html百科网站模板wordpress前台登录地址
一、环境要求 Hadoop+Hive+Spark+HBase 开发环境。
二、数据描述
meituan_waimai_meishi.csv 是某外卖平台的部分外卖 SPU(Standard Product Unit , 标准产品单元)数据,包含了外卖平台某地区一时间的外卖信息。具体字段说明如下:
| 字段名称 | 中文名称 | 数据类型 |
| spu_id | 商品spuID | String |
| shop_id | 店铺ID | String |
| shop_name | 店铺名称 | String |
| category_name | 类别名称 | String |
| spu_name | SPU名称 | String |
| spu_price | SPU商品售价 | Double |
| spu_originprice | SPU商品原价 | Double |
| month_sales | 月销售量 | Int |
| praise_num | 点赞数 | Int |
| spu_unit | SPU单位 | String |
| spu_desc | SPU描述 | String |
| spu_image | 商品图片 | String |
三、功能要求
1.数据准备
在 HDFS 中创建目录/app/data/exam,并将 meituan_waimai_meishi.csv 文件传到该 目录。并通过 HDFS 命令查询出文档有多少行数据。
启动Hadoop
[root@kb135 ~]# start-all.sh
退出安全模式
[root@kb135 ~]# hdfs dfsadmin -safemode leave
