企业网站怎么做seo注册平台需要什么条件
COCA20000 是美国当代语料库中最常见的 20000 个词汇,不过实际上有一些重复,去重之后大概是 17600+ 个,这些单词是很有用,如果能掌握这些单词,相信会对英语的能力有一个较大的提升。我很早就下载了这些单词,并且自己编写了一个背单词的简易工具,如果有需要的同学,可以去看我的博客中搜索。今天这篇博客是利用字典树来堆单词的一个可视化。
字典树可视化词汇
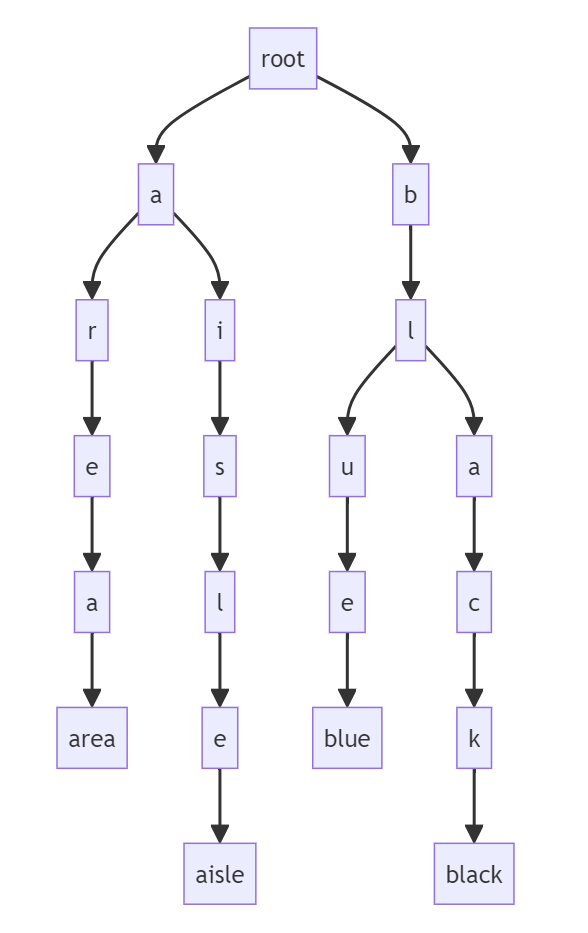
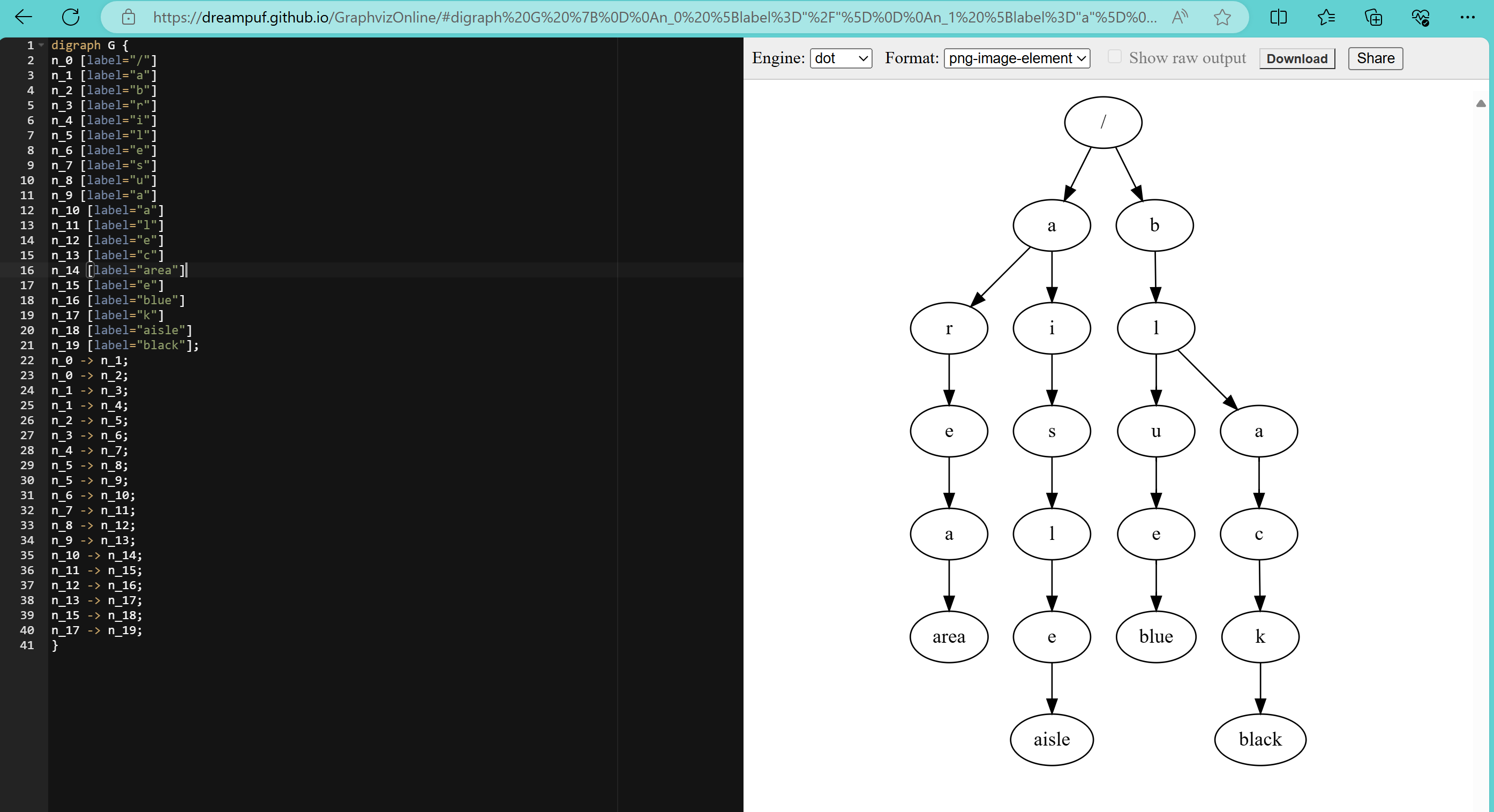
下面就是一颗简单的 4 个单词的字典树,这个东西用来检索是很快的,这里我把最后的单词作为树的叶子节点。随着单词的不断增加,整个树也会不断的膨胀,不过这样就难以阅读了,所以我最终选择是把树的排列方向变成从又到右的形式。我之后要实现的字典树和下面这个没有什么本质的区别,只是更大一些而已,利用的数据就是 COCA 20000 的单词。
上面这个图形是使用 mermaid 绘制的,不过最终我采用的是 dot 语言(绘图指令就在下面),因为 mermaid 可能会遇到性能问题。实际上,dot 语言也是遇到了性能问题,因为单词实在是太多了,导致最后的图形太大了。我想了一些可能的优化措施,比如根据首字母来区分单词,这样的化加上大小写总共 52 个字母,可以把大的树分成 52 个小一点的树。不过,我也不是真的要去看这个树,所以就没有这样做。
代码处理
下面是全部的处理代码。
"""
字典树
目的是生成 COCA 单词的字典树,但是也可以用于其他单词或者词语(包括英语)。
"""
