做宣传类网站需要什么资质如何用wordpress做产品页
目录
引言
具体步骤
1.设置请求选项
2.发送请求并获取响应
3.设置正则表达式
4.执行正则表达式匹配
matlab完整代码
python代码示例
引言
在当今这个信息爆炸的时代,数据已成为推动社会进步和企业发展的核心动力之一。随着互联网的普及和技术的飞速发展,网络上的数据资源变得前所未有的丰富和多样。然而,这些数据大多以非结构化的形式存在,如网页、文档、图片、视频等,直接利用这些原始数据不仅效率低下,而且难以发挥其真正的价值。因此,爬虫技术应运而生,成为了数据获取与处理的重要工具。
爬虫,又称网络爬虫或网页蜘蛛,是一种按照一定规则自动从互联网上抓取信息的程序或脚本。它们模拟人类浏览器的行为,访问目标网站,并解析网页内容,提取出我们感兴趣的数据。这些数据可以是文本、图片、视频等多种形式,涵盖了新闻、商品信息、学术论文、社交媒体内容等众多领域。
学习爬虫技术,不仅可以帮助我们高效地获取所需的数据资源,还能让我们更深入地理解互联网的工作原理和数据的流动方式。通过爬虫,我们可以实现数据的自动化收集、整理和分析,为后续的数据挖掘、机器学习、大数据分析等提供有力的支持。
然而,值得注意的是,爬虫技术的使用应当遵守法律法规和网站的robots协议,尊重网站的版权和数据隐私。在爬虫开发过程中,我们需要遵循合法、合规的原则,确保数据的合法来源和正当使用。
总之,爬虫技术作为数据获取与处理的重要手段,在当今社会具有广泛的应用前景和重要的实践价值。学习并掌握爬虫技术,将为我们打开一扇通往数据世界的大门,让我们在数据驱动的时代中占据有利位置。
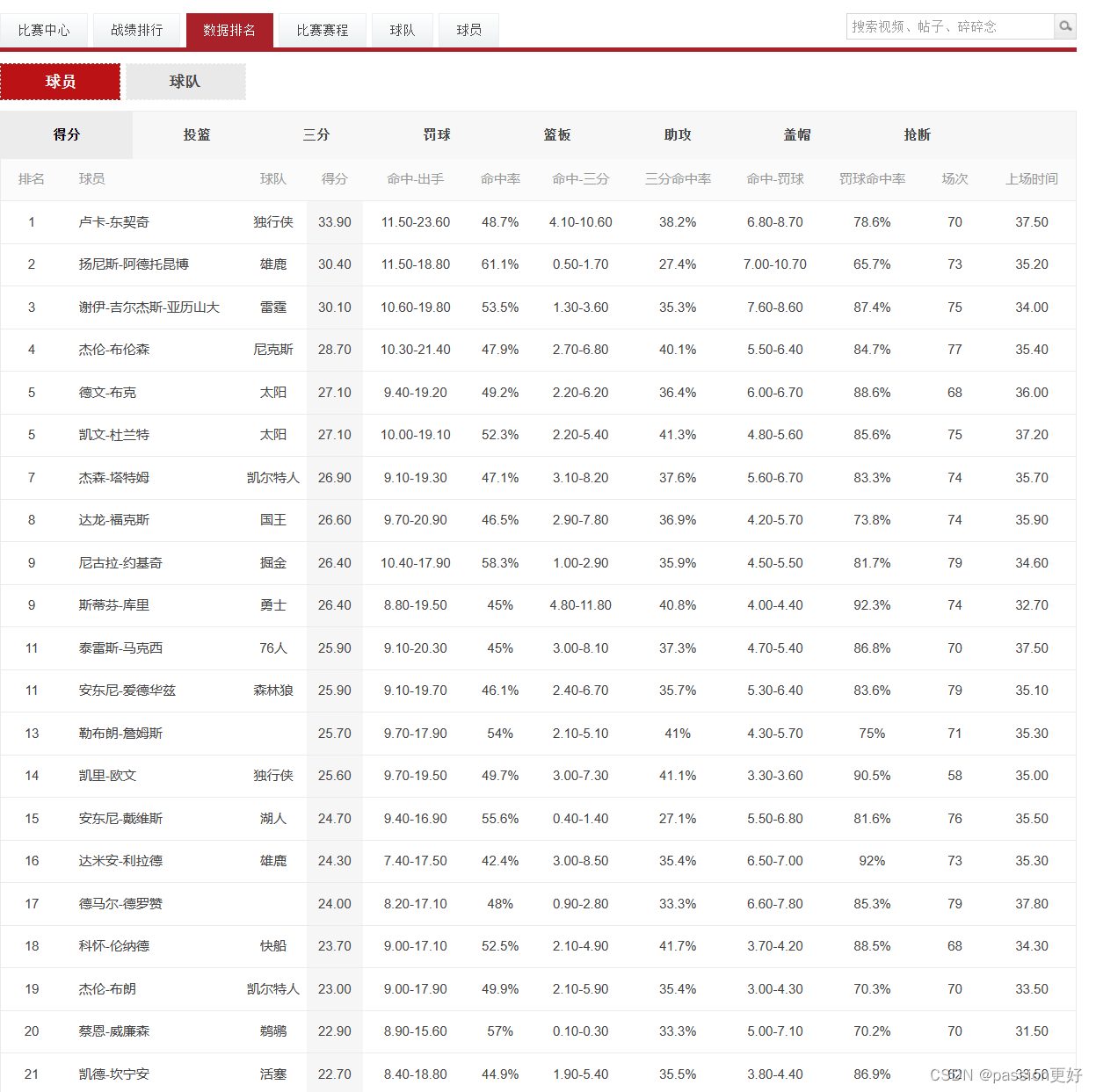
爬取网页
具体步骤
1.设置请求选项
url = 'https://nba.hupu.com/stats/players';
