建设网站的书籍网站优化价格
文章目录
- AFL一些概念
- 插桩与覆盖率
- 边和块
- 覆盖率
- afl自实现劫持汇编器
- clang内置
- 覆盖率反馈与引导变异
- 遗传算法
- fork server机制
- AFL调试准备
AFL一些概念
插桩与覆盖率
边和块
首先,要明白边和块的定义
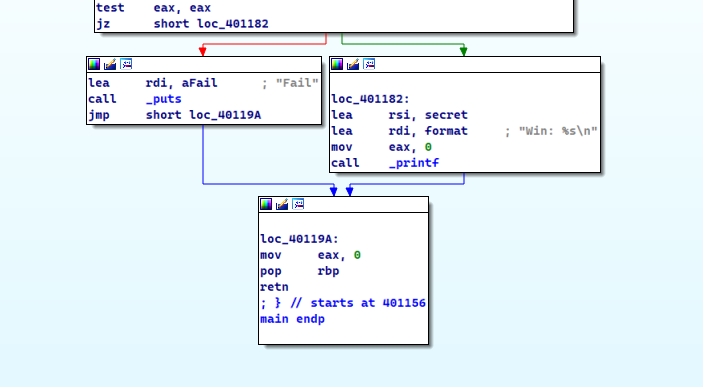
正方形的就是块,箭头表示边,边表示程序执行哪一条分支
覆盖率
程序和fuzzer执行在不同进程,要通过共享内存的方式进行进程间通信。共享内存即在多个进程之间共享,每个index索引对应一条边,执行次数增加,边的数值就会增加
各个边如何映射到索引?为每个代码块分配一个随机值,然后计算前一个代码块和当前代码块的随机值的异或值,写入共享内存索引,即代表走到哪条边,执行什么样的分支。代码块之间的执行逻辑是怎样的,执行次数是怎样的。
cur_location = <COMPILE_TIME_RANDOM>;//当前位置
shared_mem[cur_location ^ prev_location]++; //将当前位置和前一个位置异或,得到一个索引,将共享内存中该索引对应的计数器加一,表示该位置被执行了。
prev_location = cur_location >> 1;//将当前位置右移一位,作为下一次计算的前一个位置。
通过这种方式,AFL 可以统计出每个输入文件在程序中到达了哪些位置,从而帮助程序找到更多的路径,提高覆盖率。同时由于使用了随机数初始化,也提高了运行时的覆盖率统计随机性,避免了测试过程中出现重复的路径覆盖。
afl自实现劫持汇编器
在将程序转换为二进制代码的过程中。可以劫持汇编器。识别其中的跳转指令,插入汇编指令(即以上一小段的边映射为核心的代码),通过afl-gcc/afl-clang/afl-g++实现
afl-gcc会通过设置环境变量的方式,添加一些必要的参数和宏定义,以及设置一些搜索路径和链接选项。然后会将实际地链接任务交给gcc,也就是说afl-gcc仅仅是一层wrapper
ubuntu20@ubuntu20-virtual-machine:~/Desktop/afl$ ./afl-gcc ../test.c -o test
afl-cc 2.52b by <lcamtuf@google.com>arg0: gccarg1: ../test.carg2: -oarg3: testarg4: -Barg5: .arg6: -garg7: -O3clang内置
运用clang编译的时候,llvm计算出一个edge集合,每条edge对应一个guard指针
__sanitizer_cov_trace_pc_guard(uint32_t* guard)
/*执行时机: 每当对应的edge被执行到的时候,就会执行这个函
数,向共享内存里写值。写入的值就是 *guard ,即guard指针指向的值,就是为每个边
插入的随机值*/
void __sanitizer_cov_trace_pc_guard(uint32_t* guard) {__afl_area_ptr[*guard]++;
}
__sanitizer_cov_trace_pc_guard_init(uint32_t *start, uint32_t *stop)
/*每个边对应着一个guard指针指向的值,start是第一个guard
