做汽车精品的网站,微信推广软件首选帝搜软件,宝塔面板windows建站教程,极简wordpress主题、使用 CUDA 进行图像处理
当下生活在高清摄像头的时代,这种摄像头能捕获高达1920*1920像素的高解析度画幅。想要实施的处理这么多的数据,往往需要几个TFlops地浮点处理性能,这些要求CPU也无法满足通过在代码中使用CUDA,可以利用GP…
for(int i=0;i<image_height;i++){for(int j=0;j<image_width;j++){//Pixel Processing code for pixel located at(i,j)}}
将像素处理映射到CUDA地一批线程上:
int i = blockidx.y * blockDim.y + threadIdx.y
int j = blockidx.x * blockDim.x + threadIdx.x
1. 在GPU上通过CUDA进行直方图统计
首先介绍CPU版本的直方图统计,实现如下:
int h_a[1000]= Random values between 0and15//假设图像取值范围在【0-15】,定义数组并初始化int histogram[16];for(int i=0;i<16;i++){histogram[i]=0;}//统计每个值的个数for(int i=0;i<1000;i++){histogram[h_a[i]]+=1;}
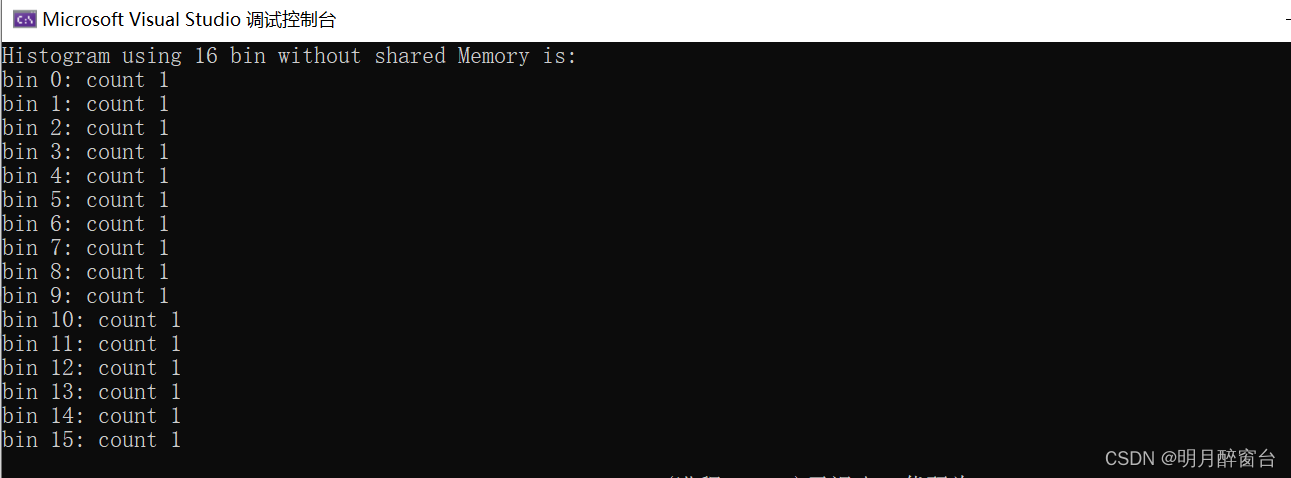
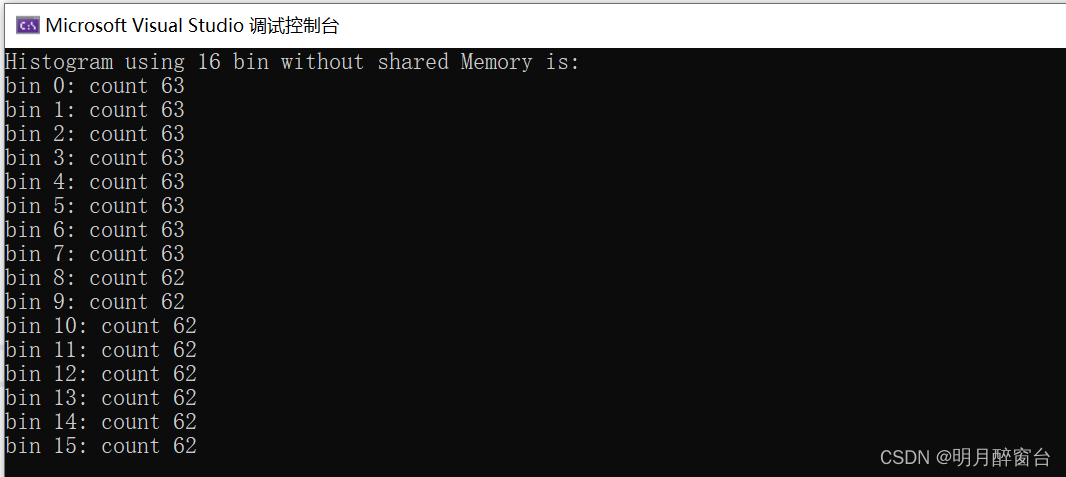
intmain(){//定义设备变量并分配内存int h_a[SIZE];for(int i =0; i < SIZE; i++){h_a[i]= i % NUM_BIN;}int h_b[NUM_BIN];for(int i =0; i < NUM_BIN; i++){h_b[i]=0;}// 声明GPU指针变量int* d_a;int* d_b;// 分配GPU变量内存cudaMalloc((void**)&d_a, SIZE *sizeof(int));cudaMalloc((void**)&d_b, NUM_BIN *sizeof(int));// transfer the arrays to the GPUcudaMemcpy(d_a, h_a, SIZE *sizeof(int), cudaMemcpyHostToDevice);cudaMemcpy(d_b, h_b, NUM_BIN *sizeof(int), cudaMemcpyHostToDevice);// 进行直方图统计//histogram_without_atomic << <((SIZE + NUM_BIN - 1) / NUM_BIN), NUM_BIN >> > (d_b, d_a);histogram_atomic <<<((SIZE+NUM_BIN-1)/ NUM_BIN), NUM_BIN >>>(d_b, d_a);// copy back the sum from GPUcudaMemcpy(h_b, d_b, NUM_BIN *sizeof(int), cudaMemcpyDeviceToHost);printf("Histogram using 16 bin without shared Memory is: \n");for(int i =0; i < NUM_BIN; i++){printf("bin %d: count %d\n", i, h_b[i]);}// free GPU memory allocationcudaFree(d_a);cudaFree(d_b);return0;}
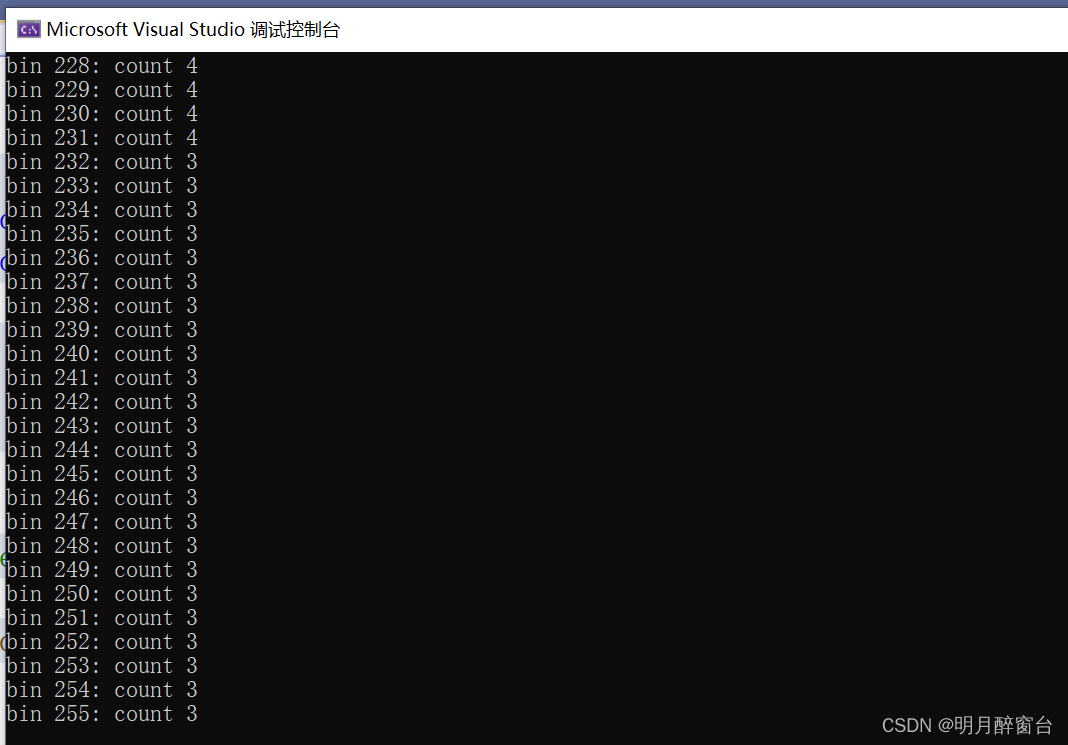
intmain(){// generate the input array on the hostint h_a[SIZE];for(int i =0; i < SIZE; i++){//h_a[i] = bit_reverse(i, log2(SIZE));h_a[i]= i % NUM_BIN;}int h_b[NUM_BIN];for(int i =0; i < NUM_BIN; i++){h_b[i]=0;}// declare GPU memory pointersint* d_a;int* d_b;// allocate GPU memorycudaMalloc((void**)&d_a, SIZE *sizeof(int));cudaMalloc((void**)&d_b, NUM_BIN *sizeof(int));// transfer the arrays to the GPUcudaMemcpy(d_a, h_a, SIZE *sizeof(int), cudaMemcpyHostToDevice);cudaMemcpy(d_b, h_b, NUM_BIN *sizeof(int), cudaMemcpyHostToDevice);// launch the kernelhistogram_shared_memory <<<SIZE /256,256>>>(d_b, d_a);// copy back the result from GPUcudaMemcpy(h_b, d_b, NUM_BIN *sizeof(int), cudaMemcpyDeviceToHost);printf("Histogram using 16 bin is: ");for(int i =0; i < NUM_BIN; i++){printf("bin %d: count %d\n", i, h_b[i]);}// free GPU memory allocationcudaFree(d_a);cudaFree(d_b);return0;}