太原企业自助建站各类资源关键词
Apriori算法由R. Agrawal和R. Srikant于1994年在数据集中寻找布尔关联规则的频繁项集。该算法的名称是Apriori,因为它使用了频繁项集属性的先验知识。我们应用迭代方法或逐层搜索,其中k-频繁项集用于找到k+1个项集。
为了提高频繁项集逐层生成的效率,使用了一个重要的属性Apriori属性,该属性有助于减少搜索空间。
Apriori属性
频繁项集的所有非空子集必须是频繁项集。Apriori算法的核心概念是支持度的反单调性。Apriori假设,
频繁项集的所有子集必须是频繁的(Apriori属性)。
如果一个项集是不频繁的,那么它的所有超集都是不频繁的。
在我们开始理解算法之前,可以看看前一篇文章中解释过的一些定义。
考虑以下数据集,我们将找到频繁项集并为其生成关联规则。
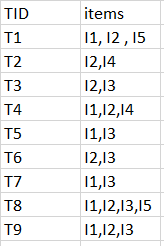
最小支持计数为2
最低置信度为60%
步骤1:K=1
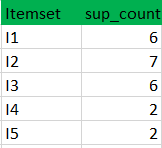
(I)创建一个表,其中包含数据集中存在的每个项目的支持计数-称为C1(候选集)
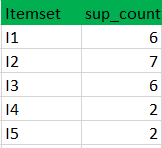
(II)将候选集合项的支持计数与最小支持计数进行比较(这里min_support=2,如果候选集合项的support_count小于min_support,则移除那些项)。这给了我们项集L1。
步骤2:K=2
- 使用L1生成候选集C2(这称为连接步骤)。连接Lk-1和Lk-1的条件是它应该具有共同的(K-2)个元素。
- 检查项目集的所有子集是否频繁,如果不频繁,则删除该项目集。({I1,I2}的示例子集是{I1},{I2},它们是频繁的。检查每个项集)
- 现在通过在dataset中搜索来找到这些项集的支持计数。
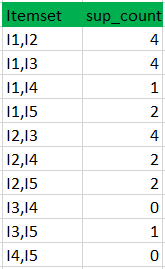
将候选(C2)支持计数与最小支持计数进行比较(这里min_support=2,如果候选集合项的support_count小于min_support,则移除那些项),这给出了项集合L2。
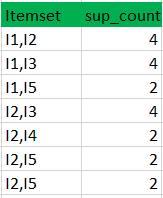
步骤3:
-
使用L2生成候选集合C3(连接步骤)。连接Lk-1和Lk-1的条件是它应该具有共同的(K-2)个元素。所以这里,对于L2,第一个元素应该匹配。
所以通过连接L2生成的项集是{I1,I2,I3}{I1,I2,I5}{I1,I3,I5}{I2,I3,I4}{I2,I4,I5}{I2,I3,I5} -
检查这些项集的所有子集是否都是频繁的,如果不是,则删除该项集。({I1,I2,I3}的子集是{I1,I2},{I2,I3},{I1,I3},它们是频繁的。对于{I2,I3,I4},子集{I3,I4}不是频繁的,因此将其移除。类似地检查每个项集)
-
通过在数据集中搜索来找到这些剩余项集的支持计数。
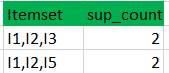
将候选(C3)支持计数与最小支持计数进行比较(这里min_support=2,如果候选集合项的support_count小于min_support,则移除那些项),这给出了项集合L3。
步骤4:
- 使用L3生成候选集合C4(连接步骤)。连接Lk-1和Lk-1(K=4)的条件是,它们应该具有(K-2)个共同元素。因此,对于L3,前两个元素(项目)应该匹配。
- 检查这些项集的所有子集是否频繁(这里通过连接L3形成的项集是{I1,I2,I3,I5},因此其子集包含{I1,I3,I5},这不是频繁的)。所以C4中没有项集
- 我们停在这里,因为没有进一步发现频繁项集
这样,我们就发现了所有的频繁项集。强关联规则的生成是目前研究的热点。为此,我们需要计算每个规则的置信度。
置信度
60%的置信度意味着60%的购买牛奶和面包的顾客也购买了黄油。
Confidence(A->B)=Support_count(A∪B)/Support_count(A)
因此,在这里,通过以任何频繁项集为例,我们将展示规则生成。
Itemset {I1, I2, I3} //from L3
SO rules can be
[I1^I2]=>[I3] //confidence = sup(I1^I2^I3)/sup(I1^I2) = 2/4*100=50%
[I1^I3]=>[I2] //confidence = sup(I1^I2^I3)/sup(I1^I3) = 2/4*100=50%
[I2^I3]=>[I1] //confidence = sup(I1^I2^I3)/sup(I2^I3) = 2/4*100=50%
[I1]=>[I2^I3] //confidence = sup(I1^I2^I3)/sup(I1) = 2/6*100=33%
[I2]=>[I1^I3] //confidence = sup(I1^I2^I3)/sup(I2) = 2/7*100=28%
[I3]=>[I1^I2] //confidence = sup(I1^I2^I3)/sup(I3) = 2/6*100=33%
因此,如果最小置信度为50%,则前3条规则可以被认为是强关联规则。
Apriori算法的局限性
Apriori算法可能很慢。主要的限制是需要时间来保持大量的候选集,具有非常频繁的项集,低的最小支持度或大的项集,即它不是一个有效的方法,用于大量的数据集。
例如,如果有104个来自频繁1-项集,则需要生成超过107个候选项到2-长度中,然后这些候选项将被测试和累积。此外,为了检测大小为100的频繁模式,即v1,v2… v100,必须生成2^100个候选项集,这导致候选项集生成的成本和时间浪费。因此,它将从候选项集中检查许多集合,并且它将多次重复地扫描数据库以寻找候选项集。当存储器容量有限且事务数量较多时,Apriori将非常低且效率低下。
[来源:https://arxiv.org/pdf/1403.3948.pdf]