真人男女直接做的视频网站新闻软文发布平台
这个本来是想做视频的,所以是以讲稿的形式写的。最后没做视频,但是觉得这篇文还是值得记录一下。真的要多记录,不然一些不常用的东西即使做过几个月又有点陌生了。
文章目录
- 爬虫 SCRAPY
- xpath
- 后端 DJANGO
- 前端 REACT
Hello大家好这里是小鱼,最近我做了一个前后端分离的实时数据大屏,因为是自己做全栈开发,所以从零开始学了不少新的知识,想在这里分享或者说记录一下,这个教程会尽量短,但是从数据获取,到后端项目和前端项目,包括项目部署到云服务器都会讲到,那我们开始吧。
爬虫 SCRAPY
首先我们要考虑数据大屏的数据从哪来,数据大屏的重要优势,一个是多端显示(比如做好了之后无论在手机/电脑还是电视这种更大的显示器都可以看),再一个就是实时性,一般数据大屏不同于那种一次性生成的数据可视化图,数据大屏的数据是实时更新的。
给公司做项目的话可能会有现成的实时数据给到你,那我们做自己项目就要考虑实时数据从哪来,有一些网站会向外提供免费开放的数据api接口,直接调用就可以拿到数据,这是一个方法。但是我今天想做的是全头到尾不依赖其他第三方,独立的写一个完整的项目。
我这边想到的获取数据的方法就是爬虫,先叠个甲,咋们这个视频只是用于交流学习,不涉及商业行为,如有侵权联系我删除。
我选的框架是scrapy,当然你也可以用你熟悉的框架,那我们就直接开始。
首先安装scrapy,安装过程大家根据自己的操作系统搜索一下,到命令行输入scrapy有如下显示则安装成功。
使用scrapy的命令创建项目
scrapy startproject douban
这时候可以用编辑器打开这个项目,能看到目录结构是这样的:
里面有一个 spiders 目录,我们后面爬虫代码的主要逻辑就写在这个目录里。
Items 文件用来定义我们爬取到的数据字段和类型。
pipelines 文件用来执行保存数据的操作,后面我们会在其中写和数据库连接相关的代码。
middlewares 文件是中间件,我们这次用不上可以先忽略。
settings 文件顾名思义是设置文件,里面可以配置的东西很多,后面再详细。
