做关于植物的网站google关键词分析工具
简介
Spark Streaming是Apache Spark生态系统中的一个组件,用于实时流式数据处理。它提供了类似于Spark的API,使开发者可以使用相似的编程模型来处理实时数据流。
Spark Streaming的工作原理是将连续的数据流划分成小的批次,并将每个批次作为RDD(弹性分布式数据集)来处理。这样,开发者可以使用Spark的各种高级功能,如map、reduce、join等,来进行实时数据处理。Spark Streaming还提供了内置的窗口操作、状态管理、容错处理等功能,使得开发者能够轻松处理实时数据的复杂逻辑。
Spark Streaming支持多种数据源,包括Kafka、Flume、HDFS、S3等,因此可以轻松地集成到各种数据管道中。它还能够与Spark的批处理和SQL引擎进行无缝集成,从而实现流式处理与批处理的混合使用。

本文以 TCP、kafka场景讲解spark streaming的使用
消息队列下的信息铺抓
类似消息队列的有redis、kafka等核心组件。
本文以kafka为例,向kafka中实时抓取数据,
pom.xml中添加以下依赖
<dependencies><!-- Spark Core --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.2.0</version></dependency><!-- Spark Streaming --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.12</artifactId><version>3.2.0</version></dependency><!-- Spark SQL --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>3.2.0</version></dependency><!-- Kafka --><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>2.8.0</version></dependency><!-- Spark Streaming Kafka Connector --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.12</artifactId><version>3.2.0</version></dependency><!-- PostgreSQL JDBC --><dependency><groupId>org.postgresql</groupId><artifactId>postgresql</artifactId><version>42.2.24</version></dependency>
</dependencies>创建项目编写以下代码实现功能
package org.example;import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.sql.*;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructType;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import org.apache.kafka.common.serialization.StringDeserializer;import java.util.*;public class SparkStreamingKafka {public static void main(String[] args) throws InterruptedException {// 创建 Spark 配置SparkConf sparkConf = new SparkConf().setAppName("spark_kafka").setMaster("local[*]").setExecutorEnv("setLogLevel", "ERROR");//设置日志等级为ERROR,避免日志增长导致的磁盘膨胀// 创建 Spark Streaming 上下文JavaStreamingContext streamingContext = new JavaStreamingContext(sparkConf, new Duration(2000)); // 间隔两秒扑捉一次// 创建 Spark SQL 会话SparkSession sparkSession = SparkSession.builder().config(sparkConf).getOrCreate();// 设置 Kafka 相关参数Map<String, Object> kafkaParams = new HashMap<>();kafkaParams.put("bootstrap.servers", "10.0.0.105:9092,10.0.0.106:9092,10.0.0.107:9092");kafkaParams.put("key.deserializer", StringDeserializer.class);kafkaParams.put("value.deserializer", StringDeserializer.class);kafkaParams.put("auto.offset.reset", "earliest");// auto.offset.reset可指定参数有// latest:从分区的最新偏移量开始读取消息。// earliest:从分区的最早偏移量开始读取消息。// none:如果没有有效的偏移量,则抛出异常。kafkaParams.put("enable.auto.commit", true); //采用自动提交offset 的模式kafkaParams.put("auto.commit.interval.ms",2000);//每隔离两秒提交一次commited-offsetkafkaParams.put("group.id", "spark_kafka"); //消费组名称// 创建 Kafka streamCollection<String> topics = Collections.singletonList("spark_kafka"); // Kafka 主题名称JavaDStream<ConsumerRecord<String, String>> kafkaStream = KafkaUtils.createDirectStream(streamingContext,LocationStrategies.PreferConsistent(),ConsumerStrategies.Subscribe(topics, kafkaParams) //订阅kafka);//定义数据结构StructType schema = new StructType().add("key", DataTypes.LongType).add("value", DataTypes.StringType);kafkaStream.foreachRDD((VoidFunction<JavaRDD<ConsumerRecord<String, String>>>) rdd -> {// 转换为 DataFrameDataset<Row> df = sparkSession.createDataFrame(rdd.map(record -> {return RowFactory.create(record.offset(), record.value()); //将偏移量和value聚合}), schema);// 写入到 PostgreSQLdf.write()//选择写入数据库的模式.mode(SaveMode.Append)//采用追加的写入模式//协议.format("jdbc")//option 参数.option("url", "jdbc:postgresql://localhost:5432/postgres") // PostgreSQL 连接 URL//确定表名.option("dbtable", "public.spark_kafka")//指定表名.option("user", "postgres") // PostgreSQL 用户名.option("password", "postgres") // PostgreSQL 密码.save();});// 启动 Spark StreamingstreamingContext.start();// 等待 Spark Streaming 应用程序终止streamingContext.awaitTermination();}