指针,代表第一条边,stop是最后一个guard指针,代表最后
一条边,遍历start到stop,就可以给每个guard指针指向的值
初始化一个随机数。*/
/*afl-llvm-rt.o.c里while遍历,然后赋一个随机数*/
while (start < stop) {
/*分别指向覆盖记录数组的起始地址和结束地址。通过一个 while 循环,逐个遍历数组中的元素。*/if (R(100) < inst_ratio) *start = R(MAP_SIZE - 1) + 1;//给guard指针赋一个随机数else *start = 0;start++;}
AFL 会以一定的概率(由 inst_ratio 决定)为其赋一个随机数,或者赋值为 0。这里的随机数是指在 1 和 MAP_SIZE - 1 之间的一个随机整数。在程序运行时,这个随机数会用于辅助判断当前指令是否已经被执行过。
如果 guard 上的值不是 0,则认为这个指令是第一次执行。在第一次执行之后,__sanitizer_cov_trace_pc_guard()会将该 guard 上的值置为 0,表示该指令已经执行过了。在后续执行过程中,如果该指令再次被执行,对应的 guard 位置上的值已经是 0,不会再次被记录为覆盖信息。因此,通过这种方法,AFL 可以辅助判断当前指令是否已经被执行过。
GCOV和LCOV主要是程序员统计代码覆盖率使用,优点是能可视化展示,不用于fuzzer
覆盖率反馈与引导变异
遗传算法
当使用afl时,需要提供一个种子,从所有种子样本进行变异。即字节流变异,翻转等。
从一个A输入变成B,C,D,E等各种不一样的输入。如果从A到B变异的输入发现了不同路径。就把这个B记录下来,称为有趣样例(interesting case)
逐代杂交选优,达到一个局部更优,解因为遗传算法的特征总是来自于初始种子样本和变异策略,所以改进也主要在这两方面进行改进
fork server机制
fuzzer变异生成样本后,写入到执行的文件(.cur_input里)
通过管道通知fork server要进行一次fuzz,fork server会fork出一个子进程去
执行这个文件,并通过管道返回子进程的执行结果的返回值,通知fuzzer。
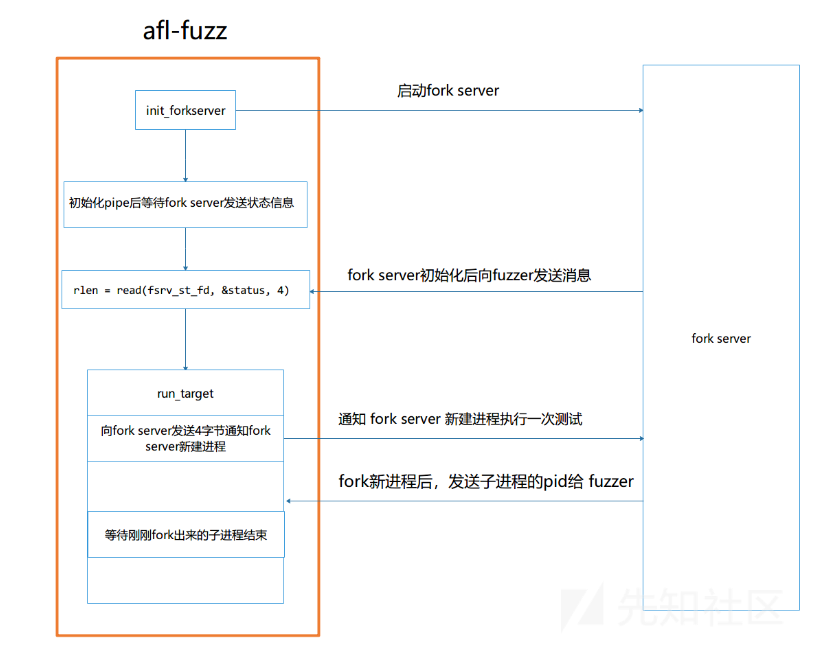
如图所示,程序在fuzz一个文件时,先把他卡在初始化完成,但读入数据之前
int main()
{read();
}
相当于卡在程序的read之前,当再次进行fuzz的时候,并不需要重新再把这个程序执行一遍。只想在read这里开始执行
通知fork server去fork一个子进程,让子进程读取.cur_input,开始一次执行,执行完后会把程序执行的信息返回给fuzzer
AFL调试准备
用clion打开AFLcpp
第一行,填写我们的输入的参数,首先是输入输出,以及最大分配内存以及超时时间、分隔后填入我们@@读文件,会写入.cur_input里,如果没有@@就是从标准输入中读
-i
/home/ubuntu20/Desktop/AFLcpp/test_dir/fuzz_input
-o
/home/ubuntu20/Desktop/AFLcpp/test_dir/fuzz_output
-m
none
-t
500+
--
/home/ubuntu20/fuzz/out/fuzzbuild
@@