工业设计东莞网站建设附近建网站公司
大家好,我是微学AI,今天给大家介绍一下自然语言处理实战项目8- BERT模型的搭建,训练BERT实现实体抽取识别的任务。BERT模型是一种用于自然语言处理的深度学习模型,它可以通过训练来理解单词之间的上下文关系,从而为下游任务提供高质量的语言表示。它的结构是由多个Transformer编码器组成的,而Transformer编码器是由多个自注意力机制组成的。在训练中,模型通过预测遮盖的单词和判断两个句子之间的关系来提高语言表示的准确性。在实体识别任务中,BERT模型可以作为特征提取器使用,将每个单词的上下文相关的向量表示输入到分类器中完成实体识别。
一、BERT模型的框架
BERT的基础结构是多层的Transformer编码器架构。Transformer是一种自注意力机制,允许模型在不同的词语之间捕获重要的关系。具体而言,BERT使用自注意力头为文本序列中的每个单词生成一个向量表示,同时捕捉了整个句子的上下文信息。这些向量表示可以从底层到更高层进行组合,从而允许模型学习更加复杂的语义结构。
BERT模型有两种主要的预训练模型:
1.BERT-Base:包含12层(Encoder layers)、12个自注意力头(Attention heads)和768个隐藏层大小(Hidden size),总共有约 110M 个参数。
2.BERT-Large:包含 24层(Encoder layers)、16个自注意力头(Attention heads)和1024个隐藏层大小(Hidden size),总共约340M个参数。
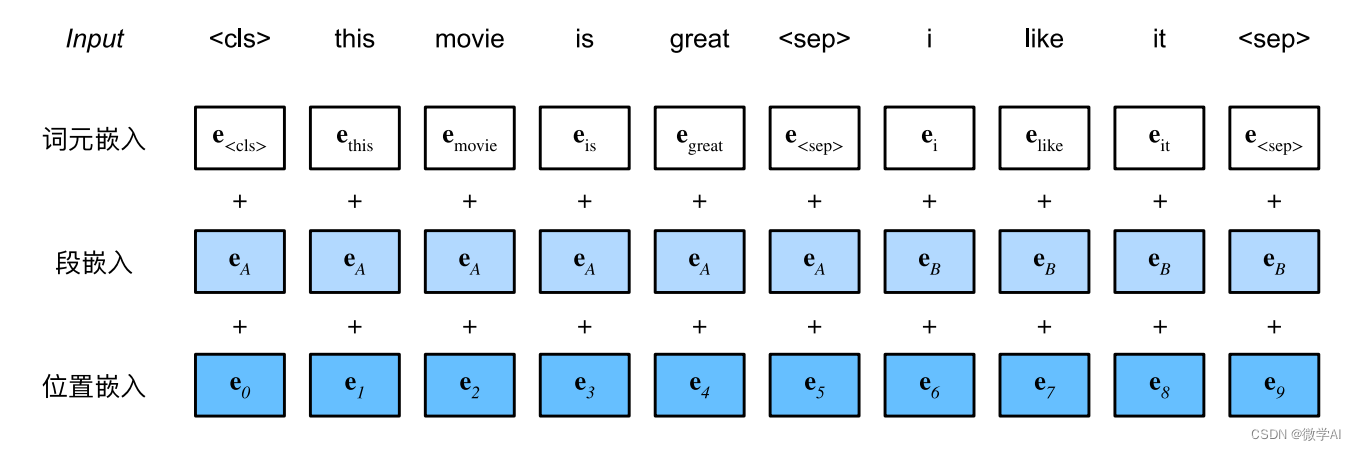 二、BERT的预训练
二、BERT的预训练
BERT的预训练主要分为两个阶段:预训练和微调。
2.1 预训练:
在预训练阶段,BERT的创新之举是利用大量无标注文本进行双向训练。在这个阶段,BERT引入了两个预训练任务:掩码语言建模(MLM) 和 下一句预测(NSP)。
掩码语言建模(MLM):在训练过程中,输入句子中的一部分单词被随机替换为一个特殊的掩码符号(MASK)。模型的目标是根据句子其他部分的上下文信息,预测被掩码的单词。这种训练方式使模型能够学习双向的语义信息。
下一句预测(NSP):这个任务旨在让模型学习理解句子之间的关系。给定一对句子,模型需要预测第二个句子是否紧跟在第一个句子之后。这个任务有助于BERT更好地应对需要理解多个句子关系的任务,如问答和自然语言推理等。
2.2 微调:
在预训练阶段完成后,BERT模型已经学会了丰富的语义表示。然后,在实际的NLP任务中,我们需要对预训练的BERT进行微调。微调阶段只需较少的标注数据就能使模型针对具体任务进行优化。
在微调过程中,通常在BERT模型的顶部添加一个任务相关的神经网络层,如全连接层、卷积层等。然后连同BERT整个模型进行端到端的微调训练。在训练时,利用带标签的数据计算损失,利用梯度下降进行参数更新。经过微调后,BERT能够根据特定任务生成更有针对性的结果。
三、训练BERT实现实体抽取识别的任务
以下是一个使用PyTorch和Hugging Face Transformers库的BERT模型进行中文命名实体识别任务的完整代码,第三方库载入,数据样例导入。
import torch
from torch.utils.data import Dataset, DataLoader
from transformers import BertTokenizer, BertForTokenClassification, AdamW
from sklearn.model_selection import train_test_split
from tqdm import tqdmdef load_data_from_txt(file_path):with open(file_path, "r", encoding="utf-8") as f:lines = f.readlines()data = []for line in lines:line = line.strip()if not line:continuetoken, label = line.split()data.append((token, label))return datafile_path = 'ner_data.txt'
data = load_data_from_txt(file_path)
print(data)ner_data.txt文件数据样例:
李 B-PER
华 I-PER
山 I-PER
是 O
一 O
个 O
优 O
秀 O
的 O
程 O
序 O
员 O
。 O
阿 B-ORG
里 I-ORG
巴 I-ORG
巴 I-ORG
是 O
一 O
家 O
著 O
名 O
的 O
中 B-LOC
国 I-LOC
公 O
司 O
。 O
陈 B-PER
明 I-PER
在 O
北 B-LOC
京 I-LOC
上 O
了 O
一 O
所 O
大 O
学 O
。 O模型加载与训练:
# 预处理
tokenizer = BertTokenizer.from_pretrained("bert-base-chinese")
label_map = {"B-PER": 0, "I-PER": 1, "B-ORG": 2, "I-ORG": 3, "B-EDU":4,"I-EDU":5, "B-LOC":6,"I-LOC":7,"O": 8}
