做网站需要服务器吗seo软件排行榜前十名
影响人工智能训练时间的因素
在深度学习训练中,训练时间的计算涉及到多个因素,包括 epoch 数、全局 batch size、微 batch size、计算设备数量等。下面是一个基本的公式来说明这些参数之间的关系(注意,这只是一个基本的说明公式,主要说明比例和反比例关系,实际训练可能还需要考虑更多因素):

他们之中-
- 时期是指模型处理整个训练数据集的次数。
- 样本总数是训练数据集中的样本总数。
- 全局批次大小是每次训练迭代中处理的数据样本总数。
- Time per Step 是每次训练迭代所需的时间,取决于硬件性能、模型复杂度、优化算法等因素。
- 设备数量是用于训练的计算设备的数量,例如 GPU 的数量。
此公式提供了一个基本框架,但请注意,实际训练时间可能受到许多其他因素的影响,包括 I/O 速度、网络延迟(对于分布式训练)、CPU-GPU 通信速度、GPU 训练期间硬件故障的频率 等。因此,此公式只能作为粗略估计,实际训练时间可能会有所不同。
详细解释
深度学习模型的训练时间由多种因素决定,包括但不限于以下因素:
- 周期数:周期表示模型处理了整个训练数据集一次。周期越多,模型需要处理的数据越多,因此训练时间越长。
- 全局批大小:全局批大小是每次训练迭代中处理的数据样本总数。全局批大小越大,每次迭代处理的数据越多,这可能会减少每个时期所需的迭代次数,从而缩短总训练时间。但是,如果全局批大小过大,可能会导致内存溢出。
- 微批次大小:微批次大小是指每个计算设备在每次训练迭代中处理的数据样本数量。微批次大小越大,每个设备每次迭代处理的数据越多,这可以提高计算效率,从而缩短训练时间。但是,如果微批次大小过大,可能会导致内存溢出。
- 硬件性能:所使用的计算设备(如 CPU、GPU)的性能也会影响训练时间。更强大的设备可以更快地进行计算,从而缩短训练时间。
- 模型复杂度:模型的复杂度(例如层数、参数数量等)也会影响训练时间。模型越复杂,需要的计算量就越多,因此训练时间越长。
- 优化算法:所使用的优化算法(例如 SGD、Adam 等)和学习率等超参数设置也会影响训练时间。
- 并行策略:数据并行、模型并行等并行计算策略的采用也会影响训练时间。
决定训练时间长短的因素有很多,需要根据具体的训练任务和环境综合考虑。
所以,在这个公式中
![]()
- 硬件性能:所使用的计算设备(如 CPU、GPU)的性能将直接影响每次训练迭代的速度。功能更强大的设备可以更快地执行计算。
- 模型复杂度:模型的复杂度(例如层数、参数数量等)也会影响每次训练迭代的时间。模型越复杂,所需的计算量就越大。
- 优化算法:所使用的优化算法(例如 SGD、Adam 等)也会影响每次训练迭代的时间。某些优化算法可能需要更复杂的计算步骤来更新模型参数。
- 训练时使用的数据类型:训练时使用的不同数据类型对每步时间有显著影响。数据类型包括FP32,FP/BF16,FP8等。
训练步骤

全局批次大小
那么,什么决定了全局批次大小?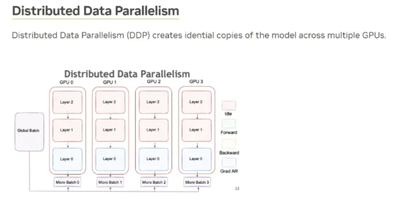
<span style="color:#333333"><span style="background-color:#ffffff"><span style="background-color:#2b2b2b"><span style="color:#f8f8f2"><code class="language-applescript">global_batch_size <span style="color:#00e0e0">=</span>
gradient_accumulation_steps
<span style="color:#00e0e0">*</span> nnodes (node mumbers)
<span style="color:#00e0e0">*</span> nproc_per_node (GPU <span style="color:#00e0e0">in</span> one node)
<span style="color:#00e0e0">*</span> per_device_train_batch_si(micro bs size) </code></span></span></span></span><span style="color:#333333"><span style="background-color:#ffffff"><span style="background-color:#2b2b2b"><span style="color:#f8f8f2"><code class="language-applescript">batch_size <span style="color:#00e0e0">=</span> <span style="color:#00e0e0">10</span> <span style="color:#d4d0ab"># Batch size </span>
total_num <span style="color:#00e0e0">=</span> <span style="color:#00e0e0">1000</span> <span style="color:#d4d0ab"># Total number of training data </span></code></span></span></span></span>当训练一批数据,更新一次梯度时(梯度累积步数=1):
<span style="background-color:#2b2b2b"><span style="color:#f8f8f2"><code class="language-applescript">train_steps <span style="color:#00e0e0">=</span> total_num <span style="color:#00e0e0">/</span> batch_size <span style="color:#00e0e0">=</span> <span style="color:#00e0e0">1000</span> <span style="color:#00e0e0">/</span> <span style="color:#00e0e0">10</span> <span style="color:#00e0e0">=</span> <span style="color:#00e0e0">100</span> </code></span></span>
这意味着每个 epoch 有 100 个步骤,梯度更新步骤也是 100。
当内存不足以支持 10 的批大小时,我们可以使用梯度累积来减少每个微批的大小。假设我们将梯度累积步骤设置为 2:
