭则退出循环
string
// Lower a for range over a string.
// The loop we generate:
// len_temp := len(range)
// var next_index_temp int
// for index_temp = 0; index_temp < len_temp; index_temp = next_index_temp {
// value_temp = rune(range[index_temp])
// if value_temp < utf8.RuneSelf {
// next_index_temp = index_temp + 1
// } else {
// value_temp, next_index_temp = decoderune(range, index_temp)
// }
// index = index_temp
// value = value_temp
//
// original body
// }for-range迭代的共同点
1. 所有类型的 range 本质上都是 C 风格的for循环。
2. 遍历到的值会被赋值给一个临时变量。(赋值给临时变量的操作理论上是会产生一次数据copy)
二、for-range常见问题/坑
1. 迭代时取元素地址
strings := []string{"a", "b", "c"}// badfor index, str := range strings {fmt.Println(index, " ", str, " ", &str)}// goodfor index, str := range strings {fmt.Println(index, " ", str, " ", &strings[index])}原因:for-range迭代集合时,声明了一个临时变量,每次将集合的元素赋值给临时变量,&元素 取的一直都是临时变量的地址,并不是实际集合元素的地址。
2. 数组迭代
strings := [3]string{"a", "b", "c"}// badfor index, str := range strings {fmt.Println(index, " ", str)}// badfor index := range strings {fmt.Println(index, " ", strings[index])}// goodfor i := 0; i < len(strings); i++ {fmt.Println(i, " ", strings[i])}原因:for-range迭代数组,底层copy了一个新数组,for-range是对copy的新数组进行循环处理。2.1 for-range迭代数组时,若原数组发生数据更新不会影响到for-range的数据。
strings := [5]string{"a", "b", "c"}for index, str := range strings {strings[0], strings[1], strings[2], strings[3] = "aa", "bb", "cc", "dd"fmt.Println(index, " ", str)}fmt.Println(strings)2.2 for-range迭代数组,数组越大,效率越低,性能越差。
func BenchmarkArrayFor(b *testing.B) {for i := 0; i < b.N; i++ {strings := [1024]string{"a", "b", "c"}// goodfor i := 0; i < len(strings); i++ {_ = i_ = strings[i]}}
}
func BenchmarkArrayRange(b *testing.B) {for i := 0; i < b.N; i++ {strings := [1024]string{"a", "b", "c"}// badfor index, str := range strings {_ = index_ = str}}
}
func BenchmarkArrayRange2(b *testing.B) {for i := 0; i < b.N; i++ {strings := [1024]string{"a", "b", "c"}// badfor index := range strings {_ = index_ = strings[index]}}
}benchmark结果:
go test -bench=. -benchmemBenchmarkArrayFor-12 4597723 257.8 ns/op 0 B/op 0 allocs/op
BenchmarkArrayRange-12 2538220 486.1 ns/op 0 B/op 0 allocs/op
BenchmarkArrayRange2-12 2261341 546.4 ns/op 0 B/op 0 allocs/op
3. slice迭代、map迭代
声明一个User
type User struct {ID int64Name stringDesc stringBrother *UserByteSlice []byteByteArray [4096]byte
}var userSlice = make([]User, 10240)
var userSlicePointer = make([]*User, 10240)
var userMap = make(map[int64]User, 10240) // badfor i := 0; i < len(userSlice); i++ {_ = userSlice[i]}// goodfor _, user := range userSlice {_ = user}原因:for-range迭代简单清晰,for-range迭代slice、map不会copy底层存储数据的数组,虽然编译器初始有一次赋值操作的数据copy,但由于编译器后续的优化(一般是SSA静态单一赋值),实际for-range迭代slice、map比for可能还要更快。
3.1 for-range迭代slice时,若原slice发生数据更新会影响到for-range的数据。
strings := []string{"a", "b", "c"}for index, str := range strings {strings[0], strings[1], strings[2] = "aa", "bb", "cc"fmt.Println(index, " ", str)}fmt.Println(strings)3.2 for-range迭代slice、map比for要快
数据初始化,运行时在变量小于32B时,可能直接在栈分配空间,尽量避免这种情况:
