在百度上做网站多少钱广州谷歌seo
下面是一个完整的示例,其中包括了merge_tables_to_excel函数的定义,并且假设该函数的功能是从每个PDF文件中提取第一个表格并将其合并到一个Excel文件中:
import os
from pathlib import Path
import pandas as pd
import pdfplumber def extract_first_table_from_pdf(pdf_path): try: with pdfplumber.open(pdf_path) as pdf: for page in pdf.pages: tables = page.extract_tables() if tables: # tables[0] pdf中的第一个表格,如果pdf有第二个表格你可以修改为tables[1] 根据你需求来调整return tables[0] except Exception as e: print(f"Error reading {pdf_path}: {e}") return None def merge_tables_to_excel(pdf_files, excel_path): all_tables = [] for pdf_path in pdf_files: first_table = extract_first_table_from_pdf(pdf_path) if first_table: df_table = pd.DataFrame(first_table[1:], columns=first_table[0]) all_tables.append(df_table) if all_tables: merged_tables_df = pd.concat(all_tables, ignore_index=True) merged_tables_df.to_excel(excel_path, sheet_name='Merged Tables', index=False) print(f"Tables have been saved to {excel_path}") else: print("No tables found in the PDF files.") def find_all_pdf_files(directory): return list(Path(directory).glob("*.pdf")) if __name__ == "__main__": # 指定PDF文件夹路径 pdf_folder = Path("refer") # 获取文件夹中所有的PDF文件 pdf_files = find_all_pdf_files(pdf_folder) # 打印找到的PDF文件列表 print("Found PDF files:", [str(file) for file in pdf_files]) # 指定要保存的Excel文件路径 excel_path = "merged_tables.xlsx" # 提取并合并表格数据到Excel文件 merge_tables_to_excel(pdf_files, excel_path)
运行结果如图所示:
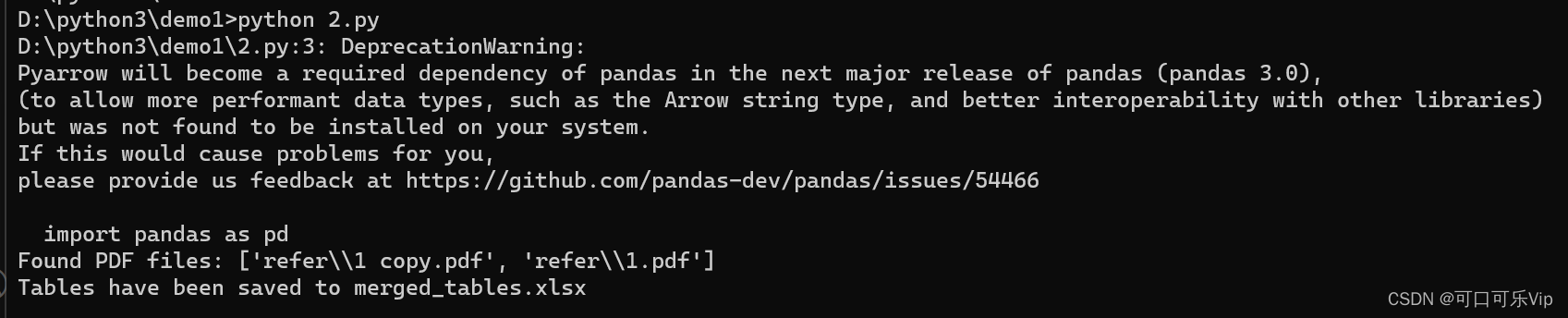
如果你想要遍历一个文件夹中的所有子文件夹,并获取每个子文件夹中的PDF文件,你可以使用递归函数来实现这个功能。下面是一个修改后的代码示例,它会递归地搜索指定目录及其所有子目录中的PDF文件:
import os
from pathlib import Path def find_all_pdf_files(directory): pdf_files = [] for root, dirs, files in os.walk(directory): for file in files: if file.lower().endswith('.pdf'): pdf_files.append(Path(root) / file) return pdf_files if __name__ == "__main__": # 指定PDF文件夹路径 pdf_folder = Path("refer") # 获取文件夹中所有的PDF文件,包括子文件夹中的PDF文件 pdf_files = find_all_pdf_files(pdf_folder) # 打印找到的PDF文件列表 print("Found PDF files:", [str(file) for file in pdf_files]) # 指定要保存的Excel文件路径 excel_path = "merged_tables.xlsx" # 提取并合并表格数据到Excel文件 merge_tables_to_excel(pdf_files, excel_path)
在这个示例中,find_all_pdf_files 函数使用 os.walk() 来递归遍历目录和子目录。os.walk() 会为每个目录返回一个三元组,包含当前目录的路径、当前目录下的子目录名列表,以及当前目录下的文件名列表。函数遍历每个文件名,检查它是否以 .pdf 结尾(不区分大小写),如果是,则将其添加到 pdf_files 列表中。
请确保你的 merge_tables_to_excel 函数能够处理多个PDF文件中的表格合并到Excel文件的逻辑。如果你需要更具体的帮助来定义这个函数,请提供更多关于你希望如何合并表格的信息。