上传文件
[root@kb135 examdata]# hdfs dfs -put ./meituan_waimai_meishi.csv /app/data/exam
查看数据行数
[root@kb135 examdata]# hdfs dfs -cat /app/data/exam/meituan_waimai_meishi.csv | wc -l
2.使用 Spark加载 HDFS 文件
加载meituan_waimai_meishi.csv 文件,并分别使用 RDD 和 Spark SQL 完成以下分析(不用考虑数据去重)。
Rdd:
启动spark
[root@kb135 ~]# spark-shell
创建Rdd
scala> val fileRdd = sc.textFile("/app/data/exam/meituan_waimai_meishi.csv")
清洗数据
scala> val spuRdd = fileRdd.filter(x=>x.startsWith("spu_id")==false).map(x=>x.split(",",-1)).filter(x=>x.size==12)
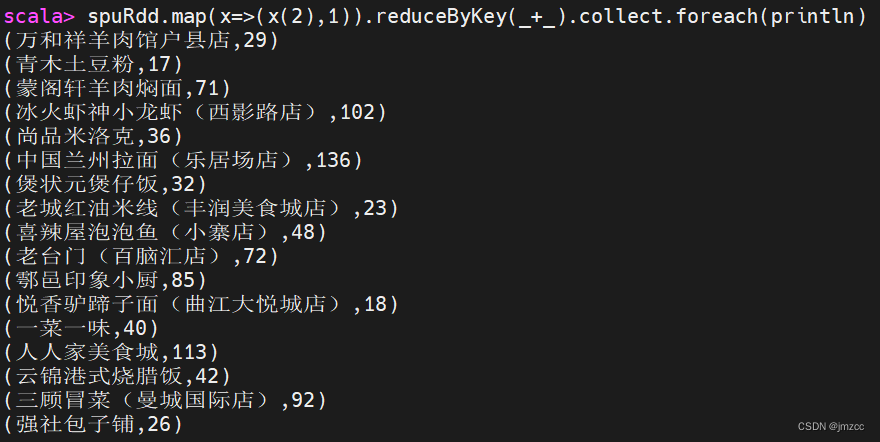
①统计每个店铺分别有多少商品(SPU)。
scala> spuRdd.map(x=>(x(2),1)).reduceByKey(_+_).collect.foreach(println)
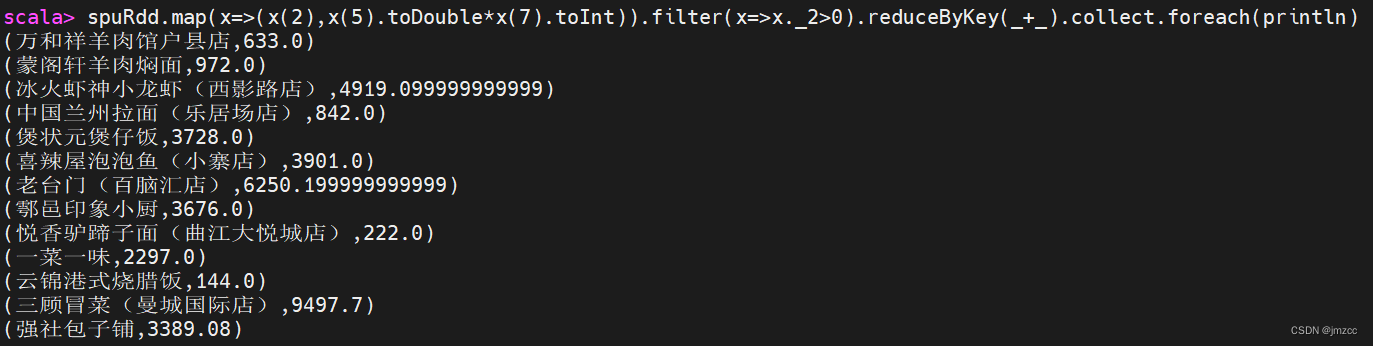
②统计每个店铺的总销售额。
