325平台代理武汉百度seo排名
目录
- 1. 引言
- 1.1 文本生成的定义和作用
- 1.2 自然语言处理技术在文本生成领域的使用
- 2 传统方法 - 基于统计的方法
- 2.1.1 N-gram模型
- 2.1.2 平滑技术
- 3. 传统方法 - 基于模板的生成
- 3.1 定义与特点
- 3.2 动态模板
- 4. 神经网络方法 - 长短时记忆网络(LSTM)
- LSTM的核心概念
- PyTorch中的LSTM
- 5. 神经网络方法 - Transformer
- Transformer的核心概念
- PyTorch中的Transformer
- 6. 大型预训练模型 - GPT文本生成机制
- 大型预训练模型的核心概念
本文深入探讨了文本生成的多种方法,从传统的基于统计和模板的技术到现代的神经网络模型,尤其是LSTM和Transformer架构。文章还详细介绍了大型预训练模型如GPT在文本生成中的应用,并提供了Python和PyTorch的实现代码。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

1. 引言
1.1 文本生成的定义和作用
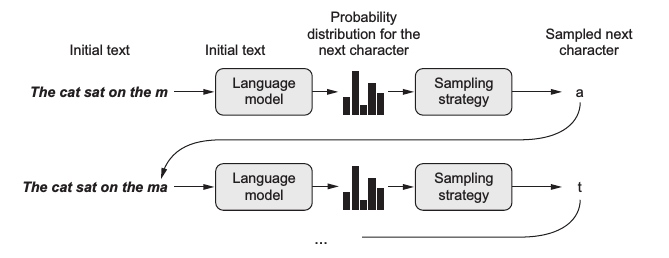
文本生成是自然语言处理的一个核心子领域,它涉及使用模型来自动创建自然语言文本。这种生成可以是基于某些输入的响应,如图像或其他文本,也可以是完全自主的创造。
文本生成的任务可以是简单的,如自动回复邮件,也可以是更复杂的,如编写新闻文章或生成故事。它通常包括以下步骤:
- 确定目标和约束:明确生成文本的目标和约束条件,如风格、语言和长度等。
- 内容的生成:基于预定义的目标和约束条件来生成内容。
- 评价和优化:使用不同的评价指标来测试生成的文本,并进行必要的优化。
例子:
- 自动回复邮件:根据收到的邮件内容,系统可以生成一个简短的、相关的回复。
- 新闻文章生成:利用已有的数据和信息来自动生成新闻文章。
- 故事生成:创建一个可以根据输入的提示来生成故事的系统。
1.2 自然语言处理技术在文本生成领域的使用
自然语言处理技术为文本生成提供了强大的工具和方法。这些技术可以用于解析输入数据、理解语言结构、评估生成文本的质量,以及优化生成过程。
-
序列到序列模型:这是一个广泛应用于文本生成任务的框架,如机器翻译和摘要生成。模型学习将输入序列(如句子)转化为输出序列(如另一种语言的句子)。
-
注意力机制:在处理长序列时,注意力机制可以帮助模型关注输入数据的关键部分,从而产生更准确的输出。
-
预训练语言模型:像BERT和GPT这样的模型通过大量的文本数据进行预训练,之后可以用于各种NLP任务,包括文本生成。
-
优化技术:如束搜索和采样策略,它们可以帮助生成更流畅、准确的文本。
例子:
- 机器翻译:使用序列到序列模型,将英语句子转化为法语句子。
- 生成摘要:利用注意力机制从长篇文章中提取关键信息,生成简短的摘要。
- 文本填充:使用预训练的GPT模型,根据给定的开头生成一个完整的故事。
随着技术的进步,自然语言处理技术在文本生成中的应用也越来越广泛,为我们提供了更多的可能性和机会。
2 传统方法 - 基于统计的方法
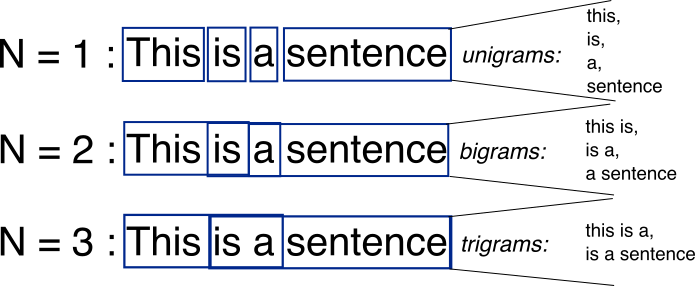
在深度学习技术盛行之前,文本生成主要依赖于基于统计的方法。这些方法通过统计语料库中的词语和短语的频率,预测下一个词或短语的出现概率。
