思途智旅游网站开发代做百度关键词排名
二、网络爬虫设计
- 网络爬虫原理
网络爬虫是一种自动化程序,用于从互联网上获取数据。其工作原理可以分为以下几个步骤:
定义起始点:网络爬虫首先需要定义一个或多个起始点(URL),从这些起始点开始抓取数据。
发送HTTP请求:爬虫使用HTTP协议向目标网站发送请求,获取网页内容。通常使用GET请求来获取页面的HTML代码。
获取网页内容:当网站接收到请求后,会返回相应的网页内容。爬虫将接收到的响应解析为字符串形式,以便进一步处理。
解析网页:爬虫使用解析库(如BeautifulSoup、lxml等)对网页进行解析,提取所需的数据。解析过程涉及HTML结构分析、XPath或CSS选择器的使用,以定位和提取目标数据。
处理数据:爬虫对提取的数据进行清洗、去除噪声、转换格式等处理操作,以确保数据的质量和一致性。
存储数据:根据需求,爬虫可以将处理后的数据存储到数据库、文本文件、Excel表格或其他数据存储介质中。
跟踪链接:爬虫会根据预设规则或算法,从当前页面中提取其他链接,并将这些链接加入待抓取队列。这样,爬虫可以深入遍历网站的各个页面。
- 网络爬虫的程序架构及整体执行流程
1、网络爬虫程序框架
基于Python的网络爬虫的天气数据分析项目,以下是网络爬虫程序框架:
导入所需的模块和库:导入了requests、csv和BeautifulSoup等库,以便进行HTTP请求、CSV文件操作和HTML解析。
设置请求头信息:定义了headers字典,包含了User-Agent信息,用于伪装浏览器发送请求。
定义城市列表和日期范围:给定了一个城市列表list1,其中每个元素包含了城市名称和对应的区域ID。同时,通过循环遍历1到12的范围,获取每个月的数据。
发送HTTP请求并解析响应:通过构建URL,发送HTTP GET请求获取天气数据的JSON响应。然后使用json()方法将响应内容解析为Python对象。
解析网页内容:使用BeautifulSoup库将响应内容转换为BeautifulSoup对象,以便提取数据。通过使用HTML标签和属性进行定位,使用find_all()方法获取每一行(tr标签)的数据。
提取数据并写入CSV文件:在每一行中,使用find_all('td')方法获取每列的数据,并提取日期、最高温度、最低温度、天气、风力风向和空气质量指数。然后将这些数据存储在列表list0中。
异常处理:使用try-except语句捕获可能出现的异常,并跳过处理。网络爬虫程序架构如图1所示。
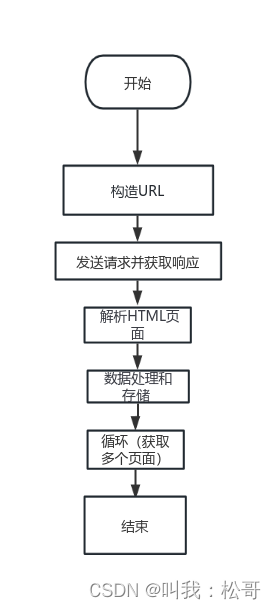
2、网络爬虫的整体流程
- 获取初始URL;
- 发送请求并获取响应;
- 解析HTML页面;
- 数据处理和存储;
- 分析是否满足停止条件,并进入下一个循环。
网络爬虫的整体流程图如图2所示。
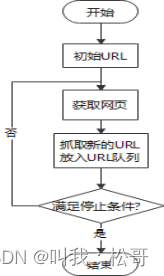
图2 网络爬虫的整体流程图
- 网络爬虫相关技术
- 数据爬取
使用requests库发送HTTP请求,并使用headers伪装浏览器标识。程序遍历城市列表和月份范围,构建URL并发送请求获取天气数据的JSON响应。然后,使用BeautifulSoup库解析响应内容,并使用HTML标签和属性定位数据。爬虫提取日期、最高温度、最低温度、天气、风力风向和空气质量指数等数据。最后,通过将数据写入CSV文件,实现数据的存储和持久化。这个爬虫程序使用了多个库和模块,通过编写合适的代码逻辑,实现了从目标网站上爬取天气数据的功能。
- 数据解析
数据解析部分使用了BeautifulSoup库对爬取到的网页内容进行解析。首先,将响应内容传递给BeautifulSoup构造函数,并指定解析器为'lxml'。然后,通过调用find_all()方法定位目标数据的HTML元素,使用索引和属性获取具体的数据值。在这个程序中,使用find_all('td')获取每一行的所有列数据,并通过索引提取日期、最高温度、最低温度、天气、风力风向和空气质量指数等信息。解析得到的数据存储在相应的变量中,然后可以进一步处理或写入CSV文件。通过使用BeautifulSoup库的强大功能,程序能够有效地从HTML页面中提取出所需的数据,并进行后续的处理和分析。
- 数据存储
文本文件:将数据以文本文件的形式进行存储,例如使用CSV(逗号分隔值)或JSON(JavaScript对象表示)格式。这种方法简单直接,适合存储结构化的数据。
- 反爬虫
User-Agent检测:网站可能会检查HTTP请求中的User-Agent字段,如果发现与普通浏览器的User-Agent不匹配,则可能被视为爬虫并拒绝访问。所以想要设User-Agent模拟浏览器。
请求频率限制:网站可以设置对于同一IP地址或同一用户的请求频率进行限制,如果超过限制,则可能被视为爬虫并暂时禁止访问。需要设置睡眠时间,降低采集频率。