网站建设的售后服务怎么做好网站方式推广
序言
yolov8发布这么久了,一直没有机会尝试一下,今天用之前自己制作的筷子点数数据集进行训练,并且记录一下使用过程以及一些常见的操作方式,供以后翻阅。
一、环境准备
yolov8的训练相对于之前的yolov5简单了很多,也比其他框架上手要来得快,因为很多东西都封装好了,直接调用或者命令行运行就行,首先需要先把代码git到本地:
git clone https://github.com/ultralytics/ultralytics.git
然后安装ultralytics库,核心代码都封装在这个库里了。
pip install ultralytics
再然后需要安装requirements.txt文件里需要安装的库,python版本要求python>=3.7,torch版本要求pytorch>=1.7.0
pip install -r requirements.txt
接下来我们可以把coco权重下载下来,使用命令行运行检测命令检查环境是否安装成功,将权重下载下来然后新建weights文件夹存放:
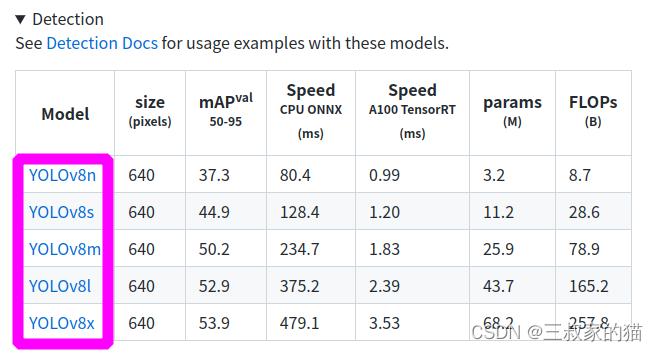
运行检测命令:
yolo predict model=./weights/yolov8n.pt source=./ultralytics/assets/bus.jpg save
其中的一些命令,后面再仔细描述,大部分情况下,这个命令行都是可以运行的,运行结束后,图片保存在runs/detect/predict/bus.jpg中,如下:
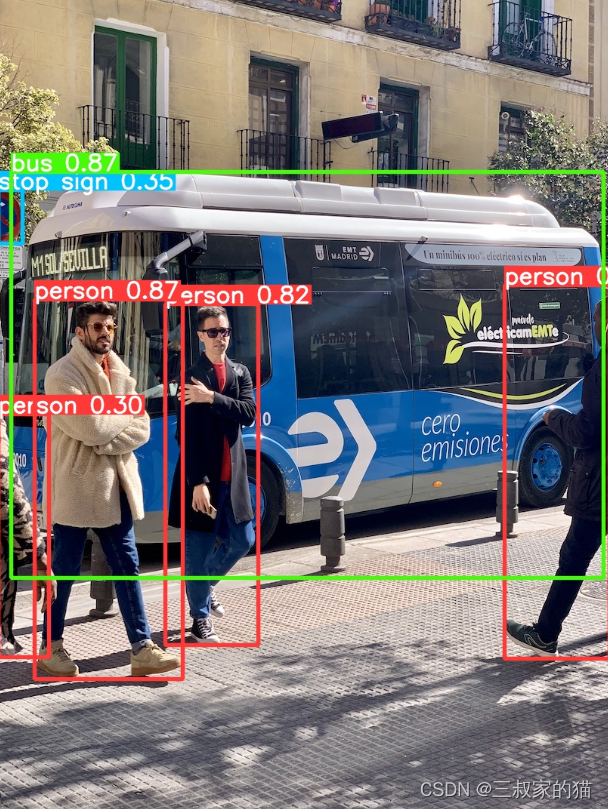
至此,你的环境就准备好了,接下来就可以训练了。
二、数据准备
数据我使用的是之前自己制作的筷子点数数据集,图片如下:
标注示例:

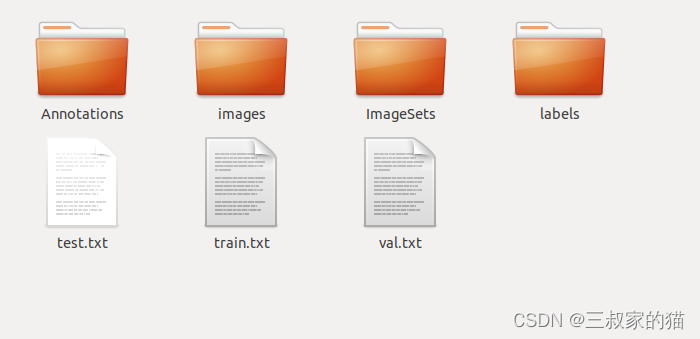
通常我们采用VOC格式的标注数据,所以新建一个任意位置的文件夹(记住该文件夹的绝对路径),文件夹中包含如下内容:
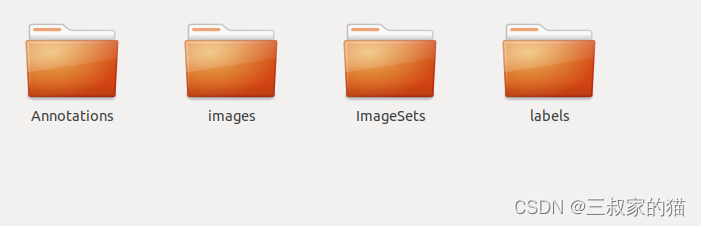
- Annotations xml标注文件
- images 训练的图片
- ImageSets 用于存放划分的train.txt、test.txt、val.txt文件(初始为空)
- labels 用于存放yolo格式的标注txt文件(初始为空)
接下来运行如下文件,路径或者类别等参数根据自己的需要修改,运行该文件有两个作用:
- 划分train、test、val数据集
- 将voc格式标注转换为yolo格式标注
import os
import random
import xml.etree.ElementTree as ET
from os import getcwdsets = ['train', 'test', 'val'] # 划分的train、test、val txt文件名字classes = ['label'] # 数据集类别data_root = "/home/cai/data/chopsticks" # 数据集绝对路径trainval_percent = 0.1 # 测试集验证集比例
train_percent = 0.9 # 训练集比例
