网站建设设计公司网络营销品牌公司
目录
- 面试题一:Java中有哪些容器(集合类)?
- 追问:Java中的容器,线程安全和线程不安全的分别有哪些?
- 面试题二: HashMap 的实现原理/底层数据结构? JDK1.7 和 JDK1.8
- 追问一:当new一个HashMap的时候,会发生什么吗?
- 追问二:描述一下 Map put 的过程
- 追问三: JDK 7和 JDK 8中的 HashMap 有什么区别?
- 面试题三:hash 碰撞是什么以及如何解决
面试题一:Java中有哪些容器(集合类)?
Java 中的集合类主要由「Collection」和「Map」这两个接口派生而出,其中 Collection 接口又派生出三个子接口,分别是 Set、List、Queue。所有的 Java 集合类,都是 Set、List、Queue、Map 这四个接口的实现类,这四个接口将集合分成了四大类,其中 Set 代表无序的,元素不可重复的集合;List 代表有序的,元素可以重复的集合;Queue 代表先进先出(FIFO)的队列;Map 代表具有映射关系(key-value)的集合。
这些接口拥有众多的实现类,其中最常用的实现类有HashSet、TreeSet、ArrayList、LinkedList、ArrayDeque、HashMap、TreeMap等。
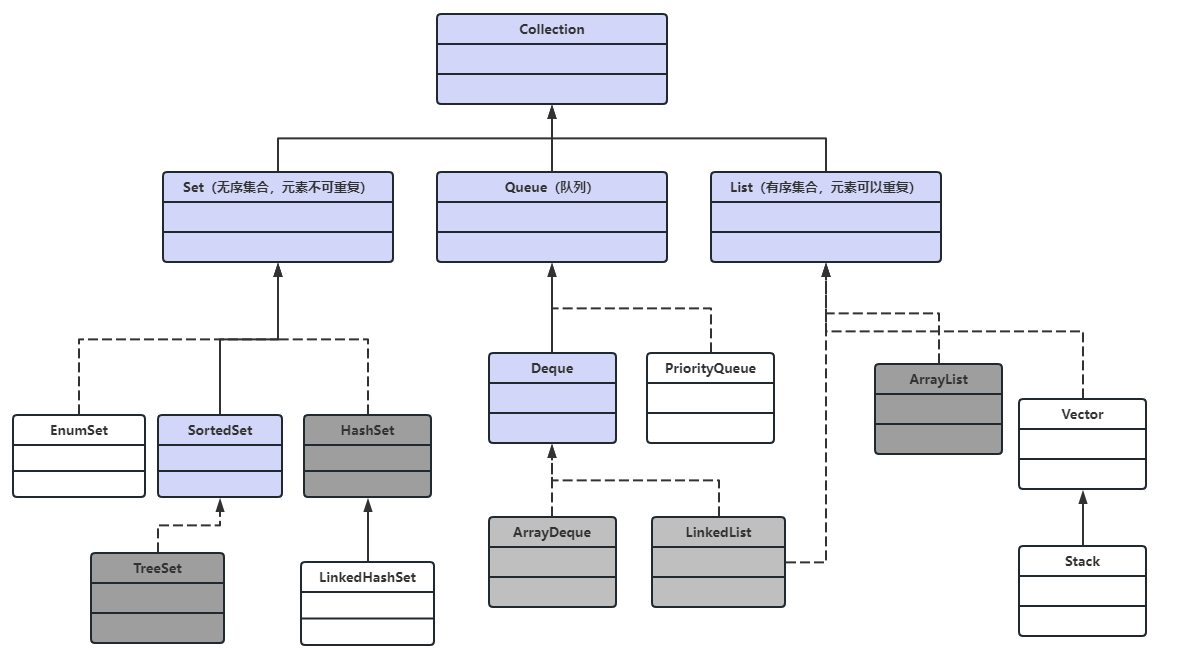
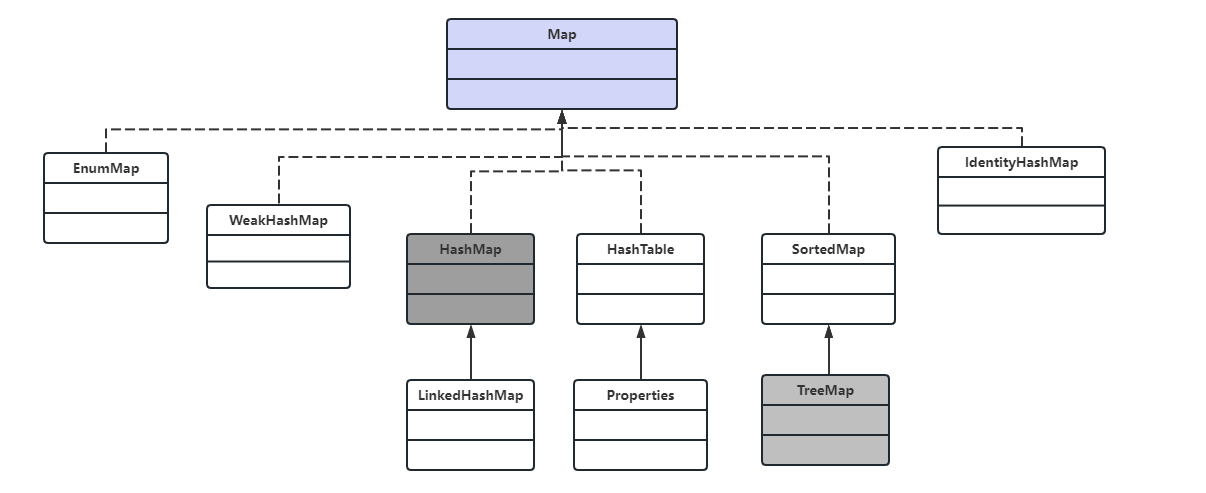
注:紫色框体代表接口,白色框体代表实现类,其中带有灰色的是常用实现类。
追问:Java中的容器,线程安全和线程不安全的分别有哪些?
java.util 包下的集合类大部分都是线程不安全的,例如我们常用的「HashSet、TreeSet、ArrayList、LinkedList、ArrayDeque、HashMap、TreeMap」这些都是线程不安全的集合类,但是它们的优点是性能好。如果需要使用线程安全的集合类,则可以使用「Collections 工具类提供的 synchronizedXxx()」方法,将这些集合类包装成线程安全的集合类。