opts = weboptions('HeaderFields',{'User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.54'});
weboptions 函数用于设置网络请求选项,这里设置了 User-Agent 头部字段,模拟了一个常见的浏览器用户代理,以避免网站反爬虫机制的阻拦。
2.发送请求并获取响应
resp = webread(url, opts);
3.设置正则表达式
使用正则表达式来选中想要爬取的内容,这里以爬取球员和得分为例
点击源代码页面左上角:在页面中选择一个元素以进行检查,这里选中人名卢卡-东契奇,对照源代码确定正则表达式
name_pattern = '<td\s+width="\d+"\s+class="left">\s*<a\s+href="[^"]*">([^<]+)</a>\s*</td>'; 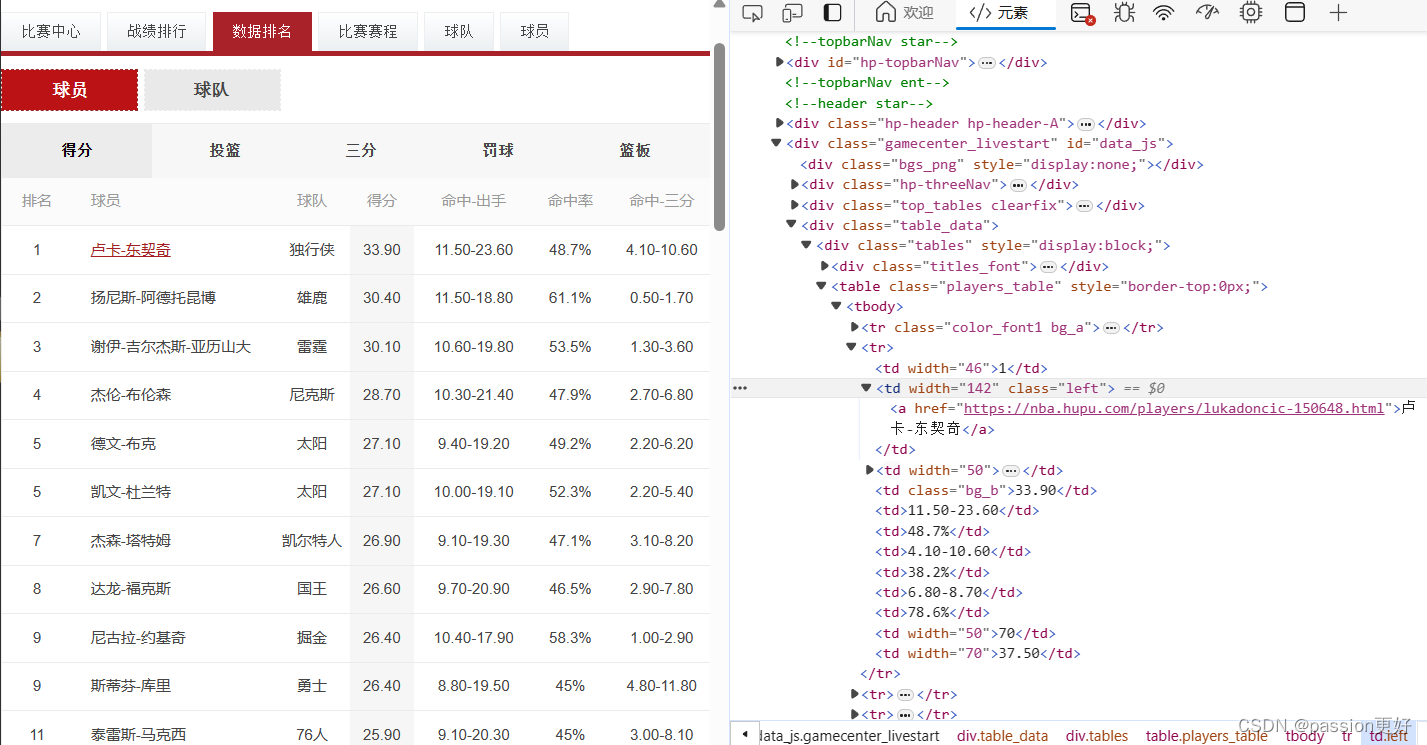
score_pattern = '<td\s+class="bg_b">\s*([^<]+)\s*</td>';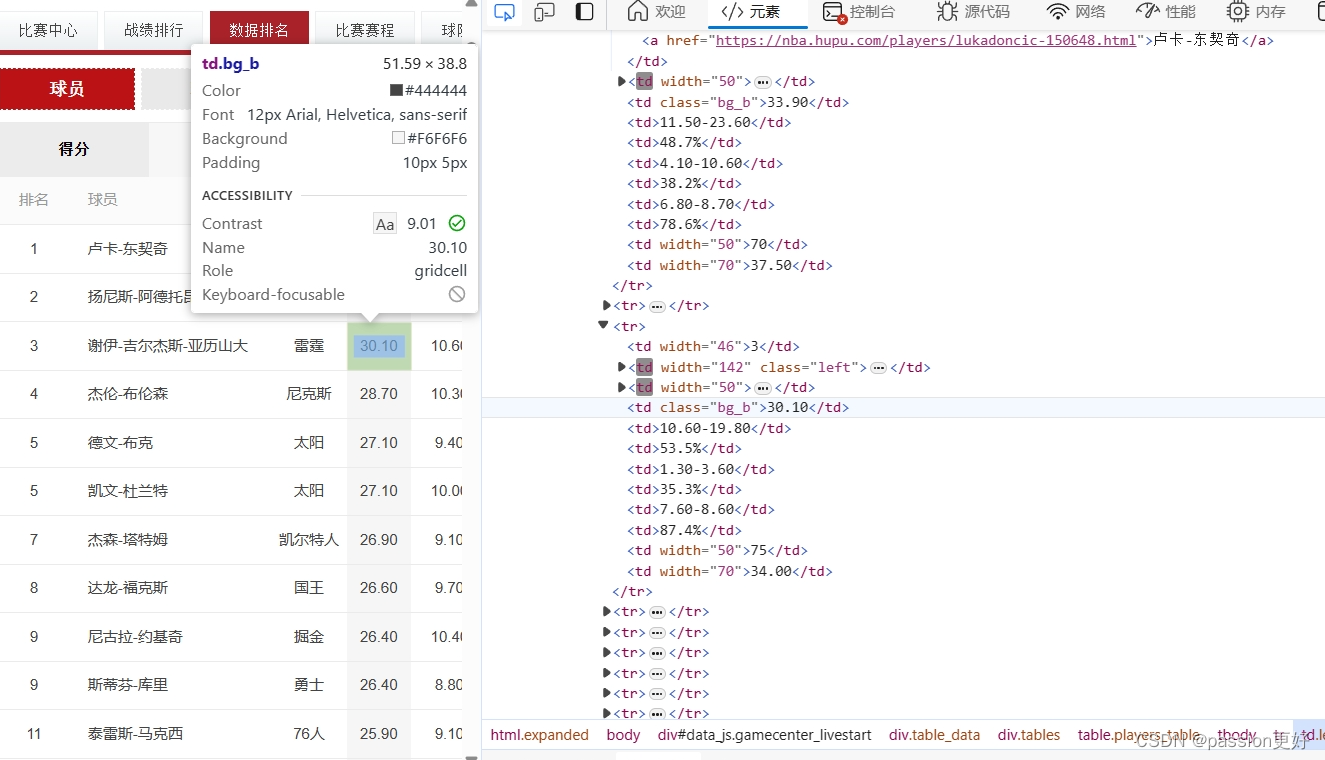
name_pattern 匹配包含球员名字的 <td> 元素,并使用捕获组来提取名字。
score_pattern 匹配包含球员得分的 <td> 元素,并使用捕获组来提取得分。
4.执行正则表达式匹配
name_matches = regexp(resp, name_pattern, 'tokens');
score_matches = regexp(resp, score_pattern, 'tokens');matlab完整代码
url = 'https://nba.hupu.com/stats/players';
