郑州新感觉会所网站哪里做的百度网页游戏
场景
Pythont通过request以及BeautifulSoup爬取几千条情话:
Pythont通过request以及BeautifulSoup爬取几千条情话_爬取情话-CSDN博客
Node-RED中使用html节点爬取HTML网页资料之爬取Node-RED的最新版本:
Node-RED中使用html节点爬取HTML网页资料之爬取Node-RED的最新版本_node-red html-CSDN博客
Jsoup
Jsoup是一种Java 的HTML(html也是XML文档)解析器,可直接解析某个URL地址、HTML文本内容。
它提供了一套易于操作的API,可通过DOM,CSS以及类似于jQuery选择器的操作方法来取出和操作数据。
使用jsoup就可以解析HTML。
Jsoup使用的是DOM解析方式,把整个HTML文档(XML文档)加载到内存中形成一棵DOM树,得到文档的Document对象。
HTML里的标签,会转换成Element对象。
官网地址:
jsoup: Java HTML parser, built for HTML editing, cleaning, scraping, and XSS safety
EasyExcel
Java解析、生成Excel比较有名的框架有Apache poi、jxl。但他们都存在一个严重的问题就是非常的耗内存,
poi有一套SAX模式的API可以一定程度的解决一些内存溢出的问题,但POI还是有一些缺陷,
比如07版Excel解压缩以及解压后存储都是在内存中完成的,内存消耗依然很大。
easyexcel重写了poi对07版Excel的解析,一个3M的excel用POI sax解析依然需要100M左右内存,
改用easyexcel可以降低到几M,并且再大的excel也不会出现内存溢出;03版依赖POI的sax模式,
在上层做了模型转换的封装,让使用者更加简单方便。
官网地址:
关于Easyexcel | Easy Excel
注:
博客:
https://blog.csdn.net/badao_liumang_qizhi
实现
1、引入依赖
<!--Jsoup 是一个用于解析HTML和XML文档的Java库--><dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.11.3</version></dependency><!--EasyExcel是一个基于Java的、快速、简洁、解决大文件内存溢出的Excel处理工具--><dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifactId><version>3.0.5</version></dependency>2、找到需要爬取的网页内容
比如以下面为例
2023财富世界500强企业榜单 2023全球500强企业 世界500强排名一览表→买购网
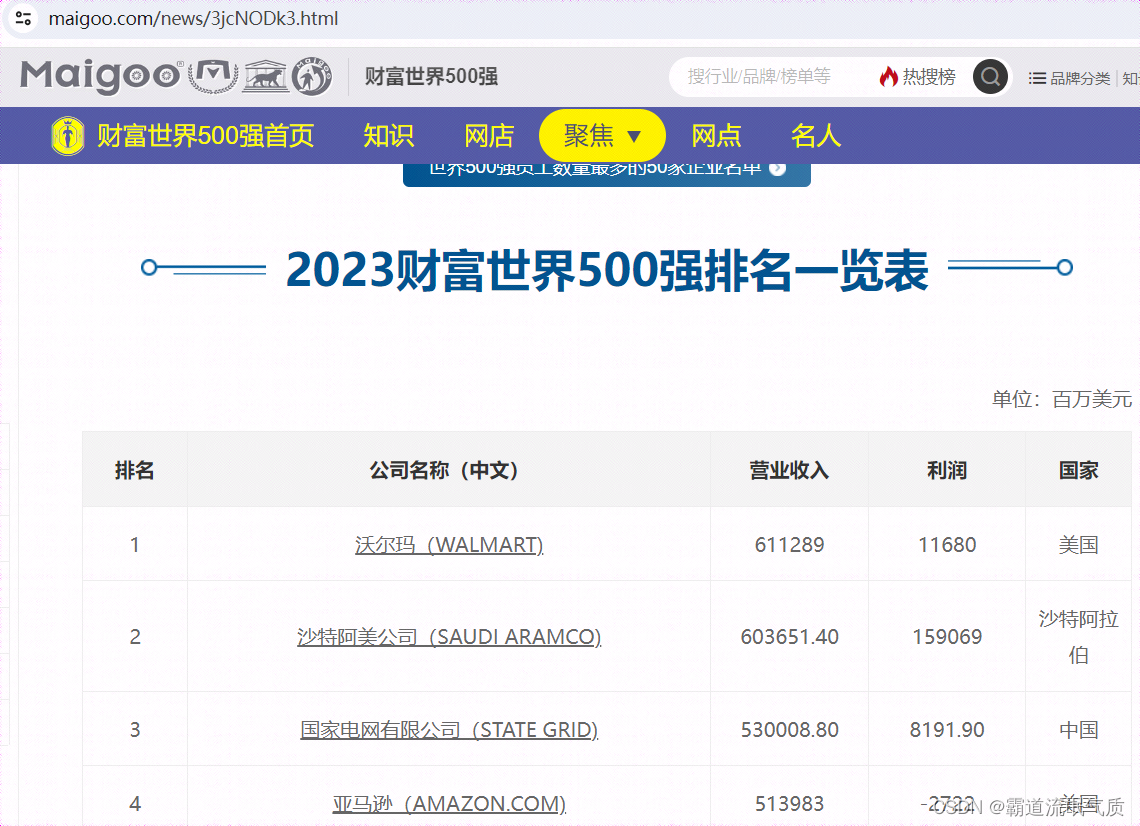
这里要获取500强排名数据,因为单次刷新网页只能返回100条数据,所以只解析前100条。获取更多数据可根据其分页请求规则分别进行爬取。
打开F12找到要爬取的数据的dom结构
这里要获取到id为t_container的div元素大的第22个子元素(索引为21)的table元素的tr元素的td数据。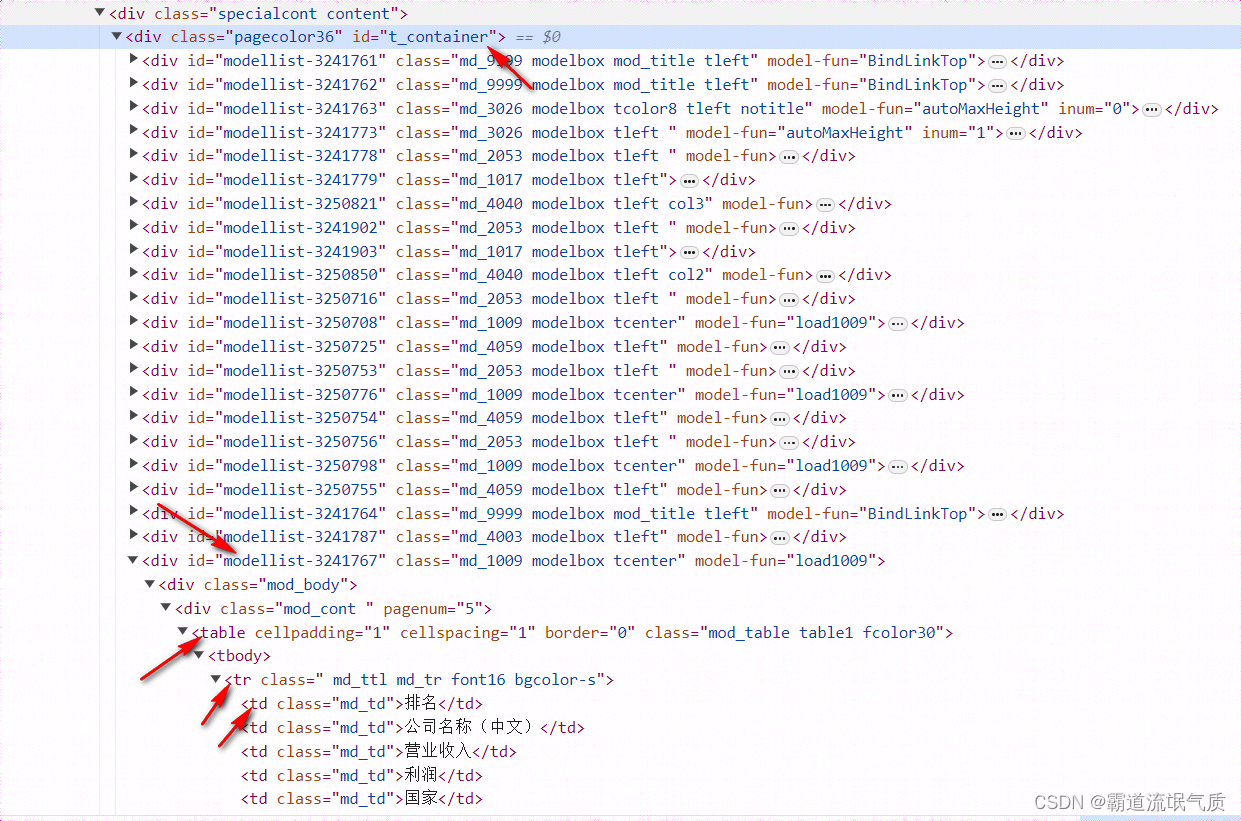
3、编写测试代码,连接并解析html元素
String url = "https://www.maigoo.com/news/3jcNODk3.html";try {//读取url,得到DocumentDocument document = Jsoup.connect(url).ignoreContentType(true).userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3").timeout(30000).header("referer","https://www.maigoo.com").get();Elements select = document.select("#t_container > div:eq(21) table tr");} catch (IOException e) {e.printStackTrace();}注意这里使用选择器的语法:
#t_container 代表id为t_container
>代表找父元素下的子元素
div:eq(21) 代表第22个元素
table tr 代表table 标签下tr标签
更多select选择器用法
Use CSS selectors to find elements: jsoup Java HTML parser
Selector overview
tagname: find elements by tag, e.g.div#id: find elements by ID, e.g.#logo.class: find elements by class name, e.g..masthead[attribute]: elements with attribute, e.g.[href][^attrPrefix]: elements with an attribute name prefix, e.g.[^data-]finds elements with HTML5 dataset attributes[attr=value]: elements with attribute value, e.g.[width=500](also quotable, like[data-name='launch sequence'])[attr^=value],[attr$=value],[attr*=value]: elements with attributes that start with, end with, or contain the value, e.g.[href*=/path/][attr~=regex]: elements with attribute values that match the regular expression; e.g.img[src~=(?i)\.(png|jpe?g)]*: all elements, e.g.*ns|tag: find elements by tag in a namespace prefix, e.g.fb|namefinds<fb:name>elements*|tag: final elements by tag in any namespace prefix, e.g.*|namefinds<fb:name>and<name>elements
Selector combinations
el#id: elements with ID, e.g.div#logoel.class: elements with class, e.g.div.mastheadel[attr]: elements with attribute, e.g.a[href]- Any combination, e.g.
a[href].highlight ancestor child: child elements that descend from ancestor, e.g..body pfindspelements anywhere under a block with class "body"parent > child: child elements that descend directly from parent, e.g.div.content > pfindspelements; andbody > *finds the direct children of the body tagsiblingA + siblingB: finds sibling B element immediately preceded by sibling A, e.g.div.head + divsiblingA ~ siblingX: finds sibling X element preceded by sibling A, e.g.h1 ~ pel, el, el: group multiple selectors, find unique elements that match any of the selectors; e.g.div.masthead, div.logo