java.util 包下也有线程安全的集合类,例如 Vector、Hashtable。这些集合类都是比较古老的 API,虽然实现了线程安全,但是性能很差。所以即便是需要使用线程安全的集合类,也建议将线程不安全的集合类包装成线程安全集合类的方式,而不是直接使用这些古老的 API。
从 Java5 开始,Java 在 java.util.concurrent 包下提供了大量支持高效并发访问的集合类,它们既能包装良好的访问性能,有能包装线程安全。这些集合类可以分为两部分,它们的特征如下:
- 以 Concurrent 开头的集合类:以 Concurrent 开头的集合类代表了支持并发访问的集合,它们可以支持多个线程并发写入访问,这些写入线程的所有操作都是线程安全的,但读取操作不必锁定。以 Concurrent 开头的集合类采用了更复杂的算法来保证永远不会锁住整个集合,因此在并发写入时有较好的性能。
- 以 CopyOnWrite 开头的集合类:以 CopyOnWrite 开头的集合类采用复制底层数组的方式来实现写操作。当线程对此类集合执行读取操作时,线程将会直接读取集合本身,无须加锁与阻塞。当线程对此类集合执行写入操作时,集合会在底层复制一份新的数组,接下来对新的数组执行写入操作。由于对集合的写入操作都是对数组的副本执行操作,因此它是线程安全的。
面试题二: HashMap 的实现原理/底层数据结构? JDK1.7 和 JDK1.8
JDK1.7: Entry数组 + 链表
JDK1.8: Node 数组 + 链表/红黑树,当链表上的元素个数超过「8」个并且数组长度「>= 64」时自动转化成红黑树,节点变成树节点,以提高搜索效率和插入效率到 O(logN)。
Entry 和 Node 都包含 key、 value、 hash、 next 属性。
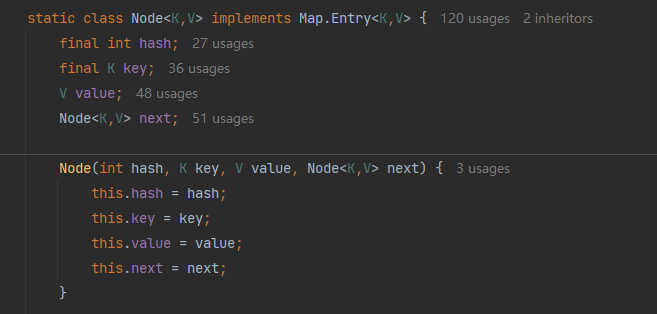
追问一:当new一个HashMap的时候,会发生什么吗?