func initUser() {for i := 0; i < 10240; i++ {userSlice[i] = User{ID: int64(i),Name: "测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称," +"测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称," +"测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称," +"测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称," +"测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称," +"测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,yzh" + strconv.Itoa(i),Desc: "测试描述哈哈哈哈 hello world",Brother: &User{ID: int64(i + 1),Name: "测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称," +"测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称," +"测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称," +"测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,测试名称,yzh" + strconv.Itoa(i),Desc: "测试描述哈哈哈哈 hello world Brother",},ByteSlice: initByte(),}}for i := 0; i < 10240; i++ {userSlicePointer[i] = &User{ID: int64(i),Name: "yzh" + strconv.Itoa(i),Desc: "测试描述哈哈哈哈 hello world",}}for i := 0; i < 10240; i++ {userMap[int64(i)] = User{ID: int64(i),Name: "yzh" + strconv.Itoa(i),Desc: "测试描述哈哈哈哈 hello world",}}
}func initByte() []byte {buf := make([]byte, 0, 4096)for i := 0; i < 4096; i++ {buf = append(buf, 'a')}return buf
}benchmark代码:
func BenchmarkForSlice(b *testing.B) {initUser()for i := 0; i < b.N; i++ {var a int64var b1 stringvar c stringvar d *Uservar e []bytefor k := 0; k < len(userSlice); k++ {a = userSlice[k].IDb1 = userSlice[k].Namec = userSlice[k].Descd = userSlice[k].Brothere = userSlice[k].ByteSlice}_ = a_ = b1_ = c_ = d_ = e}
}func BenchmarkRangeSlice(b *testing.B) {initUser()for i := 0; i < b.N; i++ {var a int64var b1 stringvar c stringvar d *Uservar e []bytefor _, user := range userSlice {a = user.IDb1 = user.Namec = user.Descd = user.Brothere = user.ByteSlice}_ = a_ = b1_ = c_ = d_ = e}
}func BenchmarkForSliceUseArray(b *testing.B) {initUser()for i := 0; i < b.N; i++ {initUser()for i := 0; i < b.N; i++ {var a int64var b1 stringvar c stringvar d *Uservar e []bytevar f [4096]bytefor k := 0; k < len(userSlice); k++ {a = userSlice[k].IDb1 = userSlice[k].Namec = userSlice[k].Descd = userSlice[k].Brothere = userSlice[k].ByteSlicef = userSlice[k].ByteArray}_ = a_ = b1_ = c_ = d_ = e_ = f}}
}func BenchmarkRangeSliceUseArray(b *testing.B) {initUser()for i := 0; i < b.N; i++ {var a int64var b1 stringvar c stringvar d *Uservar e []bytevar f [4096]bytefor _, user := range userSlice {a = user.IDb1 = user.Namec = user.Descd = user.Brothere = user.ByteSlicef = user.ByteArray}_ = a_ = b1_ = c_ = d_ = e_ = f}
}func BenchmarkForSlicePoint(b *testing.B) {initUser()for i := 0; i < b.N; i++ {var tmp stringfor k := 0; k < len(userSlicePointer); k++ {tmp = userSlicePointer[k].Name}_ = tmp}
}func BenchmarkRangeSlicePoint(b *testing.B) {initUser()for i := 0; i < b.N; i++ {var tmp stringfor _, user := range userSlicePointer {tmp = user.Name}_ = tmp}
}func BenchmarkForMap(b *testing.B) {initUser()for i := 0; i < b.N; i++ {var tmp stringfor k := 0; k < len(userMap); k++ {tmp = userMap[int64(k)].Name}_ = tmp}
}func BenchmarkRangeMap(b *testing.B) {initUser()for i := 0; i < b.N; i++ {var tmp stringfor _, user := range userMap {tmp = user.Name}_ = tmp}
}benchmark结果:
go test -bench=. -benchmemBenchmarkForSlice-12 291997 4126 ns/op 546 B/op 0 allocs/op
BenchmarkRangeSlice-12 435122 2620 ns/op 366 B/op 0 allocs/op
BenchmarkForSliceUseArray-12 594 2411410 ns/op 268768 B/op 188 allocs/op
BenchmarkRangeSliceUseArray-12 398 2942304 ns/op 401127 B/op 282 allocs/op
BenchmarkForSlicePoint-12 22102 50078 ns/op 7223 B/op 5 allocs/op
BenchmarkRangeSlicePoint-12 20089 50378 ns/op 7947 B/op 5 allocs/op
BenchmarkForMap-12 4804 242261 ns/op 33232 B/op 23 allocs/op
BenchmarkRangeMap-12 6156 192102 ns/op 25933 B/op 18 allocs/op
1、for-range迭代slice、map反而比for更快。编译器层面优化。
2、slice中存储原生类型比指针类型迭代更快。 指针类型有额外性能消耗。so,指针类型不要滥用!