<span style="background-color:#2b2b2b"><span style="color:#f8f8f2"><code class="language-applescript">gradient_accumulation_steps <span style="color:#00e0e0">=</span> <span style="color:#00e0e0">2</span>
micro_batch_size <span style="color:#00e0e0">=</span> batch_size <span style="color:#00e0e0">/</span> gradient_accumulation_steps <span style="color:#00e0e0">=</span> <span style="color:#00e0e0">10</span> <span style="color:#00e0e0">/</span> <span style="color:#00e0e0">2</span> <span style="color:#00e0e0">=</span> <span style="color:#00e0e0">5</span> </code></span></span>
这意味着对于每次梯度更新,我们从 2 个微批次中累积数据,每个微批次大小为 5。这减少了内存压力,但每次梯度更新的数据大小仍然是 10 个数据点。
结果:
- 每个时期的训练步数(train_steps)保持为 100,因为数据总量和每个时期的步数都没有改变。
- 梯度更新步骤保持为 100,因为每次梯度更新都会累积来自 2 个微批次的数据。
需要注意的是,使用梯度累积时,每个训练步骤都会处理来自多个微批次的梯度的累积,这可能会稍微增加每个步骤的计算时间。因此,如果内存足够,最好增加批次大小以减少梯度累积的次数。当内存不足时,梯度累积是一种有效的方法。
全局批次大小会显著影响模型的训练效果。通常,较大的全局批次大小可以提供更准确的梯度估计,有助于模型收敛。然而,它也会增加每个设备的内存压力。如果内存资源有限,使用较大的全局批次大小可能不可行。
在这种情况下,可以使用梯度累积。通过在每个设备上使用较小的微批次大小进行训练,我们可以减少内存压力,同时保持较大的全局批次大小以获得准确的梯度估计。这允许在有限的硬件资源上训练大型模型,而不会牺牲全局批次大小。
总之,梯度累积是在内存资源有限的情况下平衡全局批次大小和训练效果的一种权衡策略。
因此,如果我们看一下这两个公式:
![]()
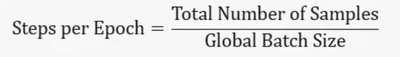
全局batch size越大,在不发生OOM(Out of Memory)且没有充分利用GPU计算能力的前提下,总的训练时间越短。
数据并行和批次大小的关系
本节主要分析一下这个公式:
<span style="color:#333333"><span style="background-color:#ffffff"><span style="background-color:#2b2b2b"><span style="color:#f8f8f2"><code class="language-applescript">global_batch_size <span style="color:#00e0e0">=</span>
gradient_accumulation_steps
<span style="color:#00e0e0">*</span> nnodes (The <span style="color:#abe338">number</span> <span style="color:#00e0e0">of</span> nodes <span style="color:#00e0e0">is</span><span style="color:#fefefe">,</span> <span style="color:#00e0e0">in</span> effect<span style="color:#fefefe">,</span> <span style="color:#00e0e0">the</span> PP)
<span style="color:#00e0e0">*</span> nproc_per_node (The <span style="color:#abe338">number</span> <span style="color:#00e0e0">of</span> cards per node <span style="color:#00e0e0">is</span><span style="color:#fefefe">,</span> <span style="color:#00e0e0">in</span> effect<span style="color:#fefefe">,</span> <span style="color:#00e0e0">the</span> TP)
<span style="color:#00e0e0">*</span> per_device_train_batch_si(micro bs size) </code></span></span></span></span>在分布式深度学习中,数据并行是一种常见的策略。训练数据被分成多个小批量,并分布到不同的计算节点。每个节点都有模型的副本,并在其数据子集上进行训练,从而加快训练过程。
在每个训练步骤结束时,使用 AllReduce 操作同步所有节点的模型权重。AllReduce 会聚合来自所有节点的梯度并广播结果,从而允许每个节点更新其模型参数。
如果在单个设备上进行训练,则不需要 AllReduce,因为所有计算都发生在同一设备上。然而,在分布式训练中,尤其是在数据并行的情况下,AllReduce 或类似操作对于跨设备同步模型参数是必要的。
许多深度学习框架(例如 PyTorch、TensorFlow)使用 NVIDIA 的 NCCL 进行多 GPU 之间的通信。每个 GPU 在其数据子集上进行训练,并在每个步骤结束时使用 NCCL 的 AllReduce 同步模型权重。
虽然 AllReduce 在数据并行中很常用,但根据框架和策略,也可以采用其他 NCCL 操作。
数据并行 (DP) 和微批次大小相互关联。DP 涉及在多台设备上进行训练,每台设备处理一部分数据。微批次大小是每台设备每次迭代处理的样本数。使用 DP,原始批次大小被拆分为跨设备的微批次。如果没有 DP 或模型并行 (MP),微批次大小等于全局批次大小。使用 DP 或 MP,全局批次大小是所有微批次的总和。DP
可应用于单个服务器或跨多个服务器的多个设备。将 DP 设置为 8 表示在 8 台设备上进行训练,这些设备可以位于同一服务器上,也可以分布在多个服务器上。
管道并行 (PP) 是一种不同的策略,其中不同的模型部分在不同的设备上运行。在 PP 中将 DP 设置为 8 表示 8 台设备在每个管道阶段并行处理数据。
总之,DP 和 PP 可同时在单个服务器或跨多个服务器的设备上使用。