import jsonclass Node:"""字典树的一个节点,包含这个节点的值,以及它下面的节点,以及是否是一个单词的结尾。"""def __init__(self, val, is_end) -> None:self.val = valself.is_end = is_endself.children = {}def set_is_end(self) -> None:"""有些短的单词要重新设置,否则无法和长的区分开来,例如:are, area"""self.is_end = Trueclass DictTree:"""字典树"""def __init__(self):self.root = Node('/', False)self.stack = [] # 用来保存单词def append(self, word: str):"""向字典树中添加一个单词: 获取当前树的根节点:node = self.root遍历这个词的每一个字符 c,1. 如果该字符在当前树的子树中,则把当前树的子树指向当前树: node = node.children[c]如果当前字符 c 是最后一个字符,那么: node.is_end = True2. 如果该字符不在当前树的子树中,那么新建立一个节点,如果当前字符 c 是最后一个字符:is_end = True把它添加到当前树的子树中, node.children[c] = Node(c, is_end)"""node = self.rootfor i, c in enumerate(word):is_end = not i != len(word)-1if node.children.get(c):node = node.children[c]if is_end:node.set_is_end()else:node.children[c] = Node(c, is_end)node = node.children[c]def dumps(self) -> dict:"""序列化成字典对象"""return {"/": self.