3、slice中含有数组元素,未使用到数组元素时,不管是for还是for-range,都不会产生数组复制。
4、slice中含有数组元素,使用到数组元素时,for更快。for-range会复制数组。
关闭编译器优化的benchmark:
go test -c -gcflags '-N -l' ../slice.test -test.bench .BenchmarkForSlice-12 6429 162407 ns/op
BenchmarkRangeSlice-12 346 3267555 ns/op
BenchmarkForSliceUseArray-12 27 84980399 ns/op
BenchmarkRangeSliceUseArray-12 259 4216479 ns/op
BenchmarkForSlicePoint-12 8480 118691 ns/op
BenchmarkRangeSlicePoint-12 11155 104476 ns/op
BenchmarkForMap-12 2485 494308 ns/op
BenchmarkRangeMap-12 330 4379847 ns/op可以看到:在没有优化的情况下,两种loop的性能都大幅下降,并且for range下降更多,性能显著不如普通for。可以对比一下函数在正常优化(go tool compile -S xxx.go)以及关闭优化时(go tool compile -S -N -l)的汇编代码片段,会发现关闭优化后,汇编代码使用了很多中间变量存储中间结果,而优化后的代码则消除了这些中间状态。
三、for-range原理总结
1. for-range 本质上是 C 风格的for循环。
2. for-range迭代时,声明了一个临时变量,每次将迭代的元素赋值给临时变量。编译器编译阶段。
3. 理论上赋值给临时变量的操作是会产生一次数据copy,但由于编译器的优化,可能会消除实际的copy。the compiler can eliminate the actual copy if it doesn't make any difference
4. for-range概念上都是copy,不管是数组、slice、map,迭代的都是值拷贝对象。数组是copy一份新数组,slice、map是copy一份新slice、map,但不会copy底层存储数据的结构。
四、for-range vs for最佳实践