}在执行代码前,向创建名为spark_kafka的topic
kafka-topics.sh --create --topic spark_kafka --bootstrap-server 10.0.0.105:9092,10.0.0.106:9092,10.0.0.107:9092向spark_kafka 主题进行随机推数
kafka-producer-perf-test.sh --topic spark_kafka --thrghput 10 --num-records 10000 --record-size 100000 --producer-props bootstrap.servers=10.0.0.105:9092,10.0.0.106:9092,10.0.0.107:9092运行过程中消费的offset会一直被提交到每一个分区
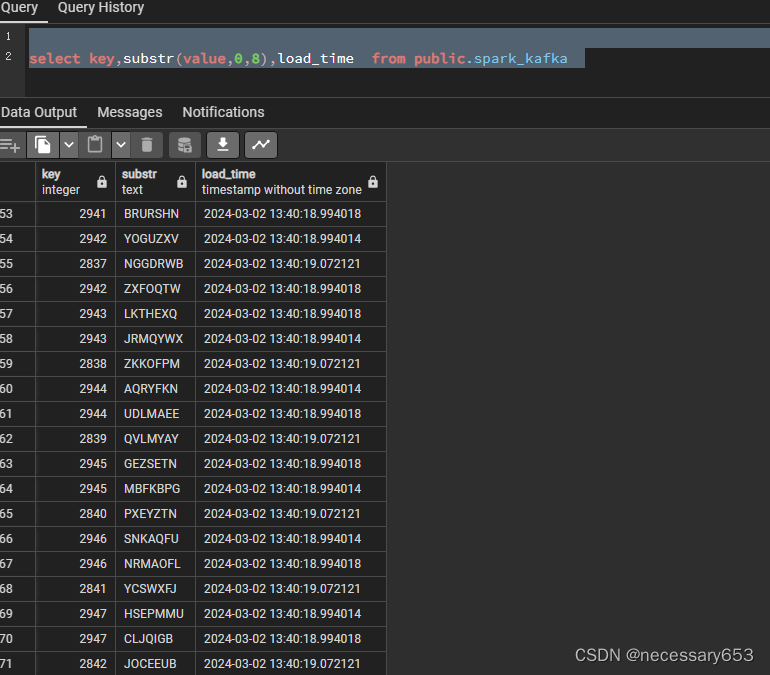
此时在数据库中查看,数据已经实时落地到库中
TCP
TCP环境下,实时监控日志的输出,可用于监控设备状态、环境变化等。当监测到异常情况时,可以实时发出警报。
package org.example;import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.sql.*;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructType;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import org.apache.kafka.common.serialization.StringDeserializer;import java.util.*;public class SparkStreamingKafka {public static void main(String[] args) throws InterruptedException {// 创建 Spark 配置SparkConf sparkConf = new SparkConf().setAppName("spark_kafka") // 设置应用程序名称.setMaster("local[*]") // 设置 Spark master 为本地模式,[*]表示使用所有可用核心// 设置日志等级为ERROR,避免日志增长导致的磁盘膨胀.setExecutorEnv("setLogLevel", "ERROR");// 创建 Spark Streaming 上下文JavaStreamingContext streamingContext = new JavaStreamingContext(sparkConf, new Duration(2000)); // 间隔两秒扑捉一次// 创建 Spark SQL 会话SparkSession sparkSession = SparkSession.builder().config(sparkConf).getOrCreate();// 设置 Kafka 相关参数Map<String, Object> kafkaParams = new HashMap<>();kafkaParams.put("bootstrap.servers", "10.0.0.105:9092,10.0.0.106:9092,10.0.0.107:9092"); // Kafka 服务器地址kafkaParams.put("key.deserializer", StringDeserializer.class); // key 反序列化器类kafkaParams.put("value.deserializer", StringDeserializer.class); // value 反序列化器类kafkaParams.put("auto.offset.reset", "earliest"); // 从最早的偏移量开始消费消息kafkaParams.put("enable.auto.commit", true); // 采用自动提交 offset 的模式kafkaParams.put("auto.commit.interval.ms", 2000); // 每隔两秒提交一次 committed-offsetkafkaParams.put("group.id", "spark_kafka"); // 消费组名称// 创建 Kafka streamCollection<String> topics = Collections.singletonList("spark_kafka"); // Kafka 主题名称JavaDStream<ConsumerRecord<String, String>> kafkaStream = KafkaUtils.createDirectStream(streamingContext,LocationStrategies.PreferConsistent(),ConsumerStrategies.Subscribe(topics, kafkaParams) // 订阅 Kafka);// 定义数据结构StructType schema = new StructType().add("key", DataTypes.LongType).add("value", DataTypes.StringType);kafkaStream.foreachRDD((VoidFunction<JavaRDD<ConsumerRecord<String, String>>>) rdd -> {// 转换为 DataFrameDataset<Row> df = sparkSession.createDataFrame(rdd.map(record -> {return RowFactory.create(record.offset(), record.value()); // 将偏移量和 value 聚合}), schema);// 写入到 PostgreSQLdf.write()// 选择写入数据库的模式.mode(SaveMode.Append) // 采用追加的写入模式// 协议.format("jdbc")// option 参数.option("url", "jdbc:postgresql://localhost:5432/postgres") // PostgreSQL 连接 URL// 确定表名.option("dbtable", "public.spark_kafka") // 指定表名.option("user", "postgres") // PostgreSQL 用户名.option("password", "postgres") // PostgreSQL 密码.save();});// 启动 Spark StreamingstreamingContext.start();// 等待 Spark Streaming 应用程序终止streamingContext.awaitTermination();}
}在10.0.0.108 打开9999端口键入数值 ,使其被spark接收到并进行运算
nc -lk 9999开启端口可以键入数值 此时会在IDEA的控制台显示其计算值
