三河市城乡建设局网站蒙阴做网站
文章目录
- 一、RDD#sortBy 方法
- 1、RDD#sortBy 语法简介
- 2、RDD#sortBy 传入的函数参数分析
- 二、代码示例 - RDD#sortBy 示例
- 1、需求分析
- 2、代码示例
- 3、执行结果
一、RDD#sortBy 方法
1、RDD#sortBy 语法简介
RDD#sortBy 方法 用于 按照 指定的 键 对 RDD 中的元素进行排序 , 该方法 接受一个 函数 作为 参数 , 该函数从 RDD 中的每个元素提取 排序键 ;
根据 传入 sortBy 方法 的 函数参数 和 其它参数 , 将 RDD 中的元素按 升序 或 降序 进行排序 , 同时还可以指定 新的 RDD 对象的 分区数 ;
RDD#sortBy 语法 :
sortBy(f: (T) ⇒ U, ascending: Boolean, numPartitions: Int): RDD[T]
- 参数说明 :
- f: (T) ⇒ U 参数 : 函数 或 lambda 匿名函数 , 用于 指定 RDD 中的每个元素 的 排序键 ;
- ascending: Boolean 参数 : 排序的升降设置 , True 生序排序 , False 降序排序 ;
- numPartitions: Int 参数 : 设置 排序结果 ( 新的 RDD 对象 ) 中的 分区数 ;
- 当前没有接触到分布式 , 将该参数设置为 1 即可 , 排序完毕后是全局有序的 ;
- 返回值说明 : 返回一个新的 RDD 对象 , 其中的元素是 按照指定的 排序键 进行排序的结果 ;
2、RDD#sortBy 传入的函数参数分析
RDD#sortBy 传入的函数参数 类型为 :
(T) ⇒ U
T 是泛型 , 表示传入的参数类型可以是任意类型 ;
U 也是泛型 , 表示 函数 返回值 的类型 可以是任意类型 ;
T 类型的参数 和 U 类型的返回值 , 可以是相同的类型 , 也可以是不同的类型 ;
二、代码示例 - RDD#sortBy 示例
1、需求分析
统计 文本文件 word.txt 中出现的每个单词的个数 , 并且为每个单词出现的次数进行排序 ;
Tom Jerry
Tom Jerry Tom
Jack Jerry Jack Tom

读取文件中的内容 , 统计文件中单词的个数并排序 ;
思路 :
- 先 读取数据到 RDD 中 ,
- 然后 按照空格分割开 再展平 , 获取到每个单词 ,
- 根据上述单词列表 , 生成一个 二元元组 列表 , 列表中每个元素的 键 Key 为单词 , 值 Value 为 数字 1 ,
- 对上述 二元元组 列表 进行 聚合操作 , 相同的 键 Key 对应的 值 Value 进行相加 ;
- 将聚合后的结果的 单词出现次数作为 排序键 进行排序 , 按照升序进行排序 ;
2、代码示例
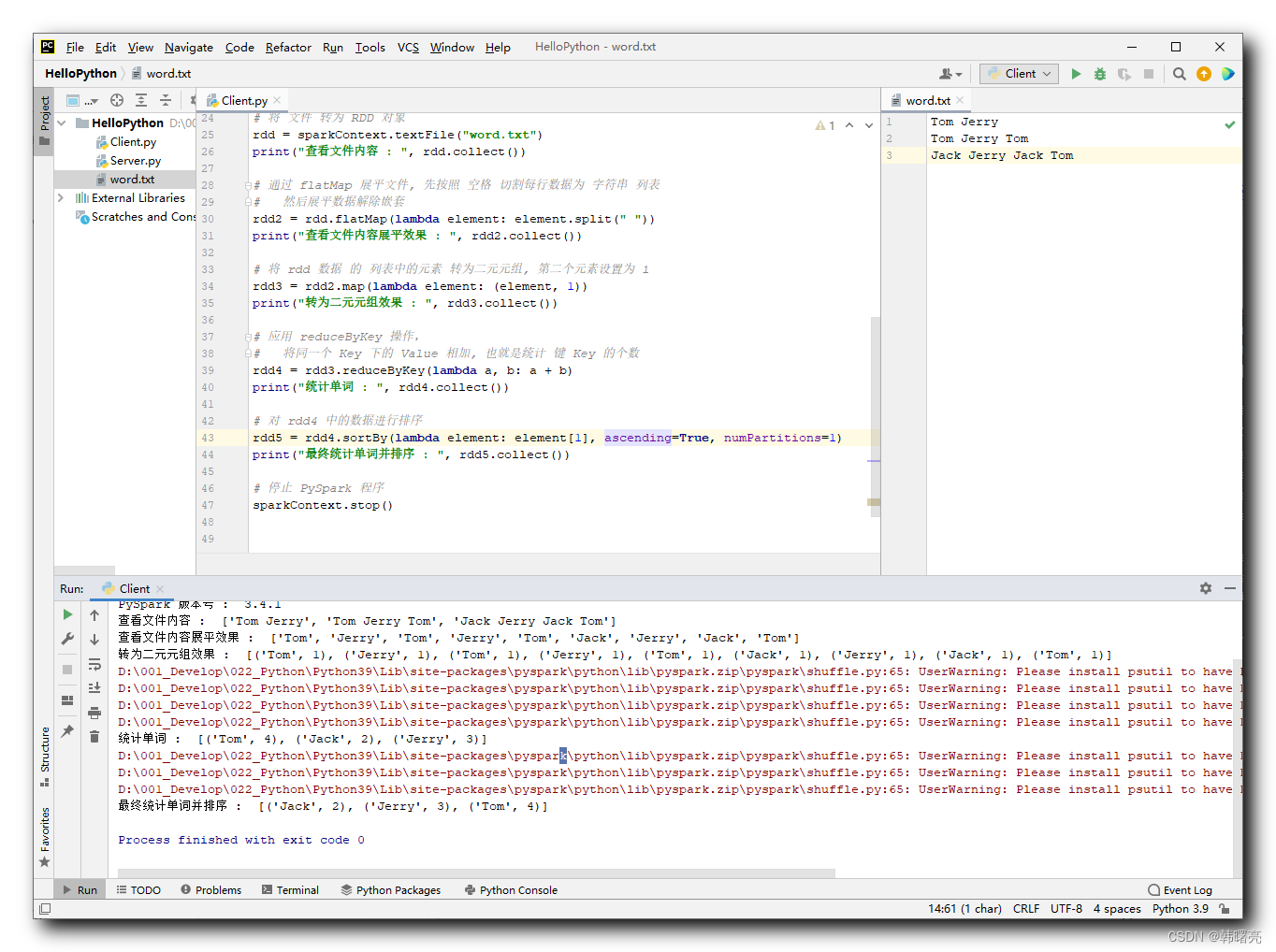
对 RDD 数据进行排序的核心代码如下 :
# 对 rdd4 中的数据进行排序
rdd5 = rdd4.sortBy(lambda element: element[1], ascending=True, numPartitions=1)
要排序的数据如下 :
[('Tom', 4), ('Jack', 2), ('Jerry', 3)]
按照上述二元元素的 第二个 元素 进行排序 , 对应的 lambda 表达式为 :
lambda element: element[1]
ascending=True 表示升序排序 ,
numPartitions=1 表示分区个数为 1 ;
排序后的结果为 :
[('Jack', 2), ('Jerry', 3), ('Tom', 4)]
代码示例 :
"""
PySpark 数据处理
"""# 导入 PySpark 相关包
from pyspark import SparkConf, SparkContext
# 为 PySpark 配置 Python 解释器
import os
os.environ['PYSPARK_PYTHON'] = "D:/001_Develop/022_Python/Python39/python.exe"# 创建 SparkConf 实例对象 , 该对象用于配置 Spark 任务