__dump(self.root)}def __dump(self, node: Node) -> dict:"""序列化成字典对象的内部方法,一个简单但是并不优雅的递归"""ret = {}self.stack.append(node.val)if not node.children:ret["word"] = "".join(self.stack[1:])for k, c in node.children.items():ret[k] = self.__dump(c)self.stack.pop()return ret# 生成dot描述
# 层序遍历 tips: 使用队列
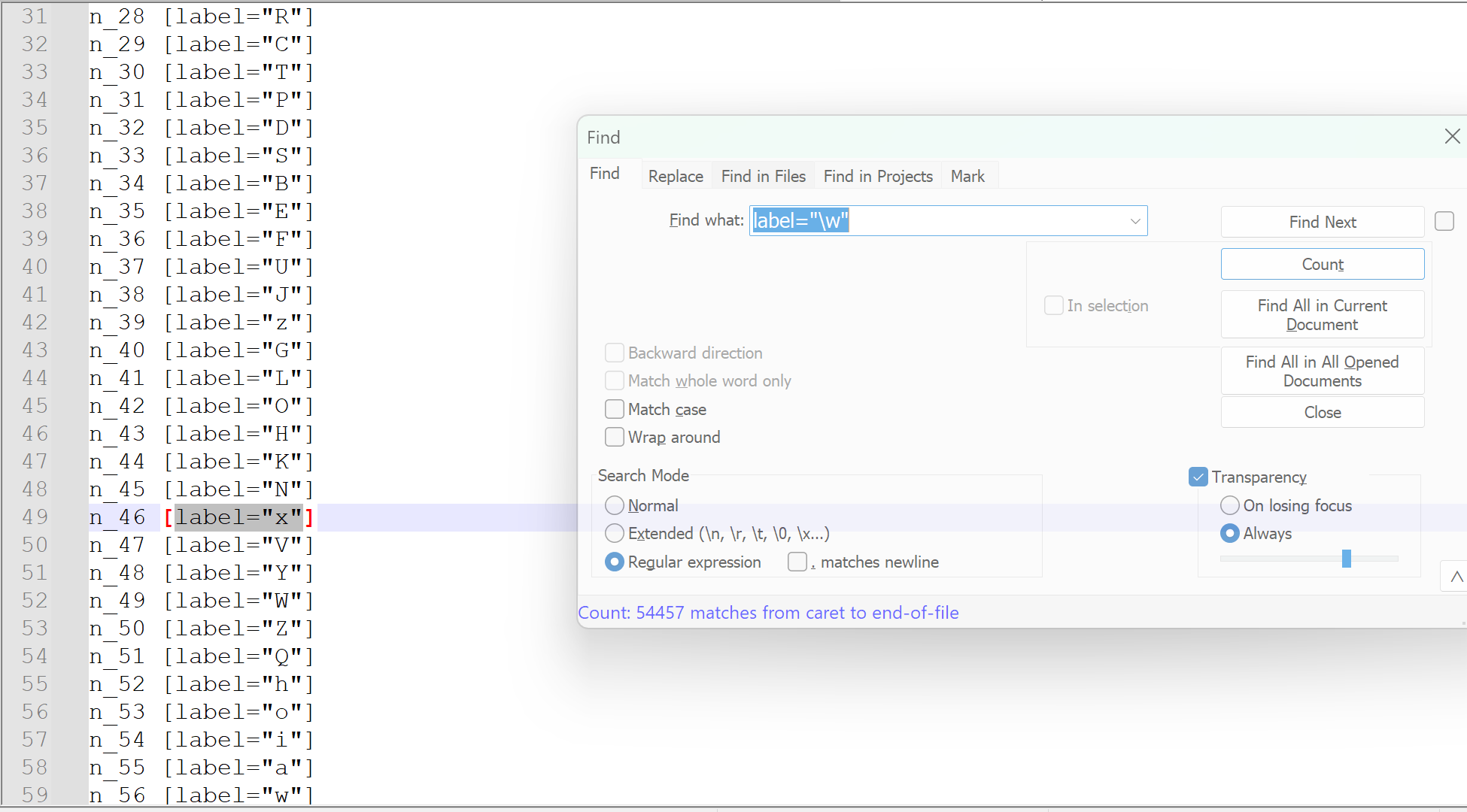
def BFS_to_dot(tree) -> str:"""将树结构以层序遍历的方式转换为Dot语言表示的图形。Dot语言用于描述图形结构,本函数特别适用于将树结构可视化。:param tree: 输入的树结构,通常是一个字典或类似字典的对象,其中键值对表示节点及其子节点。:return: 返回一个表示树结构的Dot语言字符串。"""if not tree:returnqueue = [tree["/"]] # 把树的根本身作为第一个节点加入队列count = 0 # 子节点计数parent_count = 0 # 父节点计数parent_map = {0: "/"} # 记录父节点序号和它的值nodes = ['n_0 [label="/"]'] # 点集edges = [] # 边集while queue:node = queue.pop(0)if isinstance(node, dict):for val, child in node.items():queue.append(child)count += 1v = val if val != "word" else