仙居建设规划局网站b站推广入口2023
原文链接
字节前几天2024年9年19日公开发布的论文《HLLM:通过分层大型语言模型增强基于物品和用户模型的序列推荐效果》。

文字、图片、音频、视频这四大类信息载体,在生产端都已被AI生成赋能助力,再往前一步,一定需要一个更强势的、更有效率的推荐分发机制。因为只有分发到位,才会激发更多的供给生产…
传统推荐
传统的推荐项目是将user与item转换为ID并创建对应的embedding table,在得到向量后,可以基于item进行推荐和基于user进行推荐,目前常用的还有单塔和双塔模型等。
在提取制作item embedding table方面,可以提取物品中文描述的关键词,然后再把关键词转换为词向量来代表物品,随着深度学习的发展,提取关键词再转为向量的过程逐渐被LSTM或Bert等具备语言能力的序列模型代替,现在更有M3E等专门把自然语言转换成稠密向量的模型。而LLMs具备强大的语义理解能力,所以大厂自然把转向量的思路往大模型的方向靠近。
使用大模型进行推荐
大模型分为 Item LLM 和 User LLM,两者参数并不共享,直接基于已经预训练好的LLMs进行文本到向量的转换。
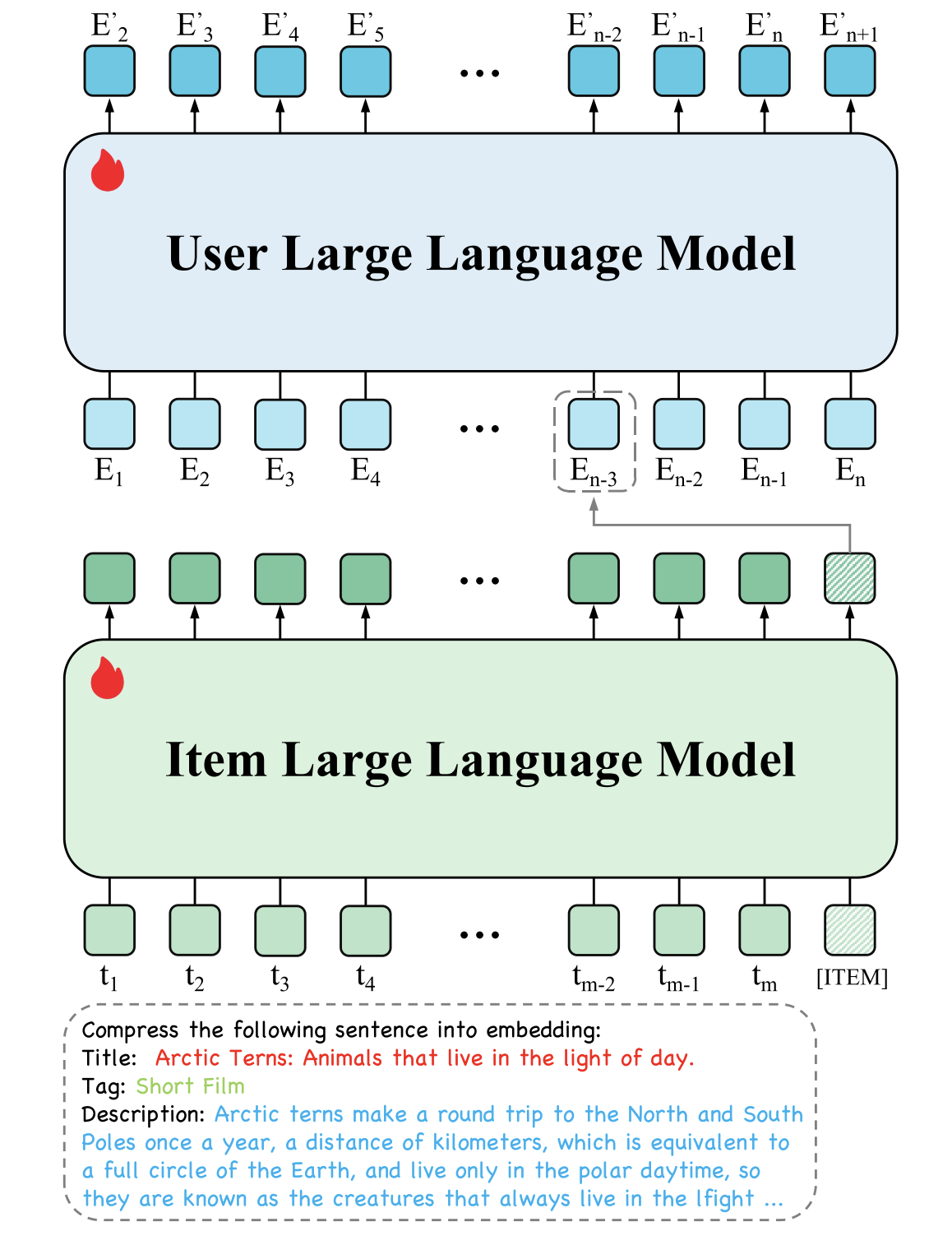
