北京专业网页制作公司长沙网站优化对策
模型介绍
LSTM:长短期记忆网络(Long-short-term-memory),能够记住长句子的前后信息,解决了RNN的问题(时间间隔较大时,网络对前面的信息会遗忘,从而出现梯度消失问题,会形成长期依赖问题),避免长期依赖问题。
Bi-LSTM:由前向LSTM与后向LSTM组合而成。
模型结构
Bi-LSTM
同LSTM,区别在于模型的输出和结构上不同,如下图:

一共有两个LSTM网络,一个网络从一句话的首段进行学习,另一个网络从一句话的末端进行学习。
相关详情请看nlp系列(5)文本实体识别(LSTM)pytorch 中模型详解
CRF
CRF(条件随机场):是一个判别模型,用于解决标注偏差问题,使用P(Y|X)建模,为全局归一化
适用领域:词性标注、分词、命名实体识别等
以命名实体为例:

损失计算:
lg P ( Y ∣ X ) = − l g e s ( X , Y ) ∑ y ‾ ϵ Y x e s ( X , y ‾ ) = − S ( X , y ) + lg ∑ y ‾ ϵ Y x e s ( X , y ‾ ) \lg P(Y|X) = -lg \frac{e^s(X,Y)}{\sum_{\overline{y}\epsilon Y_x}{e^s(X,\overline y)}} = - S(X, y) + \lg\sum_{\overline{y}\epsilon Y_x}{e^s(X,\overline y)} lgP(Y∣X)=−lg∑yϵYxes(X,y)es(X,Y)=−S(X,y)+lgyϵYx∑es(X,y)
推荐一个视频讲解,全程手写推导,讲得很细
机器学习-白板推导系列(十七)-条件随机场CRF(Conditional Random Field)
数据介绍
数据集用的是论文【ACL 2018Chinese NER using Lattice LSTM】中从新浪财经收集的简历数据。每一句话用换行进行隔开。
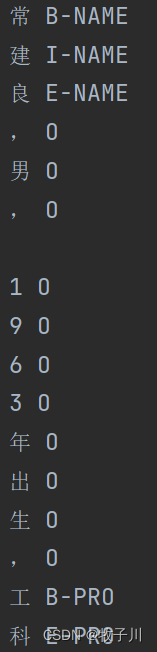


图2 数据样式
模型准备
方法一:使用ptorch库自带的CRF库,其CRF库关键函数介绍链接
def forward(self, sentence, tags=None, mask=None):# sentence=(batch, seq_len) tags=(batch, seq_len) masks=(batch, seq_len)# 1. 从 sentence 到 Embedding 层embeds = self.word_embeds(sentence).permute(1, 0, 2) # shape [seq_len, batch_size, embedding_size]# 2. 从 Embedding 层到 Bi-LSTM 层# Bi-lstm 层的隐藏节点设置# 隐藏层就是(h_0, c_0) num_directions = 2 if self.bidirectional else 1# h_0 的结构:(num_layers*num_directions, batch_size, hidden_size)self.hidden = (torch.randn(2, sentence.shape[0], self.hidden_dim // 2, device=self.device),torch.randn(2, sentence.shape[0], self.hidden_dim // 2, device=self.device))# input=(seq_length, batch_size, embedding_num)# output(lstm_out)=(seq_length, batch_size, num_directions * hidden_size)# h_0 = (num_layers*num_directions, batch_size, hidden_size)lstm_out, self.hidden = self.lstm(embeds, self.hidden)# 3. 从 Bi-LSTM 层到全连接层# 从 Bi-lstm 的输出转为 target_size 长度的向量组(即输出了每个 tag 的可能性)# 输出 shape=(seq_length, batch_size, len(tag_to_ix))lstm_feats = self.linear(lstm_out)# 4. 全连接层到 CRF 层if tags is not None:# 训练用if mask is not None:loss = -1. * self.crf(emissions=lstm_feats.permute(1, 0, 2), tags=tags, mask=mask, reduction='mean')# outputs=(batch_size,) 输出 log 形式的 likelihoodelse:loss = -1. * self.crf(emissions=lstm_feats.permute(1, 0, 2), tags=tags, reduction='mean')return losselse:# 测试if mask is not None:prediction = self.crf.decode(emissions=lstm_feats.permute(1, 0, 2), mask=mask)else:prediction = self.crf.decode(emissions=lstm_feats.permute(1, 0, 2))return prediction
方法2:编写CRF实现代码
