昭通昭阳区城乡建设管理局网站上海关键词优化按天计费
机器学习:学习KMeans算法,了解模型创建、使用模型及模型评价
作者:AOAIYI
作者简介:Python领域新星作者、多项比赛获奖者:AOAIYI首页
😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒+关注哦!👍👍👍
📜📜📜如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!💪
| 专栏案例:机器学习 |
|---|
| 机器学习:基于逻辑回归对某银行客户违约预测分析 |
| 机器学习:学习k-近邻(KNN)模型建立、使用和评价 |
| 机器学习:基于支持向量机(SVM)进行人脸识别预测 |
| 决策树算法分析天气、周末和促销活动对销量的影响 |
| 机器学习:线性回归分析女性身高与体重之间的关系 |
| 机器学习:基于主成分分析(PCA)对数据降维 |
| 机器学习:基于朴素贝叶斯对花瓣花萼的宽度和长度分类预测 |
文章目录
- 机器学习:学习KMeans算法,了解模型创建、使用模型及模型评价
- 一、实验目的
- 二、实验原理
- 三、实验环境
- 四、实验内容
- 五、实验步骤
- 1.数据读取
- 2.数据理解
- 3.数据规整化处理
- 4.数据建模
- 5.查看模型
- 6.预测模型
- 7.结果输出
- 总结
一、实验目的
学习sklearn模块中的KMeans算法
二、实验原理
K-means算法是将样本聚类成k个簇(cluster),具体算法描述如下:
1、 随机选取k个聚类质心点(cluster centroids)为

2、 重复下面过程直到收敛 {
对于每一个样例i,计算其应该属于的类

对于每一个类j,重新计算该类的质心

K是我们事先给定的聚类数,c(i)代表样例i与k个类中距离最近的那个类,c(i)的值是1到k中的一个。质心uj代表我们对属于同一个类的样本中心点的猜测,拿星团模型来解释就是要将所有的星星聚成k个星团,首先随机选取k个宇宙中的点(或者k个星星)作为k个星团的质心,然后第一步对于每一个星星计算其到k个质心中每一个的距离,然后选取距离最近的那个星团作为c(i),这样经过第一步每一个星星都有了所属的星团;第二步对于每一个星团,重新计算它的质心uj(对里面所有的星星坐标求平均)。重复迭代第一步和第二步直到质心不变或者变化很小。求点群中心的算法:
一般来说,求点群中心点的算法你可以使用各个点的X/Y坐标的平均值。不过,我这里想告诉大家另三个求中心点的的公式:
1)Minkowski Distance公式——λ可以随意取值,可以是负数,也可以是正数,或是无穷大。

2)Euclidean Distance公式——也就是第一个公式λ=2的情况

3)CityBlock Distance公式——也就是第一个公式λ=1的情况

三、实验环境
Python 3.9
Anaconda
Jupyter Notebook
四、实验内容
学习KMeans算法,了解模型创建、使用模型及模型评价等操作
五、实验步骤
1.数据读取
1.查看数据内容


2.使用pandas的read_table方法读取protein.txt文件,以\t分隔并传入protein
import pandas as pd
protein = pd.read_table("D:\CSDN\data\kmeans\protein.txt", sep='\t')
protein.head()

2.数据理解
1.查看protein的描述性统计
print(protein.describe())

2.查看数据基本信息
protein.info()

3.查看protein的列名
print(protein.columns)

4.用.shape方法可以读取矩阵的形状
print(protein.shape)

3.数据规整化处理
1.导入sklearn模块中的preprocessing函数
from sklearn import preprocessing
#删除protein中的Country列,axis=1表示横向执行
sprotein = protein.drop(['Country'], axis=1)
print(sprotein) 
使用preprocessing函数中的.scale()方法进行标准化,一般会把train和test集放在一起做标准化,
或者在train集上做标准化后,用同样的标准化器去标准化test集此时可以用scaler
sprotein_scaled = preprocessing.scale(sprotein)
print(sprotein_scaled)

4.数据建模
1.导入sklearn模块中的KMeans方法
from sklearn.cluster import KMeans
#创建一个1~20的列表并赋值给NumberOfClusters
NumberOfClusters = range(1, 20)
#n_clusters参数:分成的簇数(要生成的质心数)
kmeans = [KMeans(n_clusters=i) for i in NumberOfClusters]
score = [kmeans[i].fit(sprotein_scaled).score(sprotein_scaled) for i in range(len(kmeans))]
score

2.导入Matplotlib模块
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(NumberOfClusters,score)
plt.xlabel('Number of Clusters')
plt.ylabel('Score')
plt.title('Elbow Curve')
plt.show()

3.使用KMeans算法生成实例myKmeans
myKmeans = KMeans(algorithm="auto",n_clusters=5,n_init=10,max_iter=200)
参数解释:
-
algorithm:有“auto”, “full” or “elkan”三种选择,默认的”auto”则会根据数据值是否是稀疏的,来决定如何选择”full”和“elkan”,一般数据是稠密的,那么就是 “elkan”,否则就是”full”
-
n_clusters=5:即k值,一般需要多试一些值以获得较好的聚类效果
-
n_init:用不同的初始化质心运行算法的次数
-
max_iter: 最大的迭代次数
4.利用.fit()方法对sprotein_scaled进行模型拟合
myKmeans.fit(sprotein_scaled)
5.查看模型
1.打印输出myKmeans模型
print(myKmeans)

6.预测模型
1.使用.predict方法,用训练好的模型进行预测
y_kmeans = myKmeans.predict(sprotein)
print(y_kmeans)

7.结果输出
1.编写print_kmcluster函数并输出结果
def print_kmcluster(k): '''用于聚类结果的输出 k:为聚类中心个数 ''' for i in range(k): print('聚类', i) ls = [] for index, value in enumerate(y_kmeans): if i == value: ls.append(index) print(protein.loc[ls, ['Country', 'RedMeat', 'Fish', 'Fr&Veg']]) print_kmcluster(5)
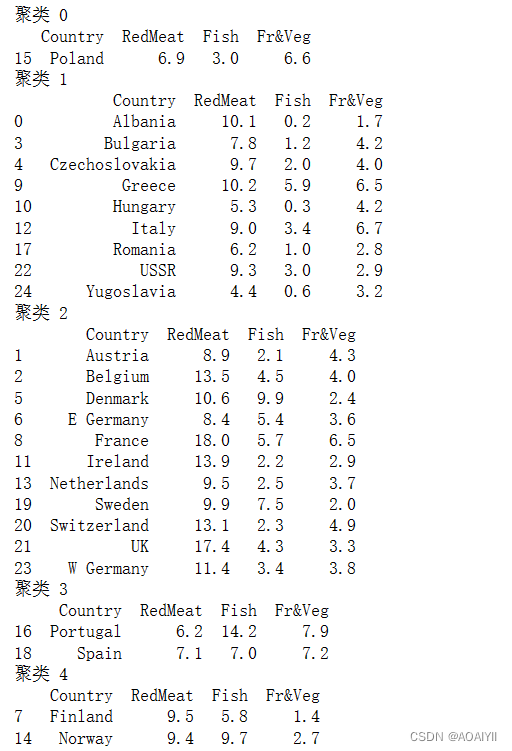
总结
K-Means算法是一种典型的基于划分的聚类算法,也是一种无监督学习算法。K-Means算法的思想很简单,对给定的样本集,用欧氏距离作为衡量数据对象间相似度的指标,相似度与数据对象间的距离成反比,相似度越大,距离越小。
走在人生的跑道上,不管遇到任何的困难,我们都应该坚持下去,永不退缩,只有这样我们才能够成功。