HashMap 有几个构造方法,但最主要的就是指定初始值大小和负载因子的大小。如果我们不指定,默认HashMap的大小为16,负载因子的大小为0.75。
HashMap 的大小只能是「2次幂」的,假设你传一个 10 进去,实际上最终 HashMap 的大小是 16,你传一个 7 进去,HashMap 最终的大小是 8 ,具体的实现在「tableSizeFor」可以看到。

我们把元素放进 HashMap 的时候,需要算出这个元素所在的位置(hash),在 HashMap 里用的是位运算来代替取模,能够更加高效地算出该元素所在的位置。为什么 HashMap 的大小只能是 2 次幂,因为只有大小为 2 次幂时,才能合理用位运算替代取模。
负载因子的大小决定着哈希表的扩容和哈希冲突。
比如现在 我默认的 HashMap 大小为 16,负载因子为 0.75,这意味着数组最多只能放 12 个元素,一旦超过 12 个元素,则哈希表需要扩容。怎么算出是 12 呢?很简单,就是「16*0.75」。每次 put 元素进去的时候,都会检查HashMap 的大小有没有超过这个阈值,如果有,则需要扩容。
鉴于上面的说法(HashMap 的大小只能是 2 次幂),所以扩容的时候时候默认是扩原来的 2 倍。扩容这个操作肯定是耗时的,那能不能把负载因子调高一点,比如我要调至为 1,那我的 HashMap 就等到 16 个元素的时候才扩容呢。是可以的,但是不推荐。负载因子调高了,这意味着哈希冲突的概率会增高,哈希冲突概率增高,同样会耗时(因为查找的速度变慢了) 。
追问二:描述一下 Map put 的过程
直接看这个->> 画了一张图,简单描述了一下 HashMap 的 put 方法的执行过程
追问三: JDK 7和 JDK 8中的 HashMap 有什么区别?
JDK7 中的 HashMap ,是基于「数组+链表」来实现的,它的底层维护一个「Entry数组」。它会根据计算的hashCode 将对应的「KV键值对」存储到该数组中,一旦发生 hashCode 冲突,那么就会将该 KV 键值对放到对应的已有元素的后面, 此时便形成了一个链表式的存储结构。
JDK7 中 HashMap 的实现方案有一个明显的缺点,即当 Hash 冲突严重时,在桶上形成的链表会变得越来越长,这样在查询时的效率就会越来越低,其时间复杂度为O(N)。
JDK8 中的 HashMap,是基于「数组+链表+红黑树」来实现的,它的底层维护一个「Node」数组。当链表的存储的数据个数大于等于 8 的时候,不再采用链表存储,而采用了红黑树存储结构。这么做主要是在查询的时间复杂度上进行优化,链表为O(N),而红黑树一直是O(logN),可以大大的提高查找性能。
面试题三:hash 碰撞是什么以及如何解决
直接看这个->> 大白话解释hash碰撞是什么以及如何解决