childparent_map[count] = vdot_node = f'n_{count} [label="{v}"]'dot_edge = f"n_{parent_count} -> n_{count};"nodes.append(dot_node)edges.append(dot_edge)parent_count += 1node_str = "\n".join(nodes)edge_str = "\n".join(edges)return f"digraph G {{\nrankdir=LR;\n{node_str};\n{edge_str}\n}}"if __name__ == "__main__":in_file = r"C:\Users\25735\Desktop\DragonEnglish\data\raw_txt\coca_no_order.txt"out_json_file = r"C:\Users\25735\Desktop\DragonEnglish\data\raw_txt\coca_dt_tree.json"out_dot_file = r"C:\Users\25735\Desktop\DragonEnglish\data\raw_txt\coca_dt_tree.dot"dt = DictTree()with open(in_file, "r", encoding="utf-8") as file:for word in [line.strip() for line in file.readlines()]:dt.append(word)dt_dumps = dt.dumps()# 序列化json写入with open(out_json_file, "w", encoding="utf-8") as file:json.dump(dt_dumps, file)# dot写入with open(out_dot_file, "w", encoding="utf-8") as file:file.write(BFS_to_dot(dt_dumps))print("EOF")生成的文件
这里生成的 json 文件是压缩形式的,如果格式化的化,就超过 4m 了。

渲染图形
因为我安装了 graphviz 的插件,所以我直接在 VSCode 查看生成的 dot 文件时,它就在渲染了,不过渲染失败了。
因为这个文件太大了,有十几万行(定义的节点就有几万个了)。

所以还是在本地来生成,我已经配置好了 graphviz 的环境了。一开始是生成的 png 格式,不过它提示分辨率有问题,因为节点太多了,导致生成的图形其实没法观看了。所以最终还是选择了 svg 和 pdf 格式,其中 pdf 格式生成的特别慢,至少是 20 分钟以上了。

生成的 svg 和 pdf

这两个文件的渲染都特别费劲,我的电脑打开有点吃力了。


对它的理解
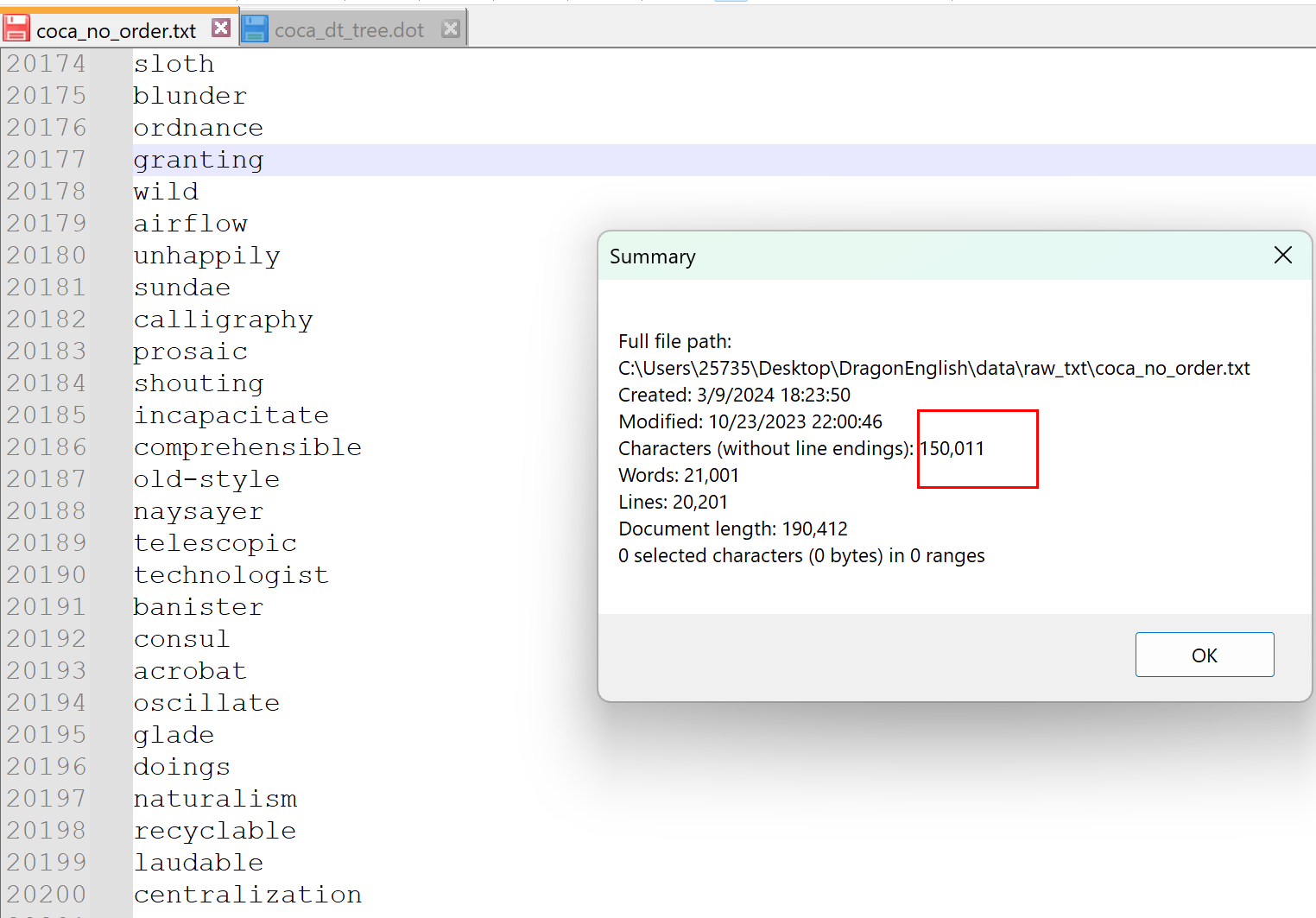
如果是这 20000 个单词,它们的字母数是 150011 个,这是一个十分庞大的数字了。但是观察上面的字典树可以发现,其实有些单词是含有共同部分的,在计算的时候可以省去这部分,对于字典树来说就是计算其中的节点数就行了。因为我把完整的单词也算做节点了,所以要只计算单个字母的节点,这里我使用正则表达式来计算,最终的结果是: 54457 个。我觉得它对于我们记忆单词有一个很好的启示,那就是我们记忆单词并不是孤立的记忆每一个单词,每个单词之间是有联系的,随着记忆的单词越多,对于单词的掌握应该也是越来越熟悉的,但是太少了还是看不出来。而且这里只有前缀的联系,实际上还包括后缀的联系等。我会把这篇博客中产生的文件上传到 CSDN 中,如果有感兴趣的同学也可以自己下载体验。