好,看完目录现在来写主要的代码,我想要爬取的是豆瓣现在正在上映电影的评价,我们知道豆瓣的评分相对来说还是比较能代表口碑的,它又是一个会实时变化的值,那我们对数据爬取之后存入自己的数据库,就可以在前端展示当前线上电影评价排行还有单个电影的评价趋势等数据图表,方便自己挑选电影。
我们使用这个命令创建一个爬虫主文件,scrapy genspider main_dou 'https://movie.douban.com/cinema/nowplaying/yichang/'命令。
这时会看到spiders目录下有一个main_dou.py文件,里面已经给出了大致的架构,
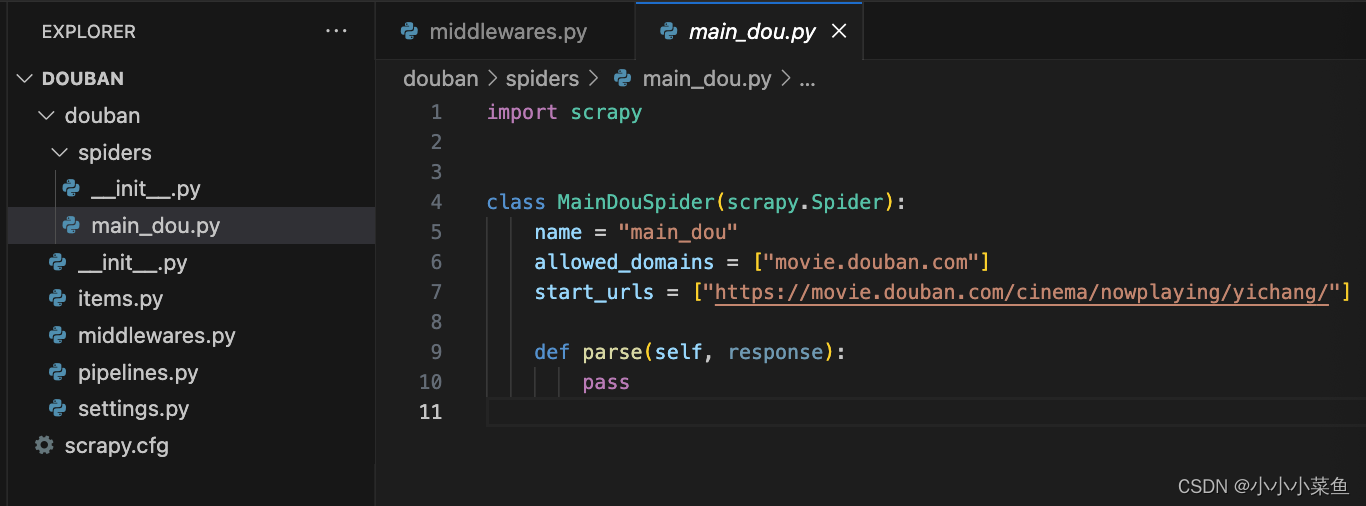
里面有一个用scrapy.Spider类创建的子类,并有三个属性和一个方法。
name 是唯一名称
allow_domains 是搜索的域名范围,规定只爬取这个域名下的网页
从 start_urls 开始抓取数据
parse(self, response) :每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,负责解析返回的网页数据(response.body),提取结构化数据(生成item)
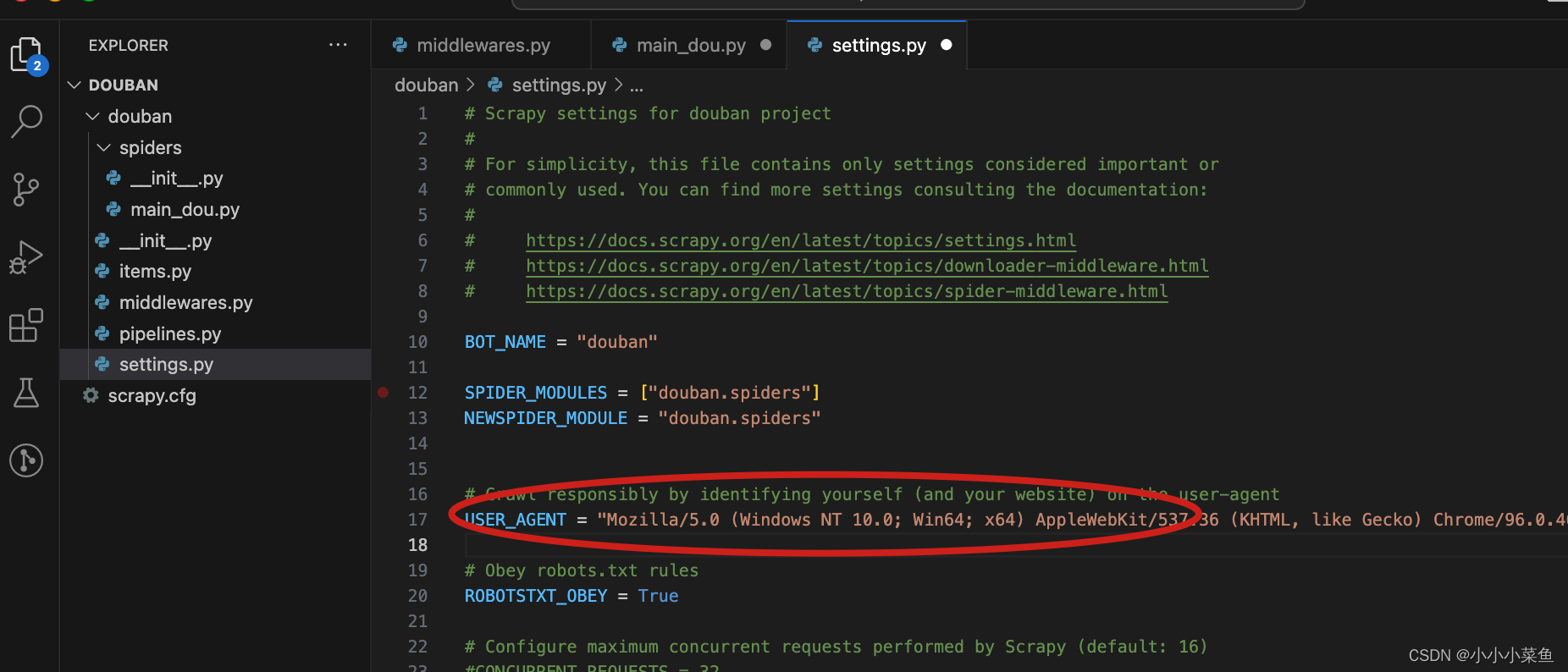
首先在settings中我们将user agent换一下
然后我们输入命令跑一下看能不能成功。
抓出来是乱码,是header的问题。
xpath
只需要懂三个符号
/ 直接子集(根元素)
// 可以跳级(不考虑位置)
@ 属性访问
我们直接在浏览器F12,在dom里可以按xpath语法搜索,
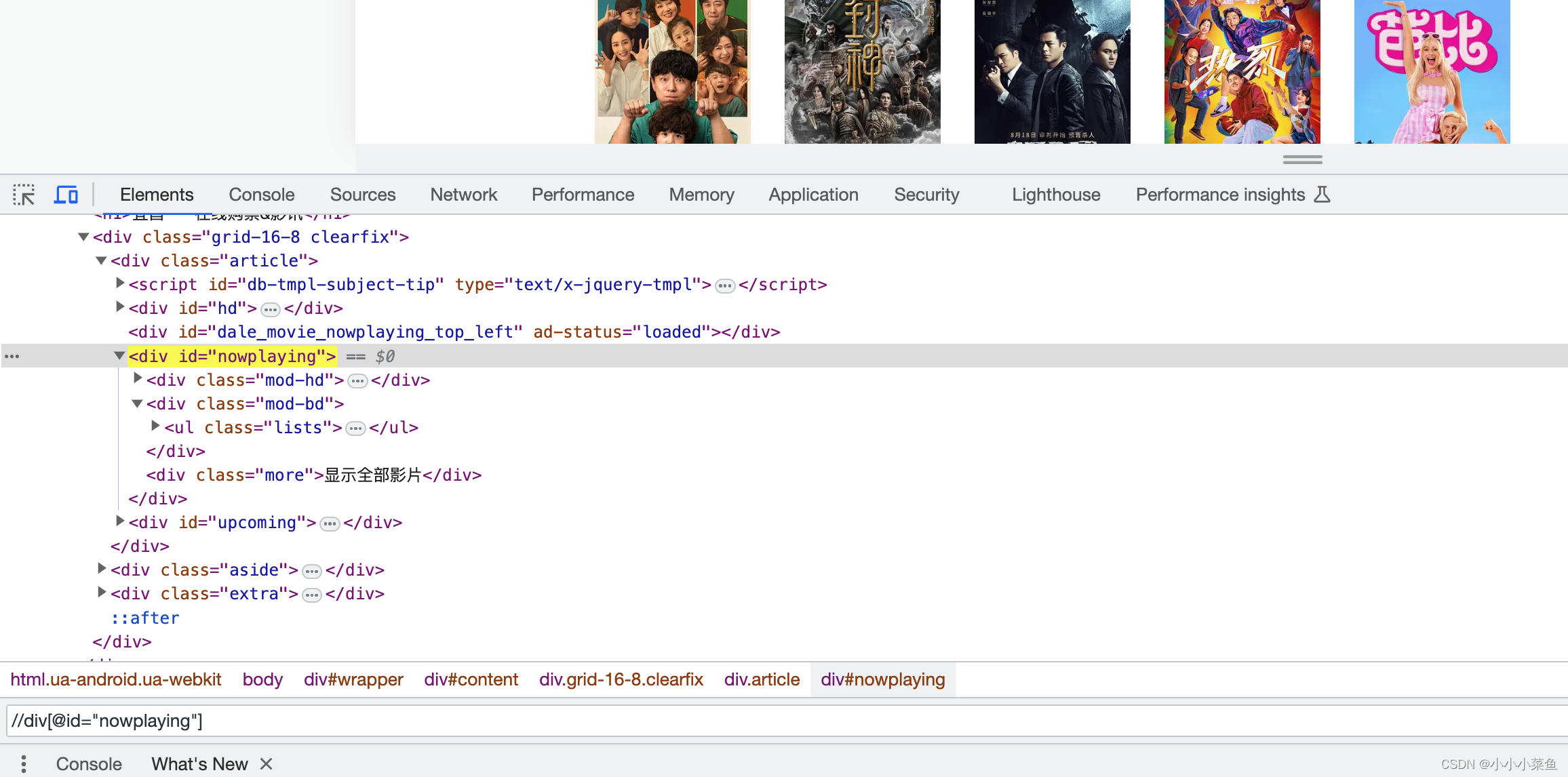
这里输入的意思就是找属性里id为nowplaying的div,是不是很简单。
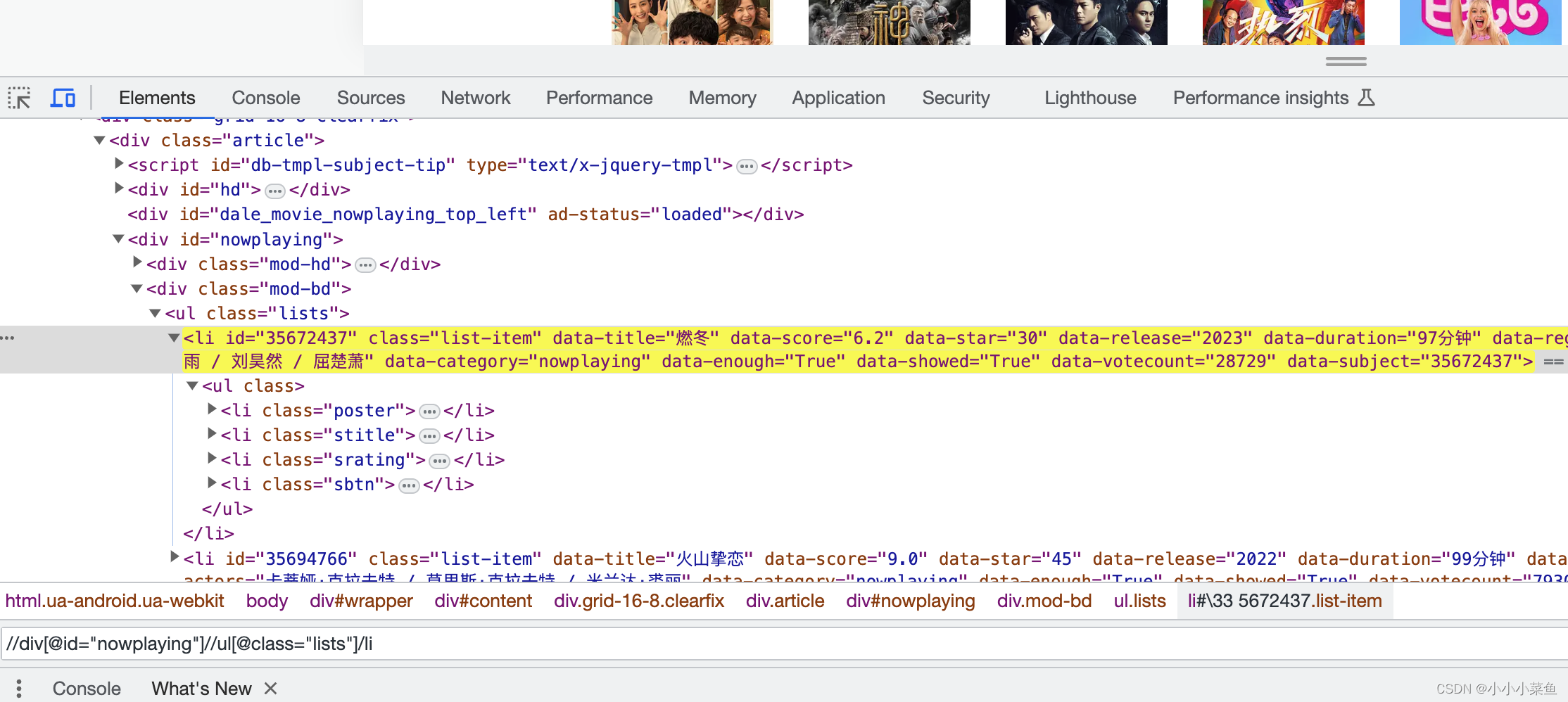
这样就找到了所有有上映影片信息的li标签,可以看到标签里有影片信息,我们提取对应属性就行。
最后的代码是这样,extract()方法用于从XPath结果中提取文本值,这样就爬到了所有影片名字和打分。
接下来我们要将数据存到数据库中,实现持久化。
我们在items文件里定义好数据字段,然后在主程里拼好每一组数据