# setMaster("local[*]") 表示在单机模式下 本机运行
# setAppName("hello_spark") 是给 Spark 程序起一个名字
sparkConf = SparkConf() \.setMaster("local[*]") \.setAppName("hello_spark")# 创建 PySpark 执行环境 入口对象
sparkContext = SparkContext(conf=sparkConf)# 打印 PySpark 版本号
print("PySpark 版本号 : ", sparkContext.version)# 将 文件 转为 RDD 对象
rdd = sparkContext.textFile("word.txt")
print("查看文件内容 : ", rdd.collect())# 通过 flatMap 展平文件, 先按照 空格 切割每行数据为 字符串 列表
# 然后展平数据解除嵌套
rdd2 = rdd.flatMap(lambda element: element.split(" "))
print("查看文件内容展平效果 : ", rdd2.collect())# 将 rdd 数据 的 列表中的元素 转为二元元组, 第二个元素设置为 1
rdd3 = rdd2.map(lambda element: (element, 1))
print("转为二元元组效果 : ", rdd3.collect())# 应用 reduceByKey 操作,
# 将同一个 Key 下的 Value 相加, 也就是统计 键 Key 的个数
rdd4 = rdd3.reduceByKey(lambda a, b: a + b)
print("统计单词 : ", rdd4.collect())# 对 rdd4 中的数据进行排序
rdd5 = rdd4.sortBy(lambda element: element[1], ascending=True, numPartitions=1)
print("最终统计单词并排序 : ", rdd4.collect())# 停止 PySpark 程序
sparkContext.stop()3、执行结果
执行结果 :
D:\001_Develop\022_Python\Python39\python.exe D:/002_Project/011_Python/HelloPython/Client.py
23/08/04 10:49:06 WARN Shell: Did not find winutils.exe: java.io.FileNotFoundException: Could not locate Hadoop executable: D:\001_Develop\052_Hadoop\hadoop-3.3.4\bin\winutils.exe -see https://wiki.apache.org/hadoop/WindowsProblems
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
PySpark 版本号 : 3.4.1
查看文件内容 : ['Tom Jerry', 'Tom Jerry Tom', 'Jack Jerry Jack Tom']
查看文件内容展平效果 : ['Tom', 'Jerry', 'Tom', 'Jerry', 'Tom', 'Jack', 'Jerry', 'Jack', 'Tom']
转为二元元组效果 : [('Tom', 1), ('Jerry', 1), ('Tom', 1), ('Jerry', 1), ('Tom', 1), ('Jack', 1), ('Jerry', 1), ('Jack', 1), ('Tom', 1)]
D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
统计单词 : [('Tom', 4), ('Jack', 2), ('Jerry', 3)]
D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
最终统计单词并排序 : [('Jack', 2), ('Jerry', 3), ('Tom', 4)]Process finished with exit code 0