2.1.1 N-gram模型
定义:N-gram模型是基于统计的文本生成方法中的一种经典技术。它基于一个假设,即第N个词的出现只与前面的N-1个词有关。例如,在一个trigram(3-gram)模型中,下一个词的出现只与前两个词有关。
例子:考虑句子 “我爱学习人工智能”,在一个bigram(2-gram)模型中,“人工” 出现后的下一个词可能是 “智能”。
from collections import defaultdict, Counter
import randomdef build_ngram_model(text, n=2):model = defaultdict(Counter)for i in range(len(text) - n):context, word = tuple(text[i:i+n-1]), text[i+n-1]model[context][word] += 1return modeldef generate_with_ngram(model, max_len=20):context = random.choice(list(model.keys()))output = list(context)for i in range(max_len):if context not in model:breaknext_word = random.choices(list(model[context].keys()), weights=model[context].values())[0]output.append(next_word)context = tuple(output[-len(context):])return ' '.join(output)text = "我 爱 学习 人工 智能".split()
model = build_ngram_model(text, n=2)
generated_text = generate_with_ngram(model)
print(generated_text)
2.1.2 平滑技术
定义:在统计模型中,我们经常会遇到一个问题,即语料库中可能有一些N-grams从未出现过,导致其概率为0。为了解决这个问题,我们使用平滑技术来为这些未出现的N-grams分配一个非零概率。
例子:使用Add-1平滑(Laplace平滑),我们将每个词的计数加1,来保证没有词的概率为0。
def laplace_smoothed_probability(word, context, model, V):return (model[context][word] + 1) / (sum(model[context].values()) + V)V = len(set(text))
context = ('我', '爱')
probability = laplace_smoothed_probability('学习', context, model, V)
print(f"P('学习'|'我 爱') = {probability}")
通过使用基于统计的方法,虽然我们可以生成文本,但这些方法有其局限性,尤其是在处理长文本时。随着深度学习技术的发展,更先进的模型逐渐取代了传统方法,为文本生成带来了更多的可能性。
3. 传统方法 - 基于模板的生成
