网站 站外链接搜索引擎营销案例有哪些
论文地址:https://arxiv.org/pdf/2408.15545
引言
科学文献的理解对于提取目标信息和获取洞察至关重要,这显著推动了科学发现。尽管大语言模型(LLMs)在自然语言处理方面取得了显著成功,但在科学文献理解方面仍面临挑战,主要由于缺乏科学知识和对特定科学任务的不熟悉。为了开发专门用于科学文献理解的LLM,我们提出了一种混合策略,结合持续预训练(CPT)和监督微调(SFT),以同时注入科学领域知识和增强特定任务的指令遵循能力。
1. 持续预训练(CPT)阶段
1.1 格式与语法校正
在从PDF文档中提取文本时,常常会引入许多格式和语法错误。为了解决这一问题,我们使用Llama3-8B-Instruct模型来校正这些错误。以下是一个校正前后的示例:
校正前的文本:
Highly p e n e t r a t i n g radiation, such as $\gamma$ -rays or fast electorns, deposits ener gy
throughout the solid t a r g e t material. Gas production occurs w i t h i n the solid phase and must d i f f u s e to the surface to be observed.
校正后的文本:
Highly penetrating radiation, such as $\gamma$ -rays or fast electrons, deposits energy throughout the solid target material. Gas production occurs within the solid phase and must diffuse to the surface to be observed.

1.2 CPT质量过滤
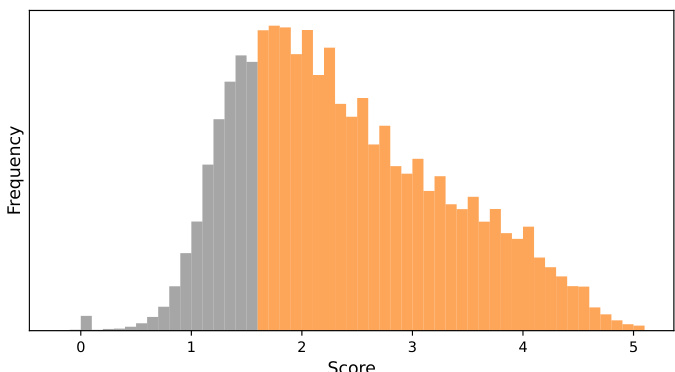
为了确保训练语料的高质量,我们使用Llama3-70B-Instruct模型对50k个样本进行评分,并根据评分结果过滤掉质量较低的25%数据。以下是评分分布图:
2. 监督微调(SFT)阶段
2.1 指令生成
为了生成多样化的科学指令,我们设计了一个三步流程:
- 领域关键词概率表:收集高影响力论文并统计词频,生成领域关键词概率表。
- 科学任务列表:编译一个包含各种科学任务的任务列表。
- 指令生成:根据关键词和任务描述生成科学上下文和相应的问答对。
以下是一个生成表格提取任务的示例:
生成表格提取任务的提示:
I need synthetic training data for training a machine learning model that extracts tables from text correctly. The data should be formatted in JSON, with each entry containing ”text” and ”answer” attributes. You should generate a paragraph that includes the keywords: $\{\{\mathrm{keywords}\}\}$ .
The ”text” part must contain enough information for the table to be extracted! In ”text” part, You must you include a table description in latex format.
生成的示例:
{
”text”: ”In recent studies regarding material science, the crmatrix has shown significant importance in understanding fracture behaviors. The following Table 1 presents a schematic illustration of the enthalpy changes observed during the different fracture phases.”,
”answer”: ”Material,Initial Enthalpy (kJ/mol),Final Enthalpy (kJ/mol),Fracture Phase
Material A,25.4,47.8,Brittle
Material B,22.3,45.0,Ductile
Material C,28.9,50.2,Semi-brittle”
}
2.2 指令质量控制
为了确保生成指令的质量,我们采用启发式去重和基于LLM的过滤方法。以下是评估示例:

3. 实验结果
3.1 基准模型性能
SciLitLLM在科学文献理解任务上表现优异,7B和14B版本的模型在SciAssess和SciRIFF基准测试中均取得了领先的成绩。具体来说,SciLitLLM-7B在SciAssess上比第二好的模型高出4.0%,在SciRIFF上高出10.1%。
3.2 消融研究
我们进行了消融实验来验证CPT阶段、SFT数据配方和指令质量过滤的有效性。结果表明,CPT阶段对提高科学文献理解能力至关重要,而SFT阶段使用SciLitIns数据集也能显著提升模型性能。

4. 结论与未来工作
本文介绍了SciLitLLM,一个专门用于科学文献理解的模型。通过CPT和SFT的结合,我们成功地提升了模型在科学领域的知识基础和指令遵循能力。未来的工作将致力于扩展训练数据的多样性和质量,并探索更高效的方法进行领域特定知识注入和高品质指令生成。
参考文献
- Cai, H., Cai, X., Chang, J., Li, S., Yao, L., Wang, C., … & Ke, G. (2024). Sciassess: Benchmarking LLM proficiency in scientific literature analysis. arXiv preprint arXiv:2403.01976.
- Wadden, D., Shi, K., Morrison, J., Naik, A., Singh, S., Barzilay, N., … & Cohan, A. (2024). Sciriff: A resource to enhance language model instruction-following over scientific literature. arXiv preprint arXiv:2406.07835.
希望这篇文章对你有所帮助!如果你有任何问题或建议,欢迎在评论区留言。