Pseudo selectors
:has(selector): find elements that contain elements matching the selector; e.g.div:has(p):is(selector): find elements that match any of the selectors in the selector list; e.g.:is(h1, h2, h3, h4, h5, h6)finds any heading element:not(selector): find elements that do not match the selector; e.g.div:not(.logo):contains(text): find elements that contain the given text. The search is case-insensitive; e.g.p:contains(jsoup):containsOwn(text): find elements that directly contain the given text:matches(regex): find elements whose text matches the specified regular expression; e.g.div:matches((?i)login):matchesOwn(regex): find elements whose own text matches the specified regular expression:lt(n): find elements whose sibling index (i.e. its position in the DOM tree relative to its parent) is less thann; e.g.td:lt(3):gt(n): find elements whose sibling index is greater thann; e.g.div p:gt(2):eq(n): find elements whose sibling index is equal ton; e.g.form input:eq(1)- Note that the above indexed pseudo-selectors are 0-based, that is, the first element is at index 0, the second at 1, etc
除使用select选择器之外还可使用XPath选择器用法
Use XPath selectors to find elements and nodes: jsoup Java HTML parser
4、解析dom数据并赋值到对象添加到list
新建实体对象,并添加excel注解
import com.alibaba.excel.annotation.ExcelProperty;
import lombok.Builder;
import lombok.Data;import java.io.Serializable;@Data
@Builder
public class WealthEntity implements Serializable {private static final long serialVersionUID = -1760099890427975758L;@ExcelProperty(value = "排名",index = 0)private Integer index;@ExcelProperty(value = "公司名称",index = 1)private String companyName;@ExcelProperty(value = "收入",index = 2)private String income;@ExcelProperty(value = "利润",index = 3)private String profit;}进行dom解析和添加到list