inverse_label_map = {v: k for k, v in label_map.items()}class NERDataset(Dataset):def __init__(self, data, tokenizer, label_map):self.data = dataself.tokenizer = tokenizerself.label_map = label_mapdef __len__(self):return len(self.data)def __getitem__(self, idx):token, label = self.data[idx]input_ids = tokenizer.encode(token, add_special_tokens=False)label_id = self.label_map[label]return torch.tensor(input_ids, dtype=torch.long), torch.tensor(label_id, dtype=torch.long)dataset = NERDataset(data, tokenizer, label_map)
train_data, val_data = train_test_split(dataset, test_size=0.2, random_state=42)
train_loader = DataLoader(train_data, batch_size=1, shuffle=True)
val_loader = DataLoader(val_data, batch_size=1, shuffle=False)# 模型
model = BertForTokenClassification.from_pretrained("bert-base-chinese", num_labels=len(label_map))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)# 优化器
optimizer = AdamW(model.parameters(), lr=5e-5)# 训练
num_epochs = 8
for epoch in range(num_epochs):model.train()total_loss = 0total_correct = 0total_count = 0for batch in tqdm(train_loader):input_ids, labels = batchinput_ids = input_ids.to(device)labels = labels.to(device)optimizer.zero_grad()outputs = model(input_ids, labels=labels)loss = outputs.lossloss.backward()optimizer.step()total_loss += loss.item()total_correct += (outputs.logits.argmax(-1) == labels).sum().item()total_count += labels.size(0)avg_loss = total_loss / total_countaccuracy = total_correct / total_countprint(f"Epoch {epoch + 1}/{num_epochs}, Loss: {avg_loss:.4f}, Accuracy: {accuracy:.4f}")运行结果:
100%|██████████| 97/97 [00:39<00:00, 2.47it/s]0%| | 0/97 [00:00<?, ?it/s]Epoch 1/10, Loss: 1.4691, Accuracy: 0.5979
100%|██████████| 97/97 [00:40<00:00, 2.42it/s]
Epoch 2/10, Loss: 1.3695, Accuracy: 0.6598
100%|██████████| 97/97 [00:39<00:00, 2.48it/s]
Epoch 3/10, Loss: 1.2924, Accuracy: 0.5979
100%|██████████| 97/97 [00:39<00:00, 2.48it/s]0%| | 0/97 [00:00<?, ?it/s]Epoch 4/10, Loss: 1.3100, Accuracy: 0.6701
100%|██████████| 97/97 [00:37<00:00, 2.59it/s]
Epoch 5/10, Loss: 1.2179, Accuracy: 0.6598
100%|██████████| 97/97 [00:40<00:00, 2.39it/s]0%| | 0/97 [00:00<?, ?it/s]Epoch 6/10, Loss: 0.9726, Accuracy: 0.6495
100%|██████████| 97/97 [00:39<00:00, 2.46it/s]0%| | 0/97 [00:00<?, ?it/s]Epoch 7/10, Loss: 1.0536, Accuracy: 0.6186
100%|██████████| 97/97 [00:40<00:00, 2.42it/s]
Epoch 8/10, Loss: 0.9458, Accuracy: 0.6907