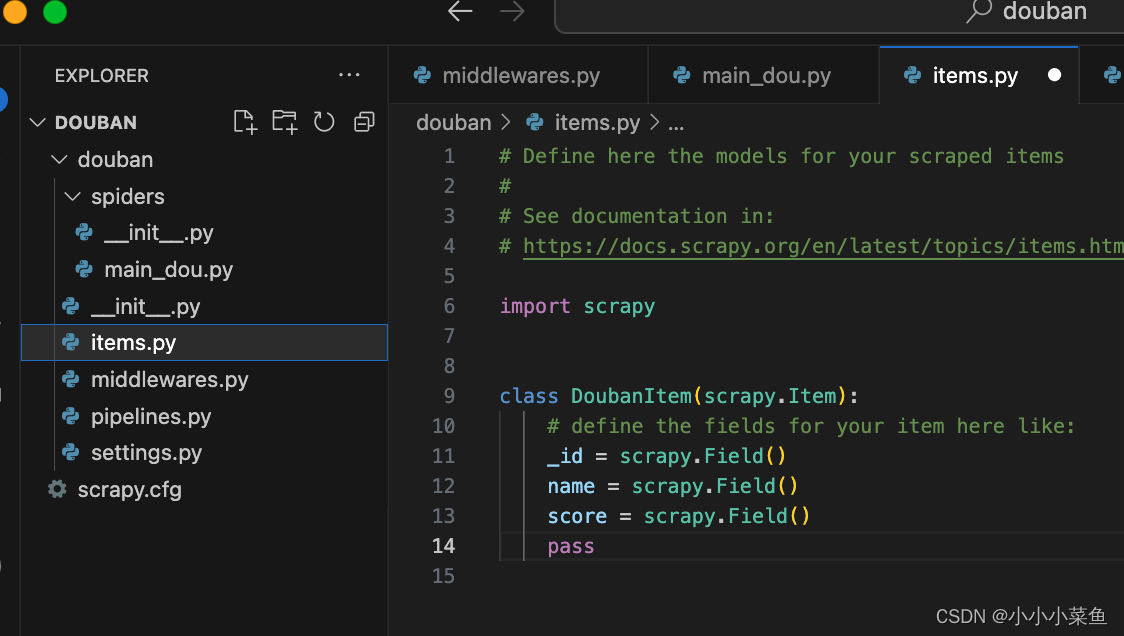
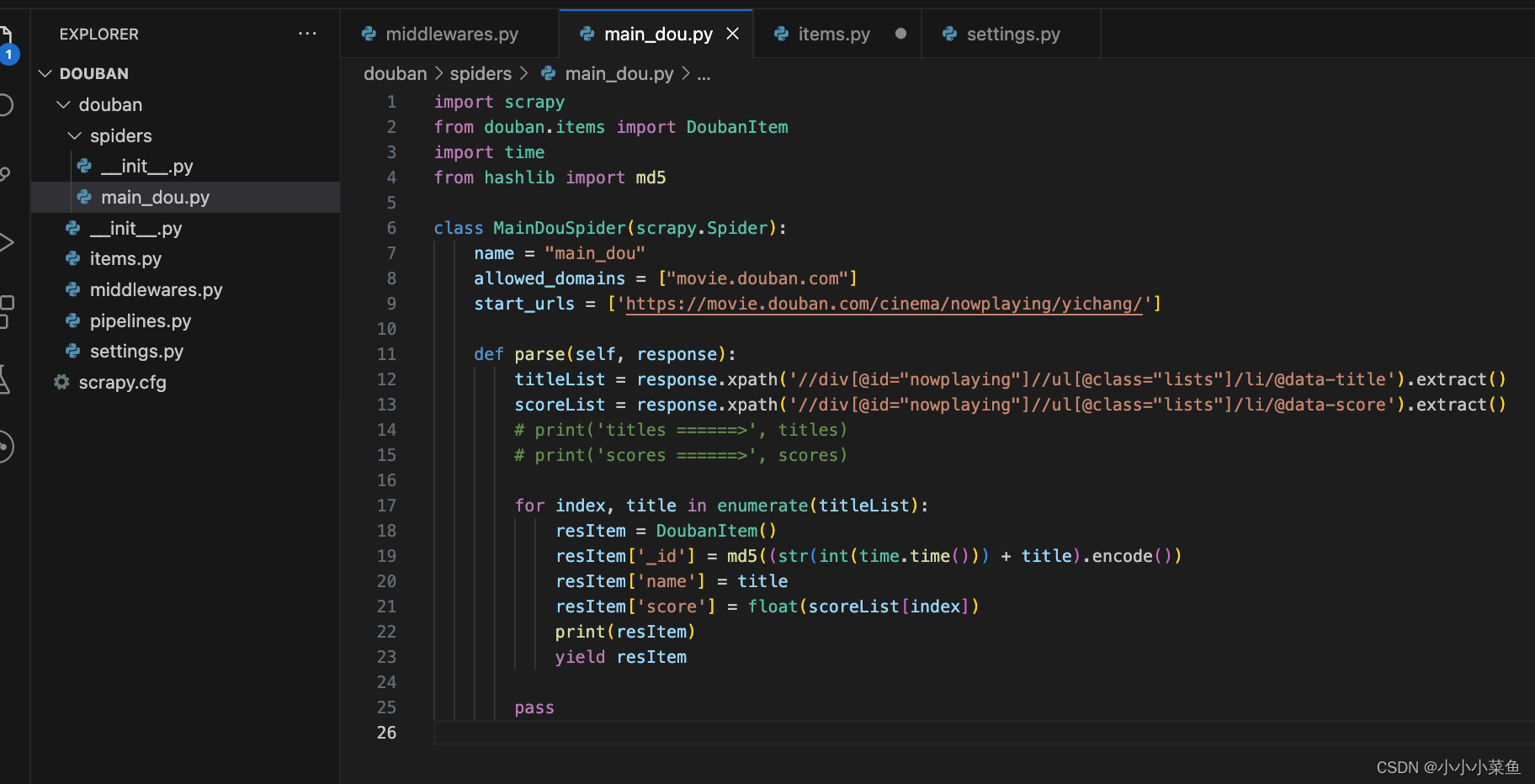
接下来我们要连接数据库,我这里用的mongodb,你们也可以使用自己熟悉的数据库比如mysql等。
在settings里写好数据库的地址,库名表名,账号密码等信息,在pipelines文件里进行注入。如果你也是用的mongodb,可以和我一样配置,不过其实别的数据库也差不多的。
再跑一下项目,发现数据库里已经成功写入数据了,我们这一步就完成了。
再只需要让这个scrapy项目按时自动执行我们数据库就有实时数据了,这个我们后面部署的部分再讲。
后端 DJANGO
我们已经有了数据,现在需要开发一个后端项目,对数据库的数据进行操作,并暴露api給前端。
因为我平时用python比较多,后端框架选型的时候就选了Django,当然也可以选你熟悉的框架。Django其实是一款前后端不分离的框架,将前端代码写在django的templates文件夹里。前后端冗杂在一块会比较难维护,针对前后端分离的情况,Django退出了DRF(Django Rest Framework)。那我们一步步来做。
首先在开发后端项目之前可以整一个虚拟环境,因为后端项目依赖的库会比较多,而各个后端项目之间如果库的版本各不相同就会比较麻烦,所以开启一个虚拟环境保证这个项目的依赖都是独立的。
sudo pip3 install virtualenv
virtualenv douban-env
source env/bin/activate
安装django
pip3 install django==3.2.1
pip3 install djangorestframework==3.12.4
django-admin.py startproject be_douban
cd be_douban
python3 manage.py startapp douban
此时的目录结构是这样的
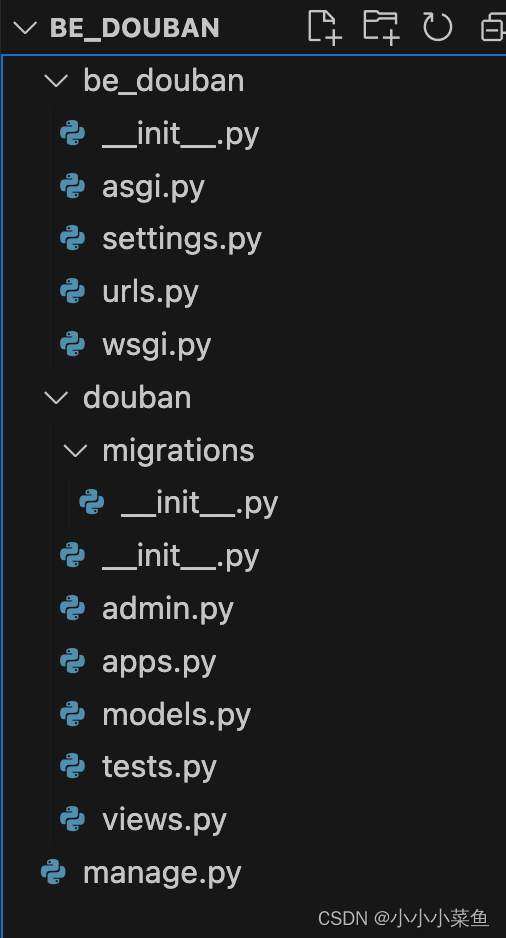
douban那个文件夹是我们创建出来的app,我们先到settings中注册这个app。
为了操作mongodb,我们需要安装djongo