Item LLM:使用 item 的描述作为输入,例如:Title、Tag、Description,最后再加上一个特殊 token [ITEM],特殊token对应输出代表该 item 的 embedding
User LLM:输入是用户历史行为(浏览、加购、成交)的交互序列,输入序列中每个embedding就来自于 Item LLM 的输出。由于输入并非文本token,所以对于User LLM会去除预训练模型的 word embedding
那么大模型的优化是通过next token prediction进行优化的,但是现在的输入不再是word embedding,该怎么做呢?其实很简单,我们不看大模型的输入与输出,只利用大模型的主体框架,把它看成一个普通的序列生成模型或者判别模型就好。
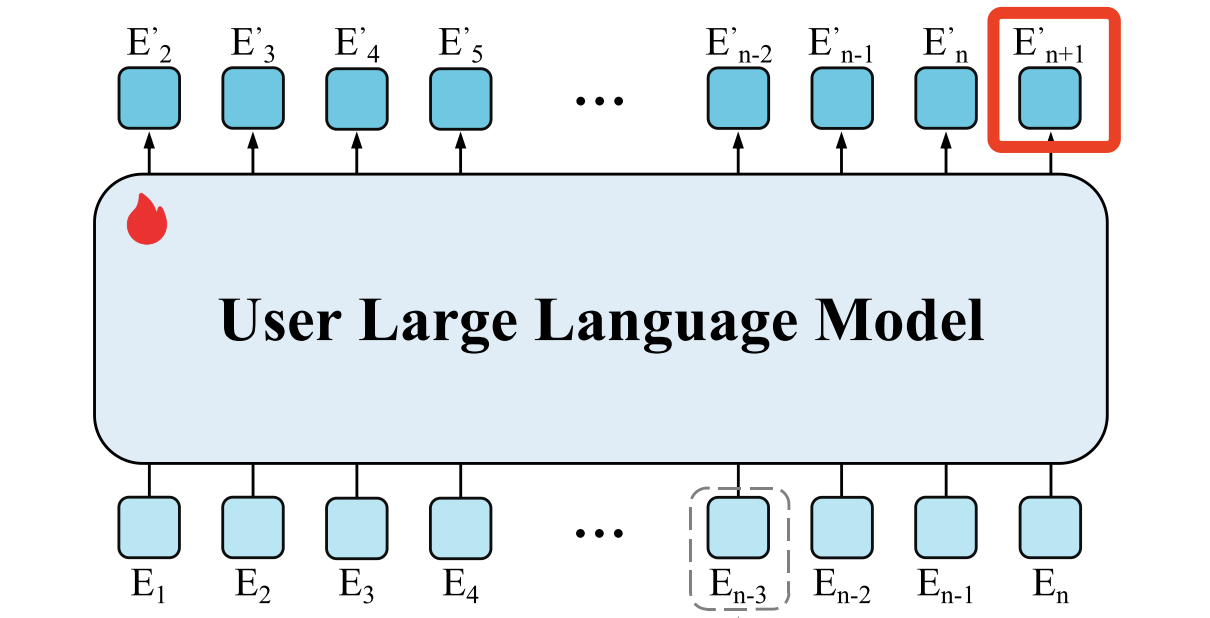
序列生成模型:我们在app上实际购物浏览是,行为是有顺序的,对于某个物品 E i E_i Ei模型输出的 E i + 1 ′ E_{i+1}^{'} Ei+1′是正样本,在序列的尾端就是预测你下一步要浏览的物品,我可以随机抽取的其他物品为负样本,将对比学习的InfoNCE作为预测next token的损失函数。
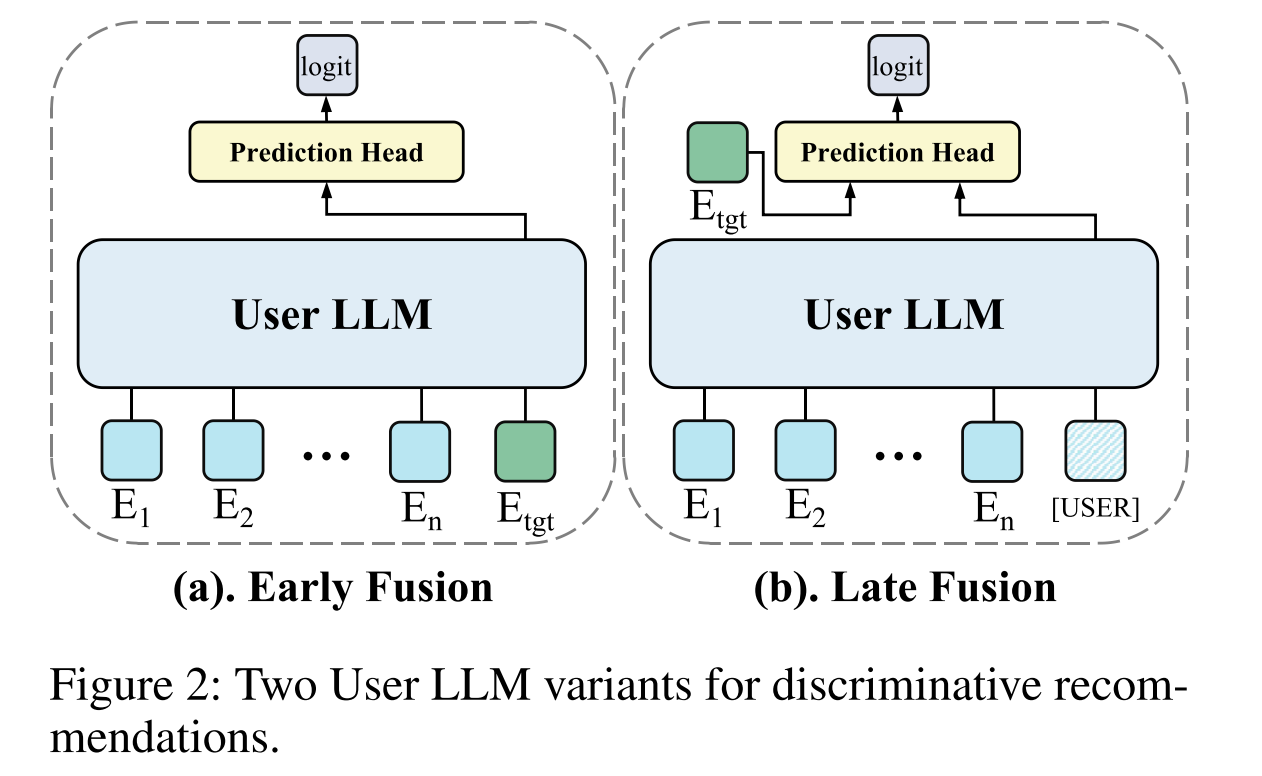