基于模板的文本生成是一种早期的文本生成方法,依赖于预定义的句子结构和词汇来创建文本。这种方法虽然简单直观,但其生成的文本通常缺乏变化和多样性。
3.1 定义与特点
定义:模板生成方法涉及到使用预先定义的文本模板和固定的结构,根据不同的数据或上下文填充这些模板,从而生成文本。
特点:
- 确定性:输出是可预测的,因为它直接基于模板。
- 快速生成:不需要复杂的计算,只需简单地填充模板。
- 局限性:输出可能缺乏多样性和自然感,因为它完全基于固定模板。
例子:在天气预报中,可以有一个模板:“今天在{城市}的最高温度为{温度}度。”。根据不同的数据,我们可以填充该模板,生成如“今天在北京的最高温度为25度。”的句子。
def template_generation(template, **kwargs):return template.format(**kwargs)template = "今天在{city}的最高温度为{temperature}度。"
output = template_generation(template, city="北京", temperature=25)
print(output)
3.2 动态模板
定义:为了增加文本的多样性,我们可以设计多个模板,并根据上下文或随机性选择不同的模板进行填充。
例子:针对天气预报,我们可以有以下模板:
- “{city}今天的温度达到了{temperature}度。”
- “在{city},今天的最高气温是{temperature}度。”
import randomdef dynamic_template_generation(templates, **kwargs):chosen_template = random.choice(templates)return chosen_template.format(**kwargs)templates = ["{city}今天的温度达到了{temperature}度。","在{city},今天的最高气温是{temperature}度。"
]output = dynamic_template_generation(templates, city="上海", temperature=28)
print(output)
尽管基于模板的方法为文本生成提供了一种简单和直接的方式,但它在处理复杂和多样化的文本生成任务时可能会显得力不从心。现代深度学习方法提供了更强大、灵活和多样化的文本生成能力,逐渐成为主流方法。
4. 神经网络方法 - 长短时记忆网络(LSTM)
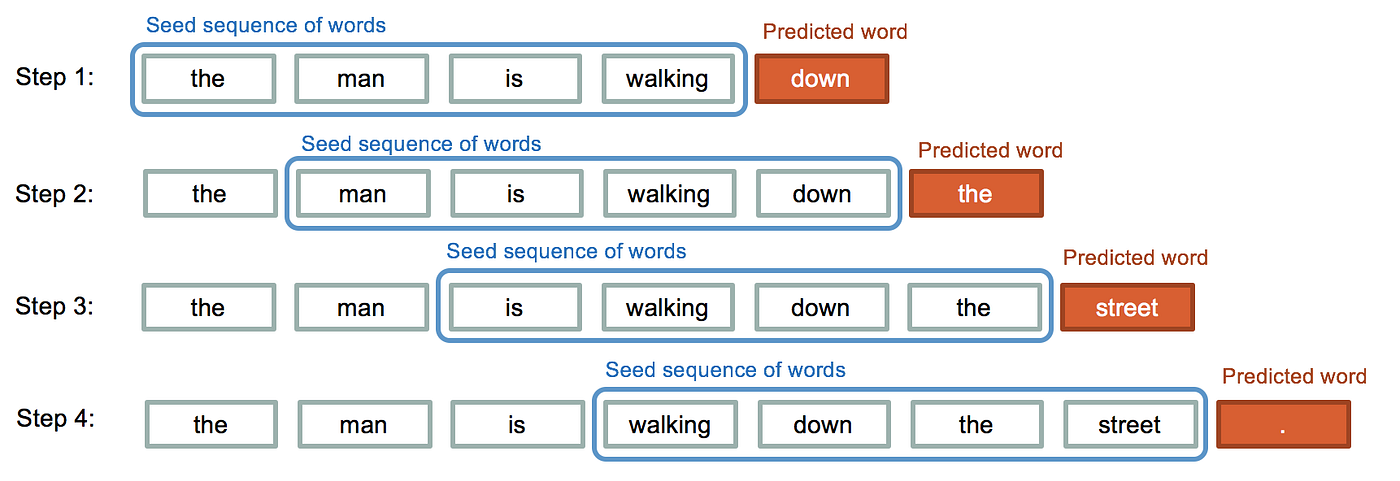
长短时记忆网络(LSTM)是一种特殊的递归神经网络(RNN),专为解决长期依赖问题而设计。在传统的RNN中,随着时间步的增加,信息的传递会逐渐变得困难。LSTM通过其特殊的结构来解决这个问题,允许信息在时间步之间更容易地流动。
LSTM的核心概念
定义:LSTM的核心是其细胞状态,通常表示为(C_t)。与此同时,LSTM包含三个重要的门:遗忘门、输入门和输出门,这三个门共同决定信息如何被更新、存储和检索。
- 遗忘门:决定哪些信息从细胞状态中被遗忘或丢弃。
- 输入门:更新细胞状态,决定哪些新信息被存储。
- 输出门:基于细胞状态,决定输出什么信息。