我们来看一下DRF这个架构(这里借用一下大佬的图,图源见水印)
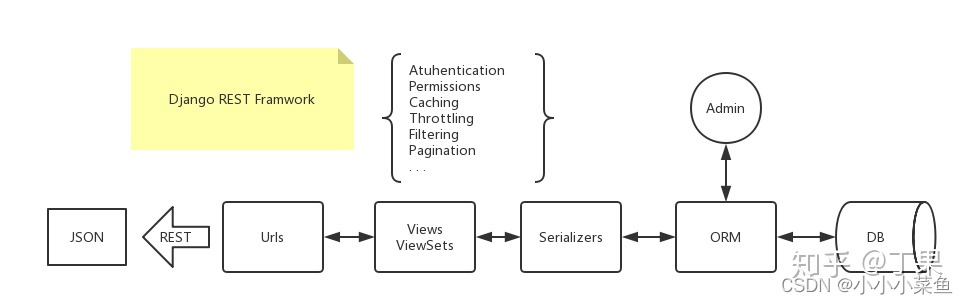
DRF是将数据库的东西通过ORM的映射取出来,通过view和serializers文件绑定REST接口,当前端请求时,返回序列化好的json。
我们从Modal开始修改:Model文件里定义了数据的结构和关系,类似于数据库表的描述。我们把之前爬虫存在数据库里的字段再这边再声明一下。
from djongo import models# Create your models here.class Douban(models.Model):_id = models.CharField(max_length=128, primary_key=True)name = models.CharField(max_length=128)score = models.FloatField()time = models.IntegerField()class Meta:db_table = 'spider_douban'
然后是序列化器,新建一个serializer.py文件,因为我们直接需要所有字段,这边fields直接__all__就行,如果不需要所有的,可以自己用数组定义 例如 fields = [‘_id’, ‘station’, ‘time’]
from douban.models import Douban
from rest_framework.serializers import ModelSerializerclass DoubanSerializer(ModelSerializer):class Meta:model = Doubanfields = '__all__'
最后是视图view文件,定义了API的行为,我们主要对数据处理的逻辑写在这,我们是需要一个接口拿到最新的所有电影的分数,然后在前端进行排行,那么就这么写。
from rest_framework.decorators import api_view
from rest_framework.response import Response
from douban.models import Douban