Elements select = document.select("#t_container > div:eq(21) table tr");List<WealthEntity> list = new ArrayList<>();for (int i = 1; i < select.size(); i++) {Element tr = select.get(i);Elements tds = tr.select("td");Integer index = Integer.valueOf(tds.get(0).text());String companyName = tds.get(1).text();String income = tds.get(2).text();String profit = tds.get(3).text();WealthEntity wealthEntity = WealthEntity.builder().index(index).companyName(companyName).income(income).profit(profit).build();list.add(wealthEntity);}5、导出为excel
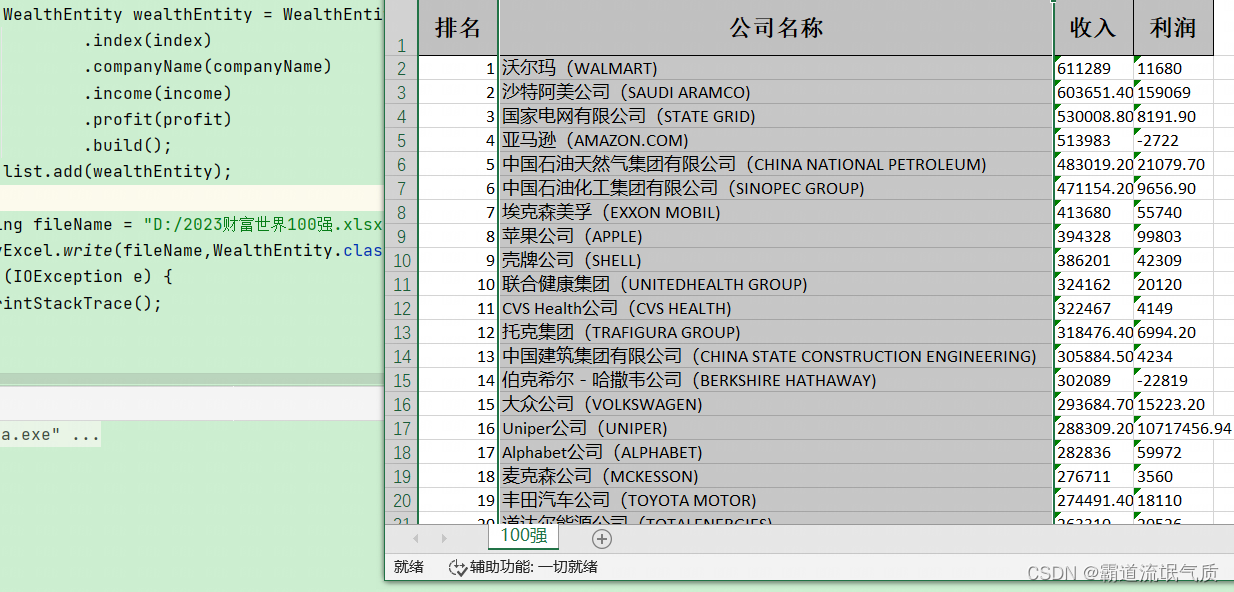
String fileName = "D:/2023财富世界100强.xlsx";EasyExcel.write(fileName,WealthEntity.class).sheet("100强").doWrite(list);6、完整示例代码
String url = "https://www.maigoo.com/news/3jcNODk3.html";try {//读取url,得到DocumentDocument document = Jsoup.connect(url).ignoreContentType(true).userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3").timeout(30000).header("referer","https://www.maigoo.com").get();Elements select = document.select("#t_container > div:eq(21) table tr");List<WealthEntity> list = new ArrayList<>();for (int i = 1; i < select.size(); i++) {Element tr = select.get(i);Elements tds = tr.select("td");Integer index = Integer.valueOf(tds.get(0).text());String companyName = tds.get(1).text();String income = tds.get(2).text();String profit = tds.get(3).text();WealthEntity wealthEntity = WealthEntity.builder().index(index).companyName(companyName).income(income).profit(profit).build();list.add(wealthEntity);}String fileName = "D:/2023财富世界100强.xlsx";EasyExcel.write(fileName,WealthEntity.class).sheet("100强").doWrite(list);} catch (IOException e) {e.printStackTrace();}7、运行结果