怎样建网站最快宁波优化关键词首页排名
一、数据处理
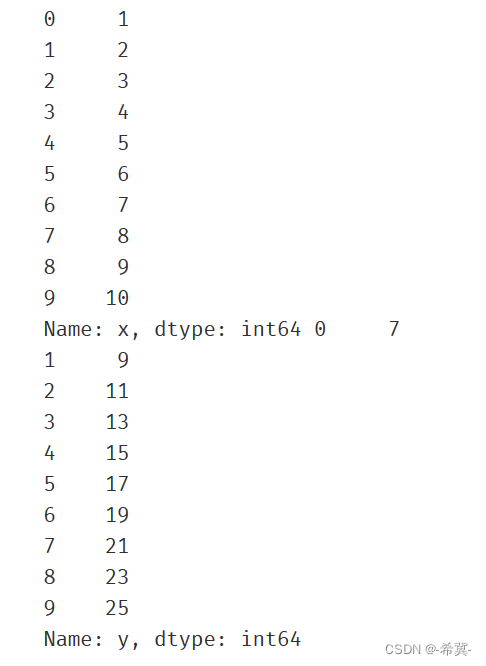
1.加载csv数据进行查看
import pandas as pd
data = pd.read_csv("generated_data.csv")
print(data)

2.将上述数据的x和y进行分离开,便于后续进行坐标建立
x = data.loc[:,'x']
y = data.loc[:,'y']
print(x,y)
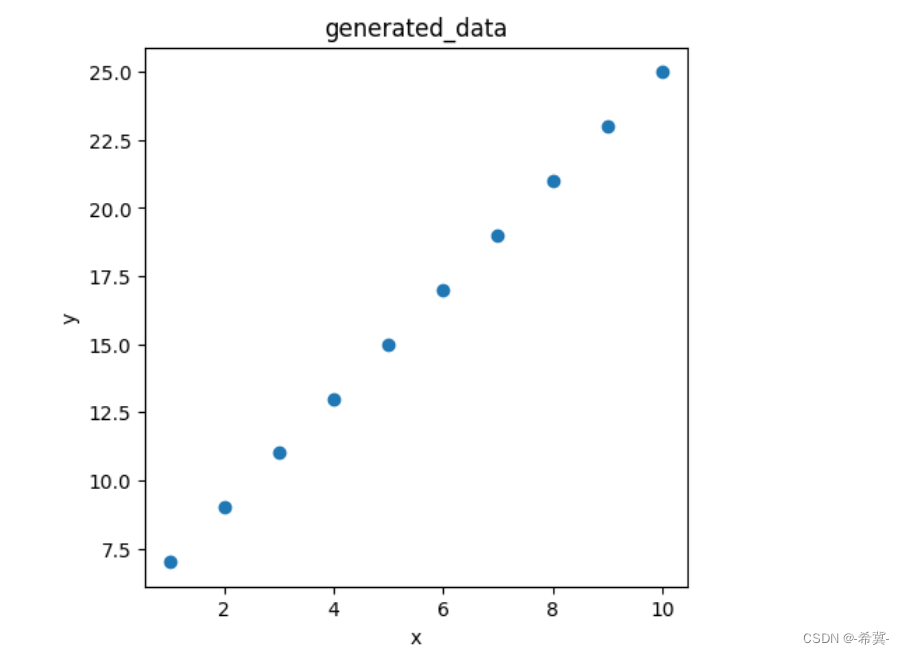
3.先使用matplotlib进行显示数据
from matplotlib import pyplot as plt
# 绘制散点图
plt.figure(figsize=(5,5))
plt.title('generated_data')
plt.xlabel('x')
plt.ylabel('y')
plt.scatter(x,y)
plt.show()
二、使用sklearn建立线性模型
1.使用LinearRegression
from sklearn.linear_model import LinearRegression
lr_model = LinearRegression()
print(type(lr_model)) # <class 'sklearn.linear_model._base.LinearRegression'>
2.拟合线性回归模型
方法介绍:
linear_regression.fit(X, y, sample_weight=None)
X:数组类型
y:数组类型
weight:可选参数,样本权重
查看上述数据中x和y的类型以及维度
print(type(x),type(y))
print(x.shape,y.shape)

转化为数组类型,并设置维度为1列,行数自动计算
import numpy as np
x=np.array(x)
y=np.array(y)
x=x.reshape(-1,1)
y=y.reshape(-1,1)
使用fit()方法进行拟合
lr_model.fit(x,y)
3.进行预测x=3.5时的数值
y_3 = lr_model.predict([[3.5]])
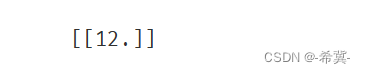
4.进行查验该线性回归模型对应的a与b的系数值
# 打印出线性模型的系数a和b
a = lr_model.coef_
b = lr_model.intercept_
print(a,b)

即对应y = 2*x+5
三、进行模型评估
使用均方误差和决定系数进行模型的评估
均方误差越小,说明模型的预测越准确
决定系数越接近于1,说明模型的拟合程度越好
from sklearn.metrics import mean_squared_error,r2_score
y_pre=lr_model.predict(x)
Mse = mean_squared_error(y,y_pre)
R2 = r2_score(y,y_pre)
print(Mse,R2)
3.1554436208840474e-31 1.0
说明均方误差是比较小的,几乎接近0,拟合程度完美