from douban.serializers import DoubanSerializer
from django.db.models import Max@api_view(['GET'])
def movie_lasttime_list(request):if request.method == 'GET':# 使用Djongo查询获取最后一次时间的时间戳last_time = Douban.objects.aggregate(Max('time'))['time__max']# 使用过滤器获取最后一次时间的所有数据movies = Douban.objects.filter(time=last_time)# 将查询到的数据序列化并返回serializer = DoubanSerializer(movies, many=True)return Response(serializer.data)
之后定义一下url,就是api的路径,我们在douban app下创建一个url文件
from django.urls import include, path
from douban import viewsurlpatterns = [path('api/current', views.movie_lasttime_list),
]
之后在主url文件中引入这个app的url文件
from django.contrib import admin
from django.urls import path, includeurlpatterns = [path('admin/', admin.site.urls),path('', include('douban.urls')),
]
现在就做完了,可以跑项目了,第一次要执行一下迁移命令
python3 manage.py makemigrations
python3 manage.py migrate
python3 manage.py runserver
这时候看到

证明已经跑起来了
浏览器输入对应url可以看到
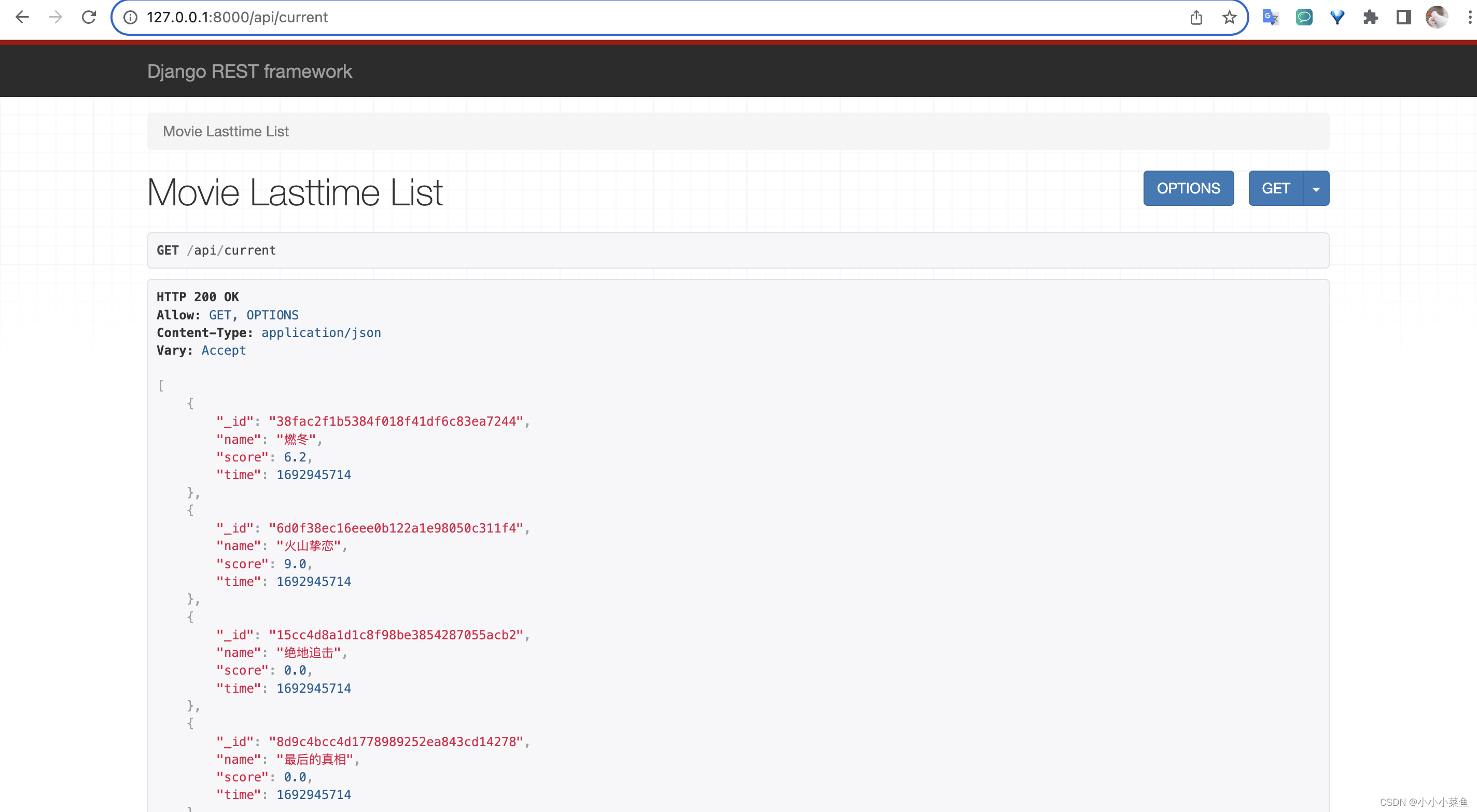
我们的接口就写好了。
除了最新数据,我们还需要一个趋势数据,就不一步步讲解了,和上面的一样,展示一下view文件的逻辑:
@api_view(['GET'])
def movie_scores_by_name(request):if request.method == 'GET':movies = Douban.objects.all() # 获取所有电影数据movie_scores = {} # 创建一个字典来存储电影名称和对应的时间和分数列表for movie in movies:if movie.name in movie_scores:movie_scores[movie.name].append({"time": movie.time, "score": movie.score})else:movie_scores[movie.name] = [{"time": movie.time, "score": movie.score}]return Response(movie_scores)前端 REACT
接下来看前端部分。
一般经常写前端的人都有自己熟悉的脚手架,我也有一套 react + ts + less + webpack 的脚手架。但是为了简单,毕竟这个教程不是一个前端各种技术栈的介绍,我们就是用最简单的官方的脚手架实现一下,它内部封装了webpack。
npm install -g create-react-app
create-react-app fe_douban
我们 npm start 看到下面这个页面就是项目跑起来了:

这是原始的目录,我们稍微调整一下结构。把src下的文件删掉只保留index.js和index.css,再创建一个container和component文件夹分别放容器和组件。
引入echarts,在命令行输入npm install echarts,可以看到package.json文件里已经有Echarts的依赖了
而echarts怎么用呢,我们在component目录下创建一个bar-chart文件夹,新建index.ts文件。用函数组件的写法吧,在useEddect里面对echart实例进行操作,简单来说就是先init初始化,然后定义Option,我们图表的所有配置都在option里面,这部分就不详述了,可以去Echarts官网看例子,还有手册,每个配置项都很详细,我就直接展示了。