例子:假设我们正在处理一个文本序列,并想要记住某个词汇的性别标记(如“他”或“她”)。当我们遇到一个新的代词时,遗忘门可能会帮助模型忘记旧的性别标记,输入门会帮助模型存储新的标记,而输出门则会在下一个时间步输出这个标记,以保持序列的一致性。
PyTorch中的LSTM
使用PyTorch,我们可以轻松地定义和训练一个LSTM模型。
import torch.nn as nn
import torch# 定义LSTM模型
class LSTMModel(nn.Module):def __init__(self, input_dim, hidden_dim, output_dim, num_layers):super(LSTMModel, self).__init__()self.lstm = nn.LSTM(input_dim, hidden_dim, num_layers, batch_first=True)self.linear = nn.Linear(hidden_dim, output_dim)def forward(self, x):# 初始化隐藏状态和细胞状态h0 = torch.zeros(num_layers, x.size(0), hidden_dim).requires_grad_()c0 = torch.zeros(num_layers, x.size(0), hidden_dim).requires_grad_()out, (hn, cn) = self.lstm(x, (h0.detach(), c0.detach()))out = self.linear(out[:, -1, :])return outinput_dim = 10
hidden_dim = 20
output_dim = 1
num_layers = 1
model = LSTMModel(input_dim, hidden_dim, output_dim, num_layers)# 一个简单的例子,输入形状为 (batch_size, time_steps, input_dim)
input_seq = torch.randn(5, 10, 10)
output = model(input_seq)
print(output.shape) # 输出形状为 (batch_size, output_dim)
LSTM由于其在处理时间序列数据,尤其是在长序列中保留关键信息的能力,已经在多种自然语言处理任务中取得了显著的成功,例如文本生成、机器翻译和情感分析等。
5. 神经网络方法 - Transformer
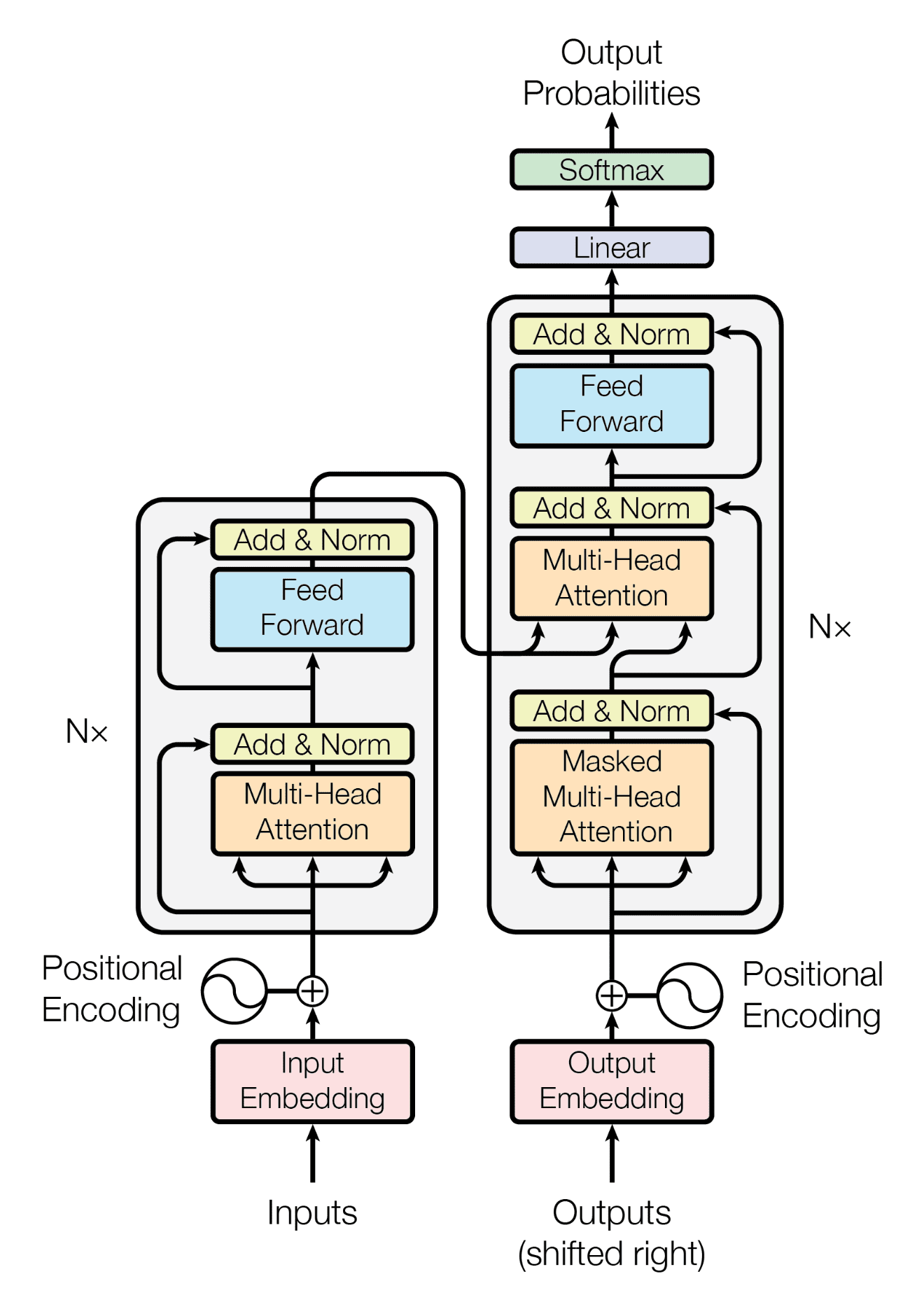
Transformer 是近年来自然语言处理领域的重要进展,它摒弃了传统的递归和卷积结构,完全依赖自注意力机制来处理序列数据。
Transformer的核心概念
定义:Transformer 是一个基于自注意力机制的深度学习模型,旨在处理序列数据,如文本。其核心是多头自注意力机制,可以捕捉序列中不同位置间的依赖关系,无论它们之间有多远。
多头自注意力:这是 Transformer 的关键部分。每个“头”都学习序列中的不同位置的表示,然后将这些表示组合起来。
位置编码:由于 Transformer 不使用递归或卷积,因此需要额外的位置信息来了解序列中词的位置。位置编码将这种信息添加到序列的每个位置。