def argmax(vec):"""返回 vec 中每一行最大的那个元素的下标"""# return the argmax as a python int_, idx = torch.max(vec, 1)# 获取该元素:tensor只有一个元素才能调用item方法return idx.item()def log_sum_exp(vec, device):"""vec 维度为 1*5Compute log sum exp in a numerically stable way for the forward algorithm前向算法是不断累积之前的结果,这样就会有个缺点指数和累积到一定程度后,会超过计算机浮点值的最大值,变成inf,这样取log后也是inf为了避免这种情况,用一个合适的值clip去提指数和的公因子,这样就不会使某项变得过大而无法计算计算一维向量 vec 与其最大值的 log_sum_exp"""max_score = vec[0, argmax(vec)] # max_score的维度为1max_score_broadcast = max_score.view(1, -1).expand(1, vec.size()[1]) # 维度为 1*5return max_score.to(device) + torch.log(torch.sum(torch.exp(vec - max_score_broadcast))).to(device)class BiLSTM_CRF(nn.Module):def __init__(self, vocab_size, tag_to_index, embedding_dim, hidden_dim):# 调用父类的initsuper(BiLSTM_CRF, self).__init__()self.embedding_dim = embedding_dim # word embedding dim 嵌入维度: 词向量维度self.hidden_dim = hidden_dim # Bi-LSTM hidden dim 隐藏层维度self.vocab_size = vocab_size # 词汇量大小self.tag_to_index = tag_to_index # 标签转下标的词典self.target_size = len(tag_to_index) # 输出维度:目标取值范围大小,标签预测类别数self.device = "cuda:0" if torch.cuda.is_available() else "cpu"''' Embedding 的用法A simple lookup table that stores embeddings of a fixed dictionary and size.This module is often used to store word embeddings and retrieve them using indices. The input to the module is a list of indices, and the output is the corresponding word embeddings.一个简单的查找表,用于存储固定字典和大小的嵌入。该模块通常用于存储词嵌入并使用索引检索它们。模块的输入是索引列表,输出是相应的词嵌入。requires_grad: 用于说明当前量是否需要在计算中保留对应的梯度信息'''self.word_embeds = nn.Embedding(vocab_size, embedding_dim)'''embedding_dim:特征维度hidden_dim:隐藏层层数num_layers:循环层数bidirectional:是否采用 Bi-LSTM(前向LSTM+反向LSTM)'''self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2, num_layers=1, bidirectional=True)# 将 Bi-LSTM 提取的特征向量映射到特征空间,即经过全连接得到发射分数self.hidden2tag = nn.Linear(hidden_dim, self.target_size)# 转移矩阵的参数初始化,transitions[i,j]代表的是从第j个tag转移到第i个tag的转移分数# 转移矩阵是随机的,在网络中会随着训练不断更新self.transitions = nn.Parameter(torch.randn(self.target_size, self.target_size))# 初始化所有其他 tag 转移到 START_TAG 的分数非常小,即不可能由其他 tag 转移到 START_TAG# 初始化 STOP_TAG 转移到所有其他 tag 的分数非常小,即不可能由 STOP_TAG 转移到其他 tag# 转移矩阵: 列标 转 行标# 规定:其他 tag 不能转向 start,stop 也不能转向其他 tagself.transitions.data[self.tag_to_index[START_TAG], :] = -10000 # 从任何标签转移到 START_TAG 不可能self.transitions.data[:, self.tag_to_index[STOP_TAG]] = -10000 # 从 STOP_TAG 转移到任何标签不可能# 初始化 hidden layerself.hidden = self.init_hidden()def init_hidden(self):# 初始化 Bi-LSTM 的参数 h_0, c_0return (torch.randn(2, 1, self.hidden_dim // 2).to(self.device),torch.randn(2, 1, self.hidden_dim // 2).to(self.device))def _get_lstm_features(self, sentence):# 通过 Bi-LSTM 提取特征self.hidden = self.init_hidden()embeds = self.word_embeds(sentence).view(len(sentence), 1, -1)'''默认参数意义:input_size,hidden_size,num_layershidden_size : LSTM在运行时里面的维度。