scala> spuRdd.map(x=>(x(2),x(5).toDouble*x(7).toInt)).filter(x=>x._2>0).reduceByKey(_+_).collect.foreach(println)
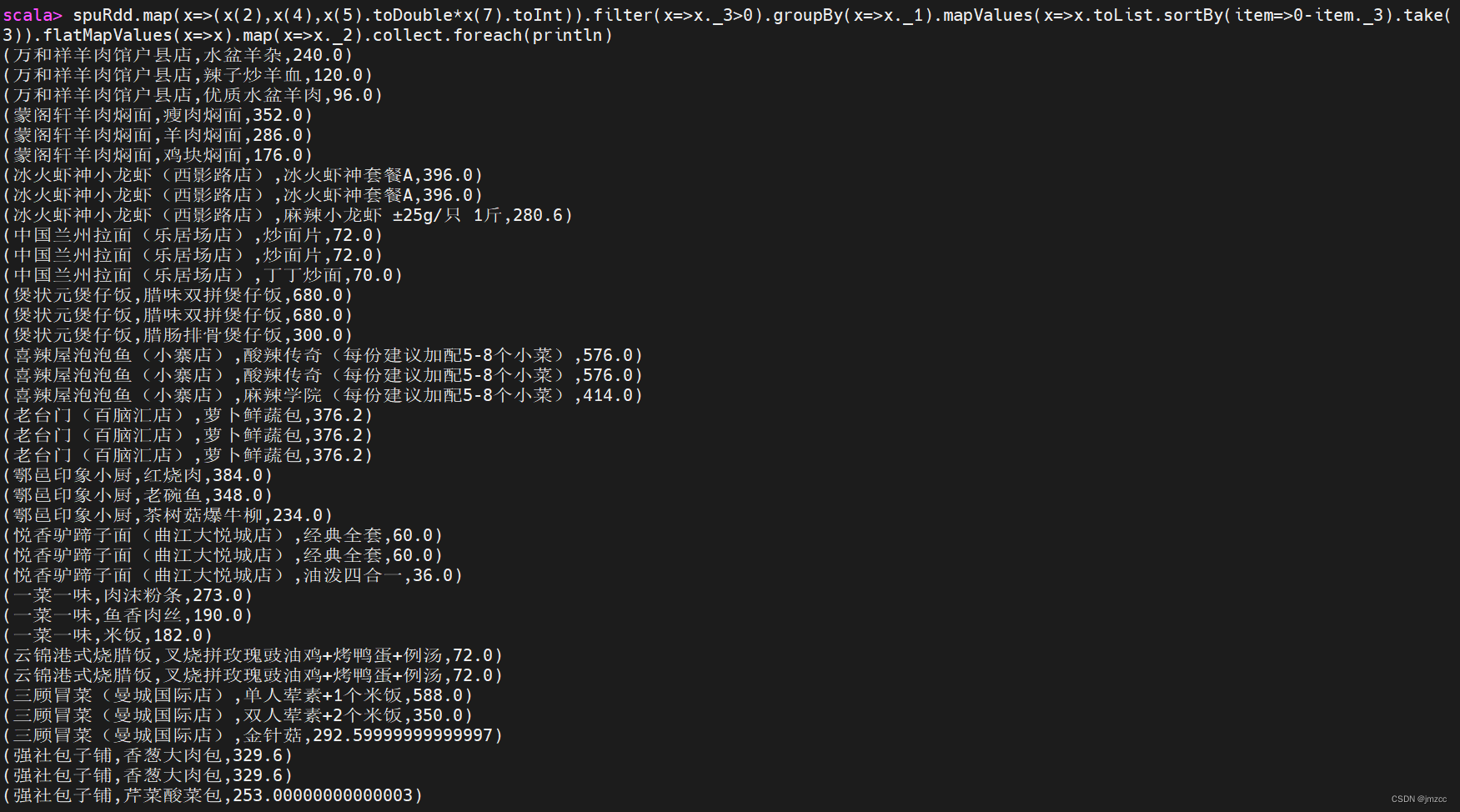
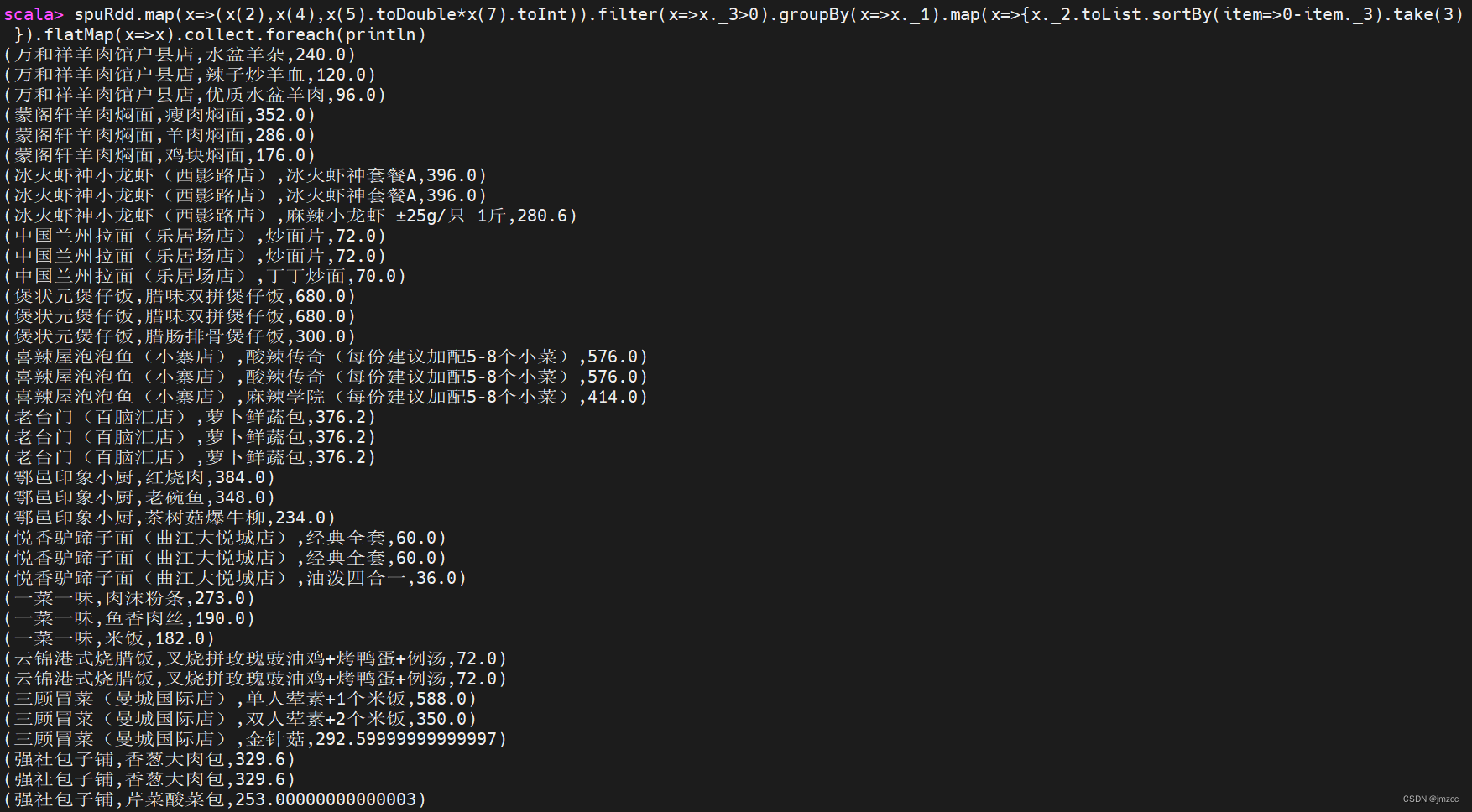
③统计每个店铺销售额最高的前三个商品,输出内容包括店铺名,商品名和销售额,其 中销售额为 0 的商品不进行统计计算,例如:如果某个店铺销售为 0,则不进行统计。
scala> spuRdd.map(x=>(x(2),x(4),x(5).toDouble*x(7).toInt)).filter(x=>x._3>0).groupBy(x=>x._1).mapValues(x=>x.toList.sortBy(item=>0-item._3).take(3)).flatMapValues(x=>x).map(x=>x._2).collect.foreach(println)
scala> spuRdd.map(x=>(x(2),x(4),x(5).toDouble*x(7).toInt)).filter(x=>x._3>0).groupBy(x=>x._1).flatMap(x=>{x._2.toList.sortBy(item=>0-item._3).take(3)}).collect.foreach(println)
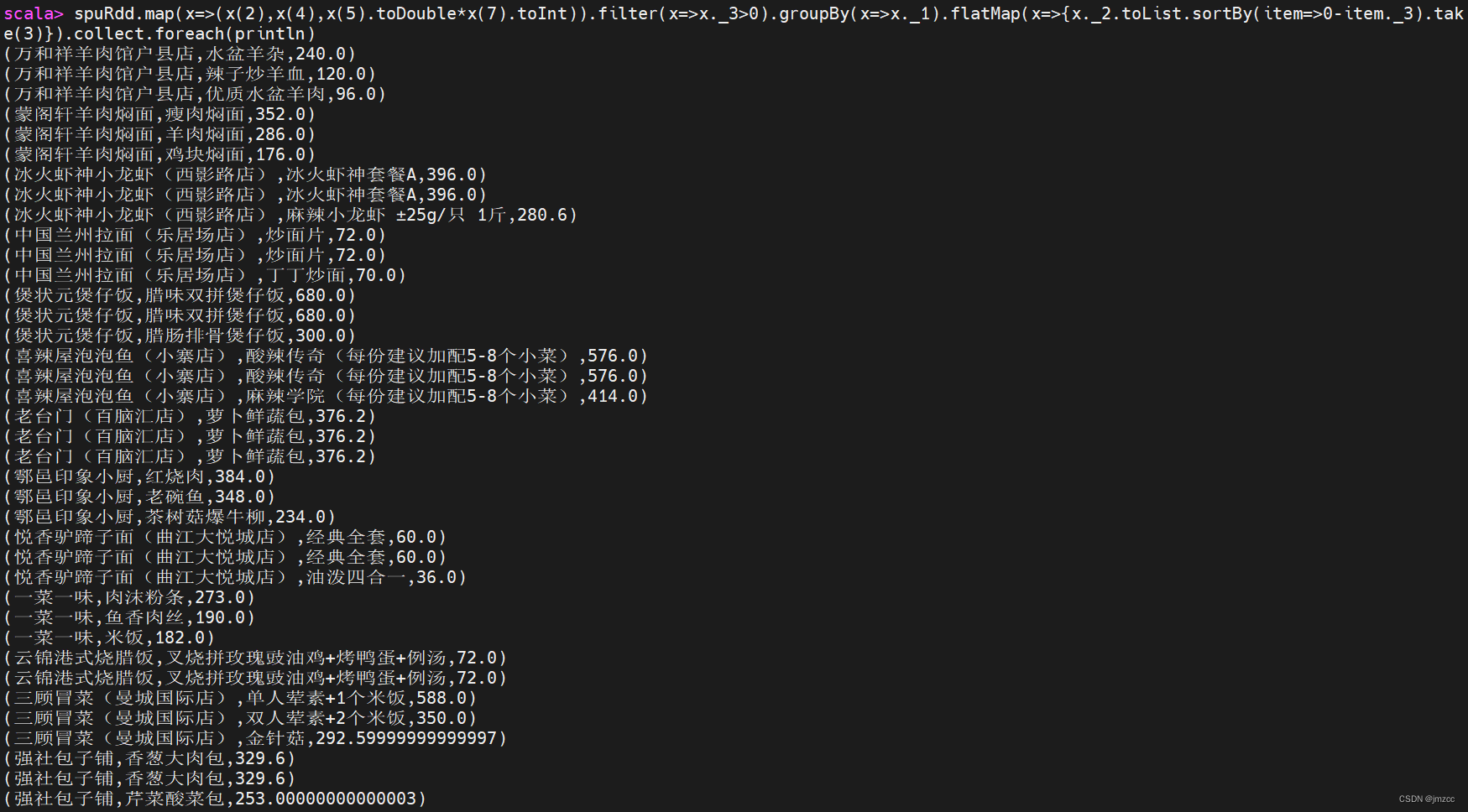