import React, { useEffect, useRef } from 'react';
import * as echarts from 'echarts';import './index.css';const mockData = [{"_id": "8c7c957e237ff7ec2f848908fbea9817","name": "奥本海默","score": 8.7,"time": 1693390018}, {"_id": "21d53373fa67f1866993492cfb782d17","name": "燃冬","score": 6.2,"time": 1693390018}
]const BarChart = (props) => {const chartRef = useRef();let data = props.data || mockData;data.sort((a, b) => a.score - b.score);console.log(data)useEffect(() => {const chart = echarts.init(chartRef.current); //echart初始化容器let option = {title: {text: props.title ? props.title : '',textStyle: {color: '#aad8f8',fontWeight: 300,fontStyle: 'italic'}},color: ['#faeea0'],grid: {left: '15%'},tooltip: {trigger: 'axis'},xAxis: {type: 'value',axisLabel: {color: '#ffffff'}},yAxis: {type: 'category',data: data.map((item) => item.name)},series: [{data: data.map((item) => item.score),label: {show: true,position: 'inside',color: '#ffffff'},type: 'bar'}]};chart.setOption(option);const echartsResize = () => {echarts.init(chartRef.current).resize();};window.addEventListener('resize', echartsResize);return () => window.removeEventListener('resize', echartsResize);}, [props]);return <div className='bar-chart-container' ref={chartRef}></div>;
};export default BarChart;写好BarChart组件后在container创建一个homePage=,在其中引用之前写好的组件,并传入数据。数据是通过fetch方法在我们后端接口取得,具体代码如下:
import React from "react";import './index.css'
import BarChart from "../../component/bar-chart";class HomePage extends React.Component {state = {barData: null}componentDidMount() {fetch("http://127.0.0.1:8000/api/current").then(res => res.json()).then(data => {this.setState({barData: data});}, (e) => console.log(e))}render() {return (<div className="home-page">{/* <LineChart /> */}<BarChart title={"今日在映电影评分排名"} data={this.state.barData} /></div>)}
}export default HomePage;
现在打开页面,已经可以看到排名后的电影和评分了。这样整个流程就走通了。
最后将爬虫项目,前后端都部署到云服务器,将爬虫设置为定时任务,前端可以用 nginx,后端用 uwsgi + nginx。就可以了。