隐藏层状态的维数,即隐藏层节点的个数torch里的LSTM单元接受的输入都必须是3维的张量(Tensors):第一维体现的每个句子的长度,即提供给LSTM神经元的每个句子的长度,如果是其他的带有带有序列形式的数据,则表示一个明确分割单位长度,第二维度体现的是batch_size,即每一次给网络句子条数第三维体现的是输入的元素,即每个具体的单词用多少维向量来表示'''lstm_out, self.hidden = self.lstm(embeds, self.hidden)lstm_out = lstm_out.view(len(sentence), self.hidden_dim)lstm_feats = self.hidden2tag(lstm_out)return lstm_featsdef _score_sentence(self, feats, tags):"""CRF 的输出,即 emit + transition scores"""# 计算给定 tag 序列的分数,即一条路径的分数score = torch.zeros(1).to(self.device)tags = torch.cat([torch.tensor([self.tag_to_index[START_TAG]], dtype=torch.long).to(self.device), tags])# 转移 + 前向for i, feat in enumerate(feats):# 递推计算路径分数:转移分数 + 发射分数score = score + self.transitions[tags[i + 1], tags[i]] + feat[tags[i + 1]]score = score + self.transitions[self.tag_to_index[STOP_TAG], tags[-1]]return scoredef _forward_alg(self, feats): # 预测序列的得分,就是 Loss 的右边第一项"""前向算法:feats 表示发射矩阵(emit score),是 Bi-LSTM 所有时间步的输出 意思是经过 Bi-LSTM 的 sentence 的每个 word 对应于每个 label 的得分"""# 通过前向算法递推计算 alpha 初始为 -10000init_alphas = torch.full((1, self.target_size), -10000.).to(self.device) # 用-10000.来填充一个形状为[1,target_size]的tensor# 初始化 step 0 即 START 位置的发射分数,START_TAG 取 0 其他位置取 -10000 start 位置的 alpha 为 0# 因为 start tag 是4,所以tensor([[-10000., -10000., -10000., 0., -10000.]]),# 将 start 的值为零,表示开始进行网络的传播,init_alphas[0][self.tag_to_index[START_TAG]] = 0.# 将初始化 START 位置为 0 的发射分数赋值给 previous 包装进变量,实现自动反向传播previous = init_alphas# 迭代整个句子for obs in feats:# The forward tensors at this timestep# 当前时间步的前向 tensoralphas_t = []for next_tag in range(self.target_size):# 取出当前tag的发射分数,与之前时间步的tag无关'''Bi-LSTM 生成的矩阵是 emit score[观测/发射概率], 即公式中的H()函数的输出CRF 是判别式模型emit score: Bi-LSTM 对序列中每个位置的对应标签打分的和transition score: 是该序列状态转移矩阵中对应的和Score = EmissionScore + TransitionScore'''# Bi-LSTM的生成矩阵是 emit_score,维度为 1*5emit_score = obs[next_tag].view(1, -1).expand(1, self.target_size).to(self.device)# 取出当前 tag 由之前 tag 转移过来的转移分数trans_score = self.transitions[next_tag].view(1, -1)# 当前路径的分数:之前时间步分数 + 转移分数 + 发射分数next_tag_var = previous.to(self.device) + trans_score.to(self.device) + emit_score.to(self.device)# 对当前分数取 log-sum-expalphas_t.append(log_sum_exp(next_tag_var, self.device).view(1))# 更新 previous 递推计算下一个时间步previous = torch.cat(alphas_t).view(1, -1)# 考虑最终转移到 STOP_TAGterminal_var = previous + self.transitions[self.tag_to_index[STOP_TAG]]# 计算最终的分数scores = log_sum_exp(terminal_var, self.device)return scores.to(self.device)def _viterbi_decode(self, feats):"""Decoding的意义:给定一个已知的观测序列,求其最有可能对应的状态序列"""# 预测序列的得分,维特比解码,输出得分与路径值backpointers = []# 初始化 viterbi 的 previous 变量init_vvars = torch.full((1, self.target_size), -10000.).cpu() # 这就保证了一定是从START到其他标签init_vvars[0][self.tag_to_index[START_TAG]] = 0# 第 i 步的 forward_var 保存第 i-1 步的维特比变量previous = init_vvarsfor obs in feats:# 保存当前时间步的回溯指针bptrs_t = []# 保存当前时间步的 viterbi 变量viterbivars_t = []for next_tag in range(self.target_size):# 其他标签(B,I,E,Start,End)到标签next_tag的概率# 维特比算法记录最优路径时只考虑上一步的分数以及上一步 tag 转移到当前 tag 的转移分数# 并不取决与当前 tag 的发射分数next_tag_var = previous.cpu() + self.transitions[next_tag].cpu() # previous 保存的是之前的最优路径的值# 找到此刻最好的状态转入点best_tag_id = argmax(next_tag_var) # 返回最大值对应的那个tag# 记录点bptrs_t.append(best_tag_id)viterbivars_t.append(next_tag_var[0][best_tag_id].view(1))# 更新 previous,加上当前 tag 的发射分数 obs# 从 step0 到 step(i-1) 时 5 个序列中每个序列的最大 scoreprevious = (torch.cat(viterbivars_t).cpu() + obs.cpu()).view(1, -1)# 回溯指针记录当前时间步各个 tag 来源前一步的 tagbackpointers.append(bptrs_t)# 考虑转移到 STOP_TAG 的转移分数# 其他标签到STOP_TAG的转移概率terminal_var = previous.cpu() + self.transitions[self.tag_to_index[STOP_TAG]].cpu()best_tag_id = argmax(terminal_var)path_score = terminal_var[0][best_tag_id]# 通过回溯指针解码出最优路径best_path = [best_tag_id]# best_tag_id 作为线头,反向遍历 backpointers 找到最优路径for bptrs_t in reversed(backpointers):best_tag_id = bptrs_t[best_tag_id]best_path.append(best_tag_id)# 去除 START_TAGstart = best_path.pop()assert start == self.tag_to_index[START_TAG] # Sanity checkbest_path.reverse() # 把从后向前的路径正过来return path_score, best_pathdef neg_log_likelihood(self, sentence, tags):# CRF 损失函数由两部分组成,真实路径的分数和所有路径的总分数。# 真实路径的分数应该是所有路径中分数最高的。# log 真实路径的分数/log所有可能路径的分数,越大越好,构造 crf loss 函数取反,loss 越小越好feats = self._get_lstm_features(sentence) # 经过LSTM+Linear后的输出作为CRF的输入# 前向算法分数forward_score = self._forward_alg(feats) # loss的log部分的结果# 真实分数gold_score = self._score_sentence(feats, tags) # loss的后半部分S(X,y)的结果# log P(y|x) = forward_score - gold_scorereturn forward_score - gold_score# 这里 Bi-LSTM 和 CRF 共同前向输出def forward(self, sentence):"""重写原 module 里的 forward"""sentence = sentence.reshape(-1)# 通过 Bi-LSTM 提取发射分数lstm_feats = self._get_lstm_features(sentence)# 根据发射分数以及转移分数,通过 viterbi 解码找到一条最优路径score, tag_seq = self._viterbi_decode(lstm_feats)return score, tag_seq
模型预测
注:模型只训练了一轮,预测结果与实际会有差异。
方法一:


源码获取
Bi-LSTM-CRF 实体识别
硬性的标准其实限制不了无限可能的我们,所以啊!少年们加油吧!