xmlfilepath = '{}/Annotations'.format(data_root)
txtsavepath = '{}/images'.format(data_root)
total_xml = os.listdir(xmlfilepath)num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)ftest = open('{}/ImageSets/test.txt'.format(data_root), 'w')
ftrain = open('{}/ImageSets/train.txt'.format(data_root), 'w')
fval = open('{}/ImageSets/val.txt'.format(data_root), 'w')for i in list:name = total_xml[i][:-4] + '\n'if i in trainval:if i in train:ftest.write(name)else:fval.write(name)else:ftrain.write(name)ftrain.close()
fval.close()
ftest.close()# -------------------------------- voc 转yolo代码def convert(size, box):dw = 1. / size[0]dh = 1. / size[1]x = (box[0] + box[1]) / 2.0y = (box[2] + box[3]) / 2.0w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn (x, y, w, h)def convert_annotation(image_id):in_file = open('{}/Annotations/{}.xml'.format(data_root,image_id),encoding='UTF-8')# print(in_file)out_file = open('{}/labels/{}.txt'.format(data_root,image_id), 'w')tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in classes or int(difficult) == 1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')wd = getcwd()
print(wd)
for image_set in sets:if not os.path.exists('{}/labels/'.format(data_root)):os.makedirs('{}/labels/'.format(data_root))image_ids = open('{}/ImageSets/{}.txt'.format(data_root,image_set)).read().strip().split()list_file = open('{}/{}.txt'.format(data_root,image_set), 'w')for image_id in image_ids:# print(image_id)list_file.write('{}/images/{}.jpg\n'.format(data_root,image_id))try:convert_annotation(image_id)except:print(image_id)list_file.close()最后得到如下文件,labels和ImageSets都不再为空:
二、开始训练
v8的训练很简单,配置也超级简单,首先第一步在ultralytics/datasets中创建我们数据集的配置文件,这里我创建了一下chopsticks.yaml,内容如下,其实和之前的v5配置文件一样,该文件中修改自己的路径和类别即可:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# COCO 2017 dataset http://cocodataset.org by Microsoft
# Example usage: python train.py --data coco.yaml
# parent
# ├── yolov5
# └── data
# └── chopsticks ← downloads here# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /home/cai/data/chopsticks # dataset root dir
train: train.txt # train ImageSets (relative to 'path') 118287 ImageSets
val: val.txt # val ImageSets (relative to 'path') 5000 ImageSets
test: test.txt # 20288 of 40670 ImageSets, submit to https://competitions.codalab.org/competitions/20794# Classes
nc: 1 # number of classes
names: ['label'] # class names然后就可以开始训练了,训练过v5的同学可能记得还要修改一下models里的yaml文件,但是V8完全不用的,V8提供了两种简单的训练方式,一是命令行运行,直接在终端运行命令:
yolo task=detect mode=train model=./weights/yolov8n.pt data=./ultralytics/datasets/chopsticks.yaml epochs=100 batch=16 device=0- task 代表任务类型
- mode 代表训练
- model 可以是yaml文件(权重会初始化),也可以是pt文件(初始化时加载预训练模型)
- data 你创建的数据集yaml文件
- epochs 训练轮次
- batch 训练批次
- device 使用0序号GPU训练
二是python文件运行,创建一个trian.py文件,运行python trian.py:
from ultralytics import YOLO# 加载模型