例子:考虑句子 “The cat sat on the mat.” 如果我们想强调 “cat” 和 “mat” 之间的关系,多头自注意力机制使 Transformer 可以同时关注 “cat” 和距离较远的 “mat”。
PyTorch中的Transformer
使用 PyTorch,我们可以使用现成的 Transformer 模块来定义一个简单的 Transformer 模型。
import torch.nn as nn
import torchclass TransformerModel(nn.Module):def __init__(self, d_model, nhead, num_encoder_layers, num_decoder_layers):super(TransformerModel, self).__init__()self.transformer = nn.Transformer(d_model, nhead, num_encoder_layers, num_decoder_layers)self.fc = nn.Linear(d_model, d_model) # 示例中的一个简单的线性层def forward(self, src, tgt):output = self.transformer(src, tgt)return self.fc(output)d_model = 512
nhead = 8
num_encoder_layers = 6
num_decoder_layers = 6model = TransformerModel(d_model, nhead, num_encoder_layers, num_decoder_layers)# 示例输入,形状为 (sequence_length, batch_size, d_model)
src = torch.randn(10, 32, d_model)
tgt = torch.randn(20, 32, d_model)output = model(src, tgt)
print(output.shape) # 输出形状为 (tgt_sequence_length, batch_size, d_model)
Transformer 由于其强大的自注意力机制和并行处理能力,已经在多种自然语言处理任务中取得了突破性的成果,如 BERT、GPT 和 T5 等模型都是基于 Transformer 架构构建的。
6. 大型预训练模型 - GPT文本生成机制
近年来,大型预训练模型如 GPT、BERT 和 T5 等已成为自然语言处理领域的标准模型。它们在多种任务上都展现出了卓越的性能,尤其在文本生成任务上。
大型预训练模型的核心概念
定义:大型预训练模型是通过在大量无标签数据上进行预训练的模型,然后在具体任务上进行微调。这种“预训练-微调”范式使得模型能够捕捉到自然语言的丰富表示,并为各种下游任务提供一个强大的起点。
预训练:模型在大规模文本数据上进行无监督学习,如书籍、网页等。此时,模型学习到了词汇、语法和一些常识信息。
微调:在预训练后,模型在特定任务的标记数据上进行有监督学习,如机器翻译、文本生成或情感分析。
例子:考虑 GPT-3,它首先在大量的文本上进行预训练,学习到语言的基本结构和信息。然后,可以用很少的样本或无需任何额外的训练,直接在特定任务上生成文本。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。