opts = weboptions('HeaderFields',{'User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.54'});% 发送请求并获取响应
resp = webread(url, opts);name_pattern = '<td\s+width="\d+"\s+class="left">\s*<a\s+href="[^"]*">([^<]+)</a>\s*</td>';
score_pattern = '<td\s+class="bg_b">\s*([^<]+)\s*</td>';
%
% 提取球员名字
name_matches = regexp(resp, name_pattern, 'tokens');% 提取得分
score_matches = regexp(resp, score_pattern, 'tokens');% 输出匹配结果
disp('球员及得分:');
for i = 1:length(name_matches)player_name = name_matches{i}{1};player_score = score_matches{i}{1};disp(['球员:', player_name, ' 得分:', player_score]);
endpython代码示例
通过模拟浏览器发送HTTP GET请求到NBA虎扑网站,使用lxml库的etree解析返回的HTML内容
# 并利用XPath表达式提取球员的排名、姓名、球队和得分信息。
import requests
from lxml import etree # 目标URL
url = 'https://nba.hupu.com/stats/players'
# 请求头,模拟浏览器访问
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.54'
} # 发送HTTP GET请求
resp = requests.get(url, headers=headers) # 检查请求是否成功
if resp.status_code == 200: # 使用lxml的etree解析HTML内容 e = etree.HTML(resp.text) # 提取球员的排名、姓名、球队和得分 nos = e.xpath('//table[@class="players_table"]/tr/td[1]/text()') names = e.xpath('//table[@class="players_table"]/tr/td[2]/a/text()') teams = e.xpath('//table[@class="players_table"]/tr/td[3]/a/text()') scores = e.xpath('//table[@class="players_table"]/tr/td[4]/text()') # 遍历并打印结果 for no, name, team, score in zip(nos, names, teams, scores): # 处理可能存在的空值或特殊字符 no = no.strip() if no else '未知' name = name.strip() if name else '未知' team = team.strip() if team else '未知' score = score.strip() if score else '未知' print(f'排名:{no} 姓名:{name} 球队:{team} 得分:{score}')
else: print(f"请求失败,状态码:{resp.status_code}")