判别模型:其实就是目前最常用的单塔与双塔模型,目标是二分类。单塔模型将用户历史浏览的物品embedding( E 1 − E n E_1-E_n E1−En,由Item LLM生成)依次输入,然后拼上一个待预测物品,让模型预测用户是否会购买这个物品。双塔模型是使用用户历史浏览物品生成一个USER用户向量,然后再使用这个用户向量与目标物品向量进行打分预测。
在实际应用中,使用双塔模型更多一些,因为会有一个稳定的中间量即用户向量可以储存,计算效率更高。单塔模型可以动态抽取实时浏览数据进行预测,效果更好但是计算效率低。
实验结论
字节提出的 Hierarchical Large Language Model(HLLM)网络架构,通过训练Item LLM与User LLM,通过实验表明在公开数据集上显著超越 ID-based方法,并呈现了Scaling Law特性。在抖音落地,A/B实验显示在重要指标上增长0.705%。其下是一些模型指标:
- 采用 [ITEM] token 提取 embedding比mean pooling方法好
- Item LLM 采用Tag + Title + Description = length 256比其短的效果更好
- 输入用户序列长度采用length=50相比其他短的会更好
- 工业场景下Item LLM和User LLM采用7B更好比其小的更好,User LLM输入长度采用1k比其短的更好