scala> spuRdd.map(x=>(x(2),x(4),x(5).toDouble*x(7).toInt)).filter(x=>x._3>0).groupBy(x=>x._1).map(x=>{x._2.toList.sortBy(item=>0-item._3).take(3) }).flatMap(x=>x).collect.foreach(println)
---------------------------------------------------------------------------------------------------------------------------------
spark sql:
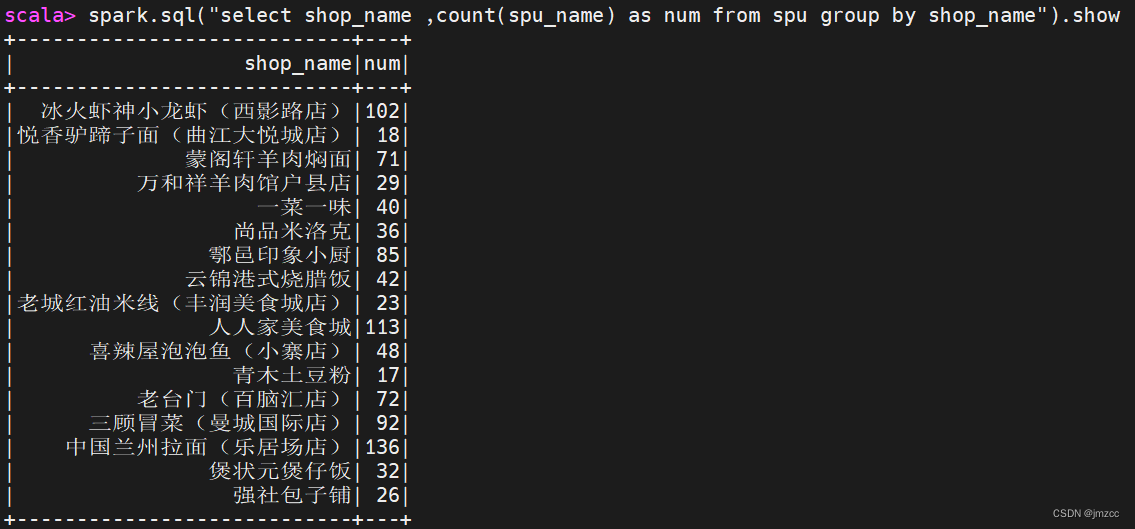
①统计每个店铺分别有多少商品(SPU)。
scala> spark.sql("select shop_name ,count(spu_name) as num from spu group by shop_name").show
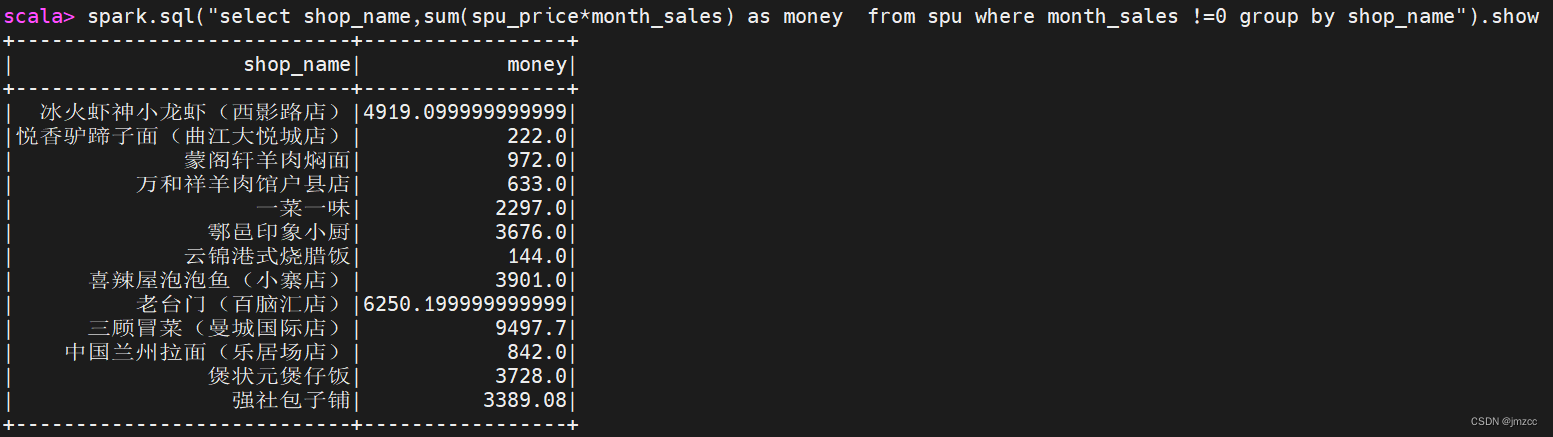
②统计每个店铺的总销售额。
scala> spark.sql("select shop_name,sum(spu_price*month_sales) as money from spu where month_sales !=0 group by shop_name").show
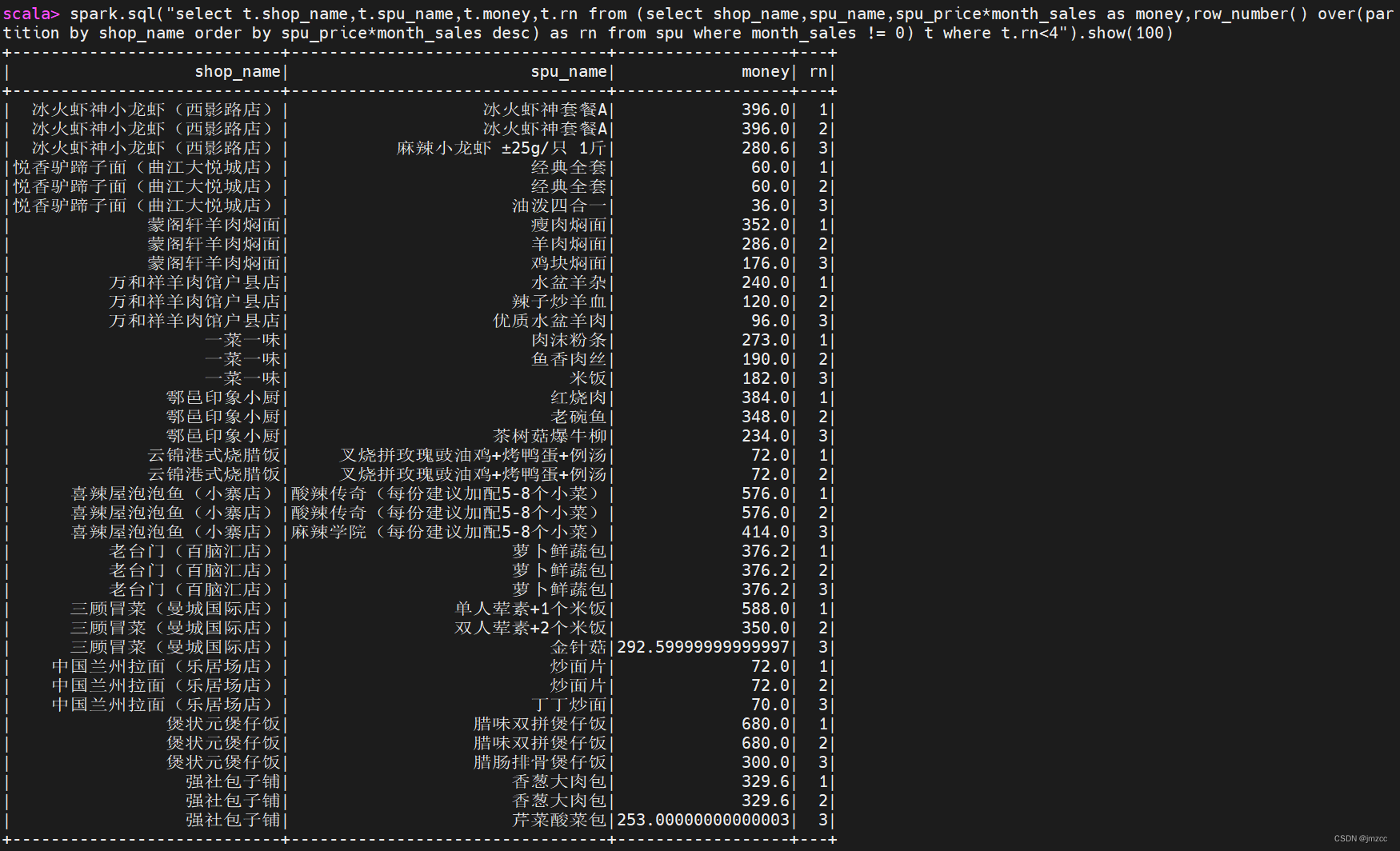
③统计每个店铺销售额最高的前三个商品,输出内容包括店铺名,商品名和销售额,其中销售额为 0 的商品不进行统计计算,例如:如果某个店铺销售为 0,则不进行统计。