1. for-range迭代集合时取元素地址使用 &集合[index],而不是 &元素。
2. 数组迭代推荐使用for,避免使用for-range迭代数组,特别是大数组。
3. slice、map等引用类型推荐使用for-range迭代。
4. slice、map中含有数组元素,数组元素较大时,推荐使用for迭代。
Go编译代码
编译阶段
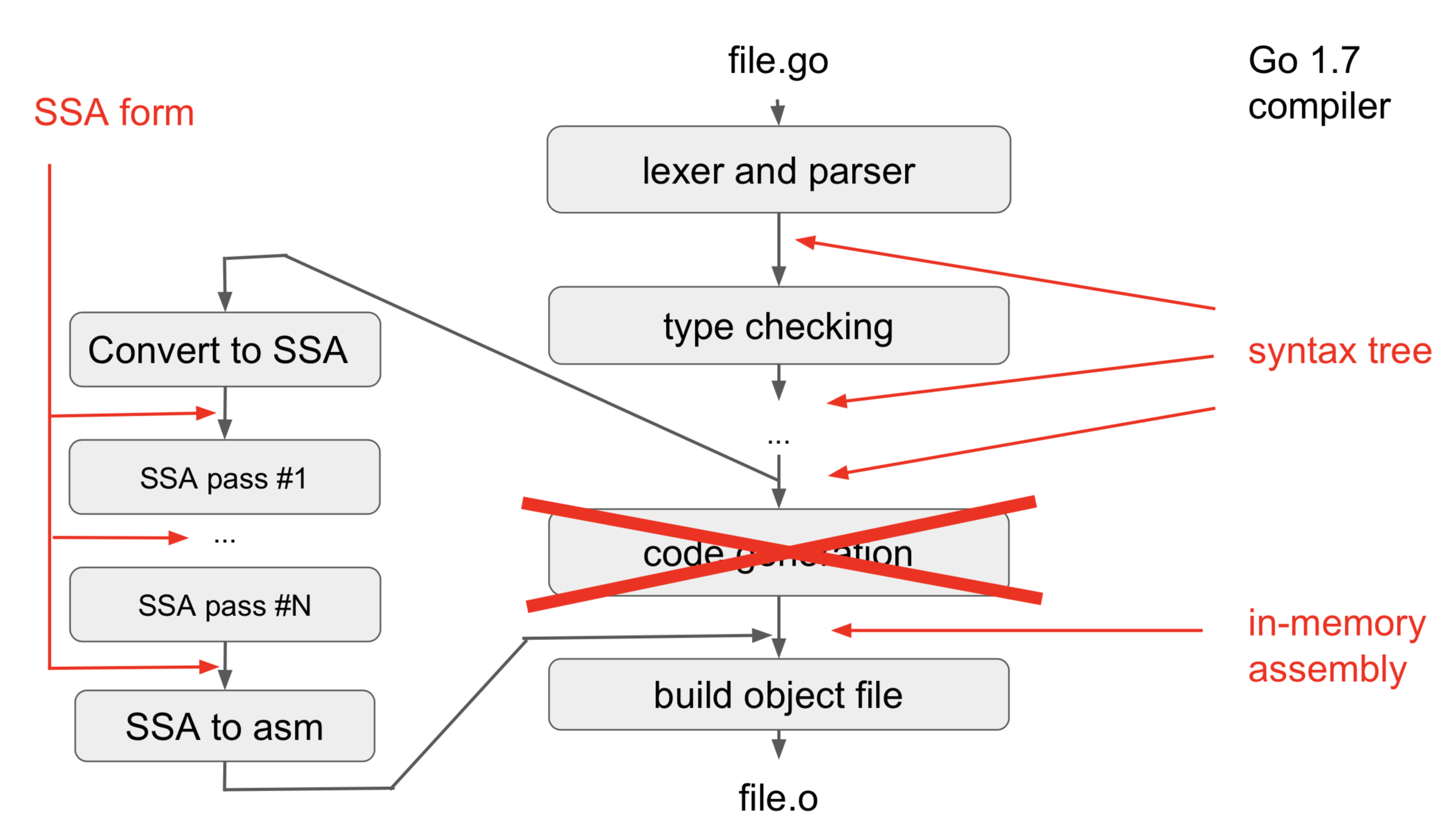
在将给定源语言的一个程序翻译成特定的目标机器代码的过程中,一个编译器可能构造出一系列中间表示(IR),如下图:

高层中间表示更接近于源语言,而低层的中间表示则更接近于目标机器。在Go编译过程中,如果说内联优化使用的IR是高层中间表示,那么低层中间表示非支持静态单赋值(SSA)的中间代码形式莫属。
编译优化
go编译器的优化主要分为内联优化和静态单一赋值。
静态单一赋值(SSA)
静态单一赋值(Static Single Assignment,SSA),是一种中间代码的表示形式(IR),或者说是某种中间代码所具备的属性。具有SSA属性的IR都具有这样的特征:
1. 每个变量在使用前都需要被定义
2. 每个变量被精确地赋值一次(使得一个变量的值与它在程序中的位置无关)
下面是一个简单的例子(伪代码):
y = 1
y = 2
x = y
转换为SSA形式为:
y1 = 1
y2 = 2
x1 = y2由于SSA要求每个变量只能赋值一次,因此在转换为SSA后,变量y用y1和y2来表示,后面的序号越大,表明y的版本越新。从这一段三行的代码我们也可以看到,在SSA层面,y1 = 1这行代码就是一行死代码(dead code),即对结果不会产生影响的代码,可以在中间代码优化时被移除掉。
SSA优化在编译过程中所处的位置:
通过使用SSA而启用或增强的编译器优化算法包括:
常量传播a=3*4+5;——将计算从运行时转换为编译时,例如,将指令视为a=17;
值范围传播 – 预先计算可能的计算范围,允许提前创建分支预测
稀疏条件常量传播——范围检查一些值,允许测试预测最可能的分支
死代码消除——删除对结果没有影响的代码
全局值编号——替换产生相同结果的重复计算
部分冗余消除——删除以前在程序的某些分支中执行的重复计算
强度降低——用更便宜但等效的操作替换昂贵的操作,例如用可能更便宜的左移(乘法)或右移(除法)替换整数乘法或除以 2 的幂。
寄存器分配——优化有限数量的机器寄存器如何用于计算
普通for循环
Go 语言中的经典循环在编译器看来是一个 OFOR 类型的节点,这个节点由以下四个部分组成:
初始化循环的 Ninit;
循环的继续条件 Left;
循环体结束时执行的 Right;
循环体 NBody:
for Ninit; Left; Right {NBody
}在生成 SSA 中间代码的阶段,cmd/compile/internal/gc.state.stmt 方法在发现传入的节点类型是 OFOR 时会执行以下的代码块,这段代码会将循环中的代码分成不同的块:
func (s *state) stmt(n *Node) {switch n.Op {case OFOR, OFORUNTIL:bCond, bBody, bIncr, bEnd := ...b := s.endBlock()b.AddEdgeTo(bCond)s.startBlock(bCond)s.condBranch(n.Left, bBody, bEnd, 1)s.startBlock(bBody)s.stmtList(n.Nbody)b.AddEdgeTo(bIncr)s.startBlock(bIncr)s.stmt(n.Right)b.AddEdgeTo(bCond)s.startBlock(bEnd)}
}一个常见的 for 循环代码会被 cmd/compile/internal/gc.state.stmt 转换成下面的控制结构,该结构中包含了 4 个不同的块,这些代码块之间的连接表示汇编语言中的跳转关系,与我们理解的 for 循环控制结构没有太多的差别。
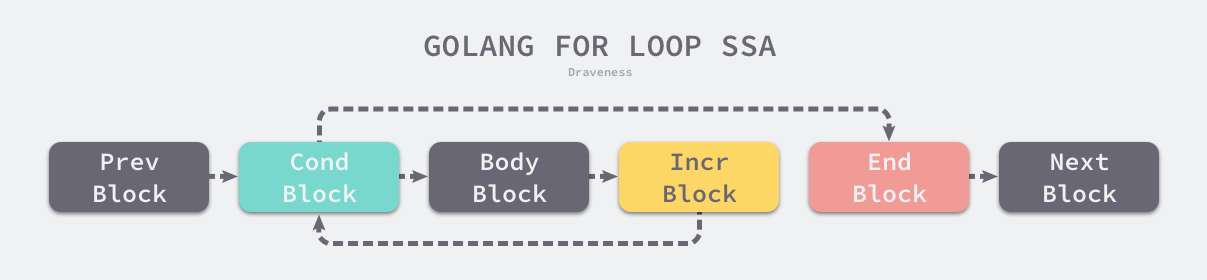
机器码生成阶段会将这些代码块转换成机器码,以及指定 CPU 架构上运行的机器语言,即汇编指令。
for-range循环
编译器会在编译期间将所有 for-range 循环变成经典循环。从编译器的视角来看,就是将 ORANGE 类型的节点转换成 OFOR 节点:

range 循环,编译期将原切片或者数组赋值给一个新变量 ha,在赋值的过程中就发生了拷贝,而我们又通过 len 关键字预先获取了切片的长度,所以在循环中追加新的元素也不会改变循环执行的次数。
而遇到同时遍历索引和元素的 range 循环时,Go 语言会额外创建一个新的 v2 变量存储切片中的元素,循环中使用的这个变量 v2 会在每一次迭代被重新赋值而覆盖,赋值时也会触发拷贝。
参考:Go 语言 for 和 range 的实现 | Go 语言设计与实现
通过实例理解Go静态单赋值(SSA) | Tony Bai