# model = YOLO("yolov8n.yaml") # 从头开始构建新模型
model = YOLO("./weights/yolov8n.pt") # 加载预训练模型(推荐用于训练)# Use the model
results = model.train(data="./ultralytics/datasets/chopsticks.yaml", epochs=100, batch=16,device=0) # 训练模型
train过程比较顺利,训练默认采用早停法,即50个轮次评估中如果模型没有明显的精度提升的话,模型训练会直接停止,可以通过修改patience=50参数控制早停的观察轮次。
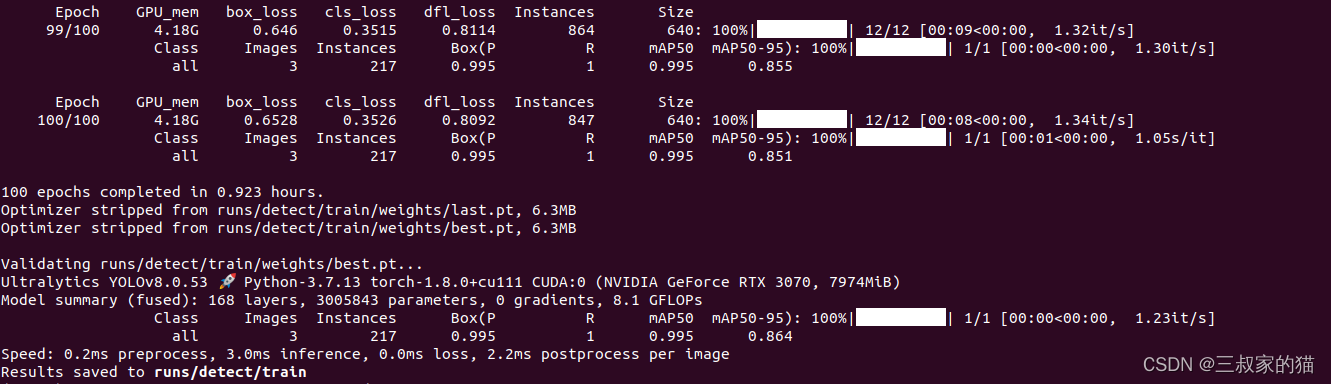
训练结束后模型和训练过程保存在runs文件夹中,可以看到精度其实还是不错的,接下来用图片测试一下。
同样的提供两种简单的推理方式,一是命令行,运行:
yolo task=detect mode=predict model=./runs/detect/train/weights/best.pt source=./40.jpg save=True
或者创建一个demo.py文件,运行python demo.py:
from ultralytics import YOLO# Load a model
# model = YOLO("yolov8n.yaml") # build a new model from scratch
model = YOLO("./runs/detect/train/weights/best.pt") # load a pretrained model (recommended for training)# Use the model
results = model("./40.jpg ") # predict on an image

可以看到效果还是很不错的。
三、导出onnx
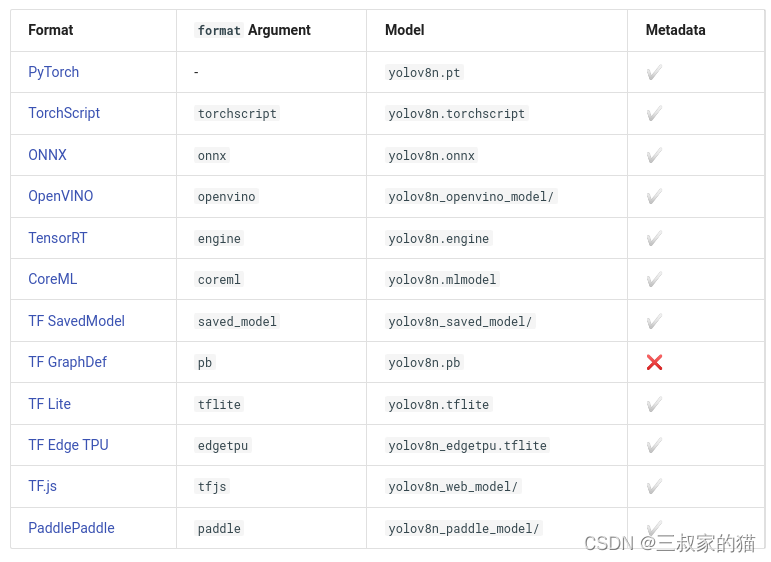
模型训练完后,需要部署,V8也提供了直接了如下格式模型的导出(居然也支持paddlepaddle,惊讶),导出后可以摆脱训练框架进行部署:
命令行导出命令如下:
yolo export model=./runs/detect/train/weights/best.pt format=onnx # export custom trained model
python文件导出:
from ultralytics import YOLO# Load a model
model = YOLO('./runs/detect/train/weights/best.pt') # load a custom trained# Export the model
model.export(format='onnx')
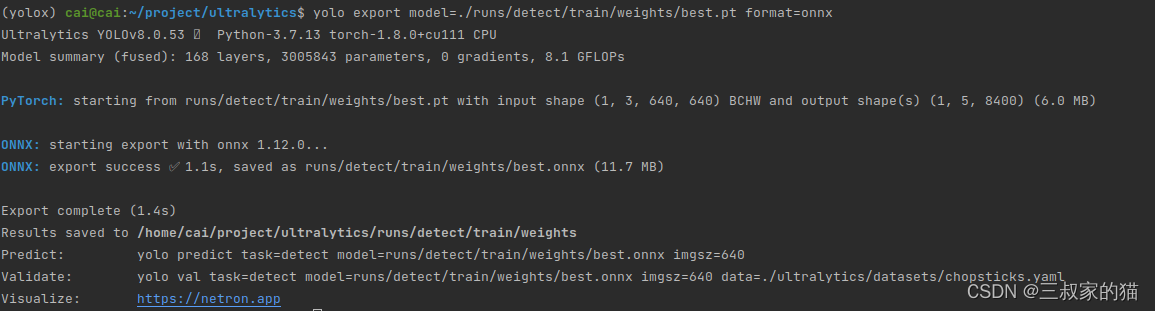
onnx文件保存在pt文件同级目录下,超级简单丝滑有木有!!
相关数据集和代码提供百度云,需要的朋友可自行下载。
链接:https://pan.baidu.com/s/1k-f61kiOiMA8yf-tqgV4GA?pwd=28hw
提取码:28hw