scala> spark.sql("select t.shop_name,t.spu_name,t.money,t.rn from (select shop_name,spu_name,spu_price*month_sales as money,row_number() over(partition by shop_name order by spu_price*month_sales desc) as rn from spu where month_sales != 0) t where t.rn<4").show(100)
3.创建 HBase 数据表
在 HBase 中创建命名空间(namespace)exam,在该命名空间下创建 spu 表,该表下有
1 个列族 result。
启动zookeeper
[root@kb135 ~]# zkServer.sh start
启动hbase
[root@kb135 examdata]# start-hbase.sh
[root@kb135 examdata]# hbase shell
创建表空间
hbase(main):002:0> create_namespace 'exam202009'
创建表
hbase(main):003:0> create 'exam202009:spu','result'
4.在 Hive 中创建数据库 spu_db
在该数据库中创建外部表 ex_spu 指向 /app/data/exam 下的测试数据 ;创建外部表 ex_spu_hbase 映射至 HBase 中的 exam:spu 表的 result 列族
ex_spu 表结构如下:
| 字段名称 | 中文名称 | 数据类型 |
| spu_id | 商品spuID | string |
| shop_id | 店铺ID | string |
| shop_name | 店铺名称 | string |
| category_name | 类别名称 | string |
| spu_name | SPU名称 | string |
| spu_price | SPU商品价格 | double |
| spu_originprice | SPU商品原价 | double |
| month_sales | 月销售量 | int |
| praise_num | 点赞数 | int |
| spu_unit | SPU单位 | string |
| spu_desc | SPU描述 | string |
| spu_image | 商品图片 | string |
ex_spu_hbase 表结构如下:
| 字段名称 | 字段类型 | 字段含义 |
| key | string | rowkey |
| sales | double | 销售额 |
| praise | int | 点赞数 |
创建表语句:
create external table if not exists ex_spu(
spu_id string,
shop_id string,
shop_name string,
category_name string,
spu_name string,
spu_price double,
spu_originprice double,
month_sales int,
praise_num int,
spu_unit string,
spu_desc string,
spu_image string
)
row format delimited fields terminated by ","
stored as textfile location "/app/data/exam"
tblproperties("skip.header.line.count"="1");create external table if not exists ex_spu_hbase(
key string,
sales double,
praise int
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with
serdeproperties("hbase.columns.mapping"=":key,result:sales,result:praise")
tblproperties("hbase.table.name"="exam202009:spu");5. 统计查询
①统计每个店铺的总销售额 sales, 店铺的商品总点赞数 praise,并将 shop_id 和 shop_name 的组合作为 RowKey,并将结果映射到 HBase。
插入数据:
hive (spu_db)> insert into ex_spu_hbase (select concat(shop_id,shop_name) as key ,sum(spu_price*month_sales) as sales,sum(praise_num) as praise from ex_spu group by shop_id,shop_name);
②完成统计后,分别在 hive 和 HBase 中查询结果数据。
hive (spu_db)> select * from ex_spu_hbase;
hbase(main